 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Model Performance through Differentially Private Model Aggregation
Dec 04, 2018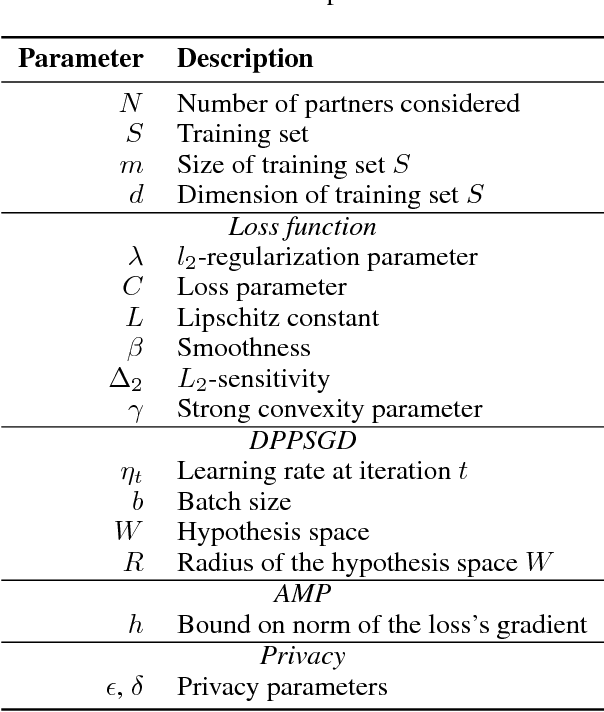



A key factor in developing high performing machine learning models is the availability of sufficiently large datasets. This work is motivated by applications arising in Software as a Service (SaaS) companies where there exist numerous similar yet disjoint datasets from multiple client companies. To overcome the challenges of insufficient data without explicitly aggregating the clients' datasets due to privacy concerns, one solution is to collect more data for each individual client, another is to privately aggregate information from models trained on each client's data. In this work, two approaches for private model aggregation are proposed that enable the transfer of knowledge from existing models trained on other companies' datasets to a new company with limited labeled data while protecting each client company's underlying individual sensitive information. The two proposed approaches are based on state-of-the-art private learning algorithms: Differentially Private Permutation-based Stochastic Gradient Descent and Approximate Minima Perturbation. We empirically show that by leveraging differentially private techniques, we can enable private model aggregation and augment data utility while providing provable mathematical guarantees on privacy. The proposed methods thus provide significant business value for SaaS companies and their clients, specifically as a solution for the cold-start problem.
A Hybrid Instance-based Transfer Learning Method
Dec 03, 2018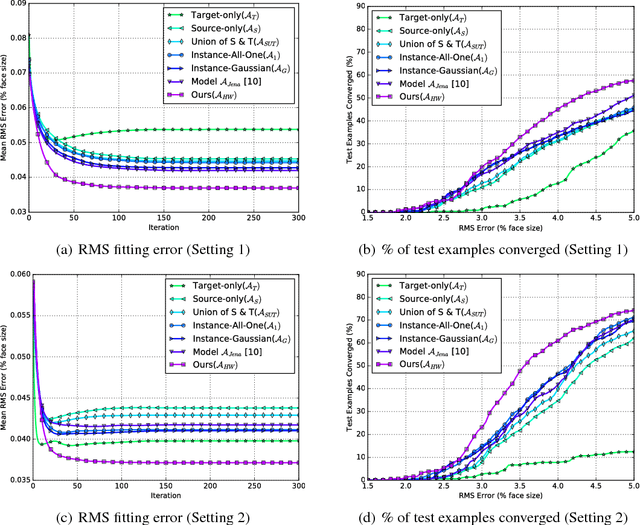
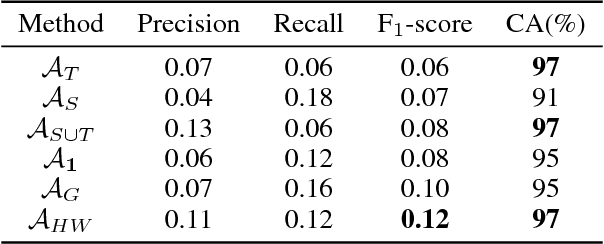
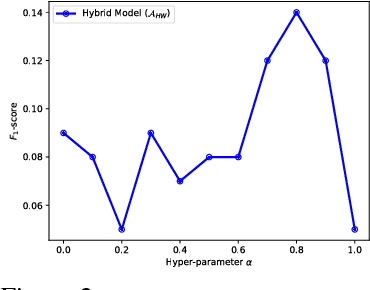

In recent years, supervised machine learning models have demonstrated tremendous success in a variety of application domains. Despite the promising results, these successful models are data hungry and their performance relies heavily on the size of training data. However, in many healthcare applications