 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFraudNet: A Multimodal Network to Detect Fraud in the Auto Insurance Industry
Jan 15, 2023In the insurance industry detecting fraudulent claims is a critical task with a significant financial impact. A common strategy to identify fraudulent claims is looking for inconsistencies in the supporting evidence. However, this is a laborious and cognitively heavy task for human experts as insurance claims typically come with a plethora of data from different modalities (e.g. images, text and metadata). To overcome this challenge, the research community has focused on multimodal machine learning frameworks that can efficiently reason through multiple data sources. Despite recent advances in multimodal learning, these frameworks still suffer from (i) challenges of joint-training caused by the different characteristics of different modalities and (ii) overfitting tendencies due to high model complexity. In this work, we address these challenges by introducing a multimodal reasoning framework, AutoFraudNet (Automobile Insurance Fraud Detection Network), for detecting fraudulent auto-insurance claims. AutoFraudNet utilizes a cascaded slow fusion framework and state-of-the-art fusion block, BLOCK Tucker, to alleviate the challenges of joint-training. Furthermore, it incorporates a light-weight architectural design along with additional losses to prevent overfitting. Through extensive experiments conducted on a real-world dataset, we demonstrate: (i) the merits of multimodal approaches, when compared to unimodal and bimodal methods, and (ii) the effectiveness of AutoFraudNet in fusing various modalities to boost performance (over 3\% in PR AUC).
Detecting rare visual relations using analogies
Dec 13, 2018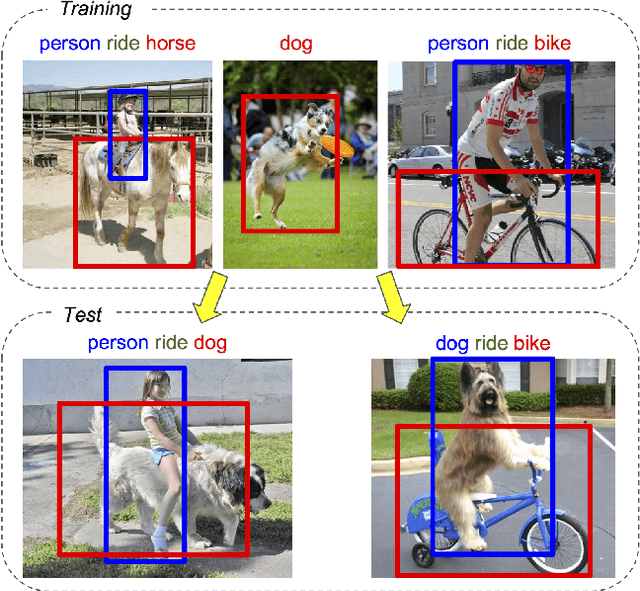
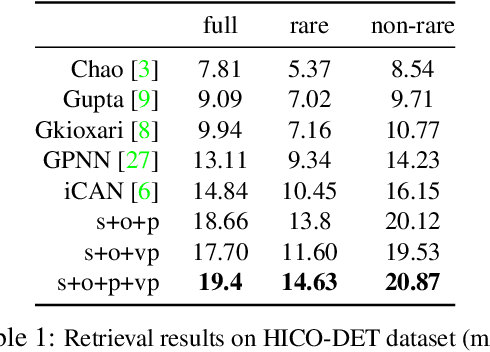
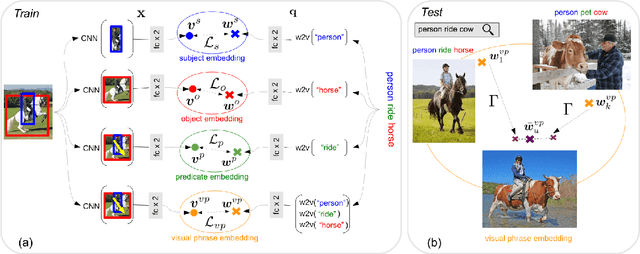

We seek to detect visual relations in images of the form of triplets t = (subject, predicate, object), such as "person riding dog", where training examples of the individual entities are available but their combinations are rare or unseen at training. This is an important set-up due to the combinatorial nature of visual relations : collecting sufficient training data for all possible triplets would be very hard. The contributions of this work are three-fold. First, we learn a representation of visual relations that combines (i) individual embeddings for subject, object and predicate together with (ii) a visual phrase embedding that represents the relation triplet. Second, we learn how to transfer visual phrase embeddings from existing training triplets to unseen test triplets using analogies between relations that involve similar objects. Third, we demonstrate the benefits of our approach on two challenging datasets involving rare and unseen relations : on HICO-DET, our model achieves significant improvement over a strong baseline, and we confirm this improvement on retrieval of unseen triplets on the UnRel rare relation dataset.
Weakly-supervised learning of visual relations
Jul 29, 2017
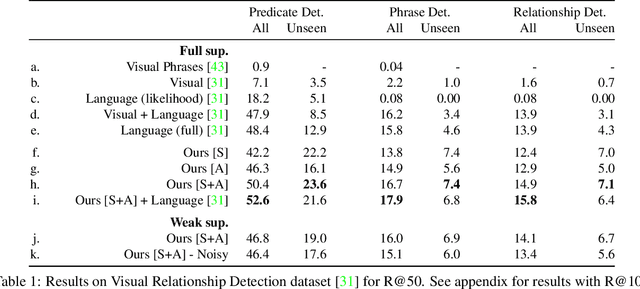
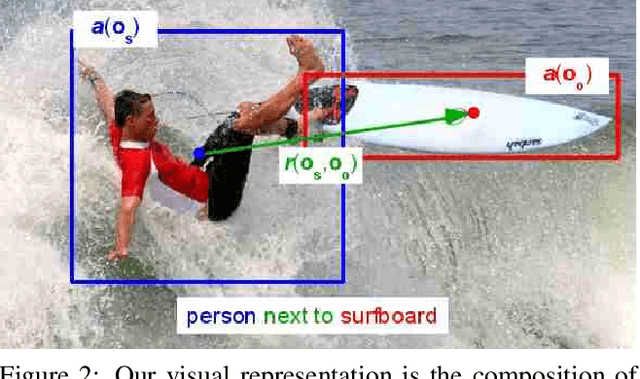
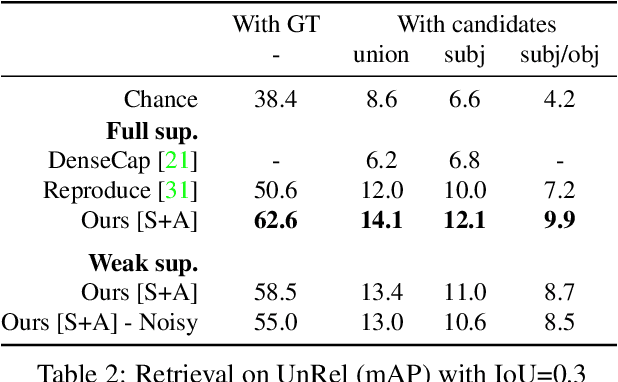
This paper introduces a novel approach for modeling visual relations between pairs of objects. We call relation a triplet of the form (subject, predicate, object) where the predicate is typically a preposition (eg. 'under', 'in front of') or a verb ('hold', 'ride') that links a pair of objects (subject, object). Learning such relations is challenging as the objects have different spatial configurations and appearances depending on the relation in which they occur. Another major challenge comes from the difficulty to get annotations, especially at box-level, for all possible triplets, which makes both learning and evaluation difficult. The contributions of this paper are threefold. First, we design strong yet flexible visual features that encode the appearance and spatial configuration for pairs of objects. Second, we propose a weakly-supervised discriminative clustering model to learn relations from image-level labels only. Third we introduce a new challenging dataset of unusual relations (UnRel) together with an exhaustive annotation, that enables accurate evaluation of visual relation retrieval. We show experimentally that our model results in state-of-the-art results on the visual relationship dataset significantly improving performance on previously unseen relations (zero-shot learning), and confirm this observation on our newly introduced UnRel dataset.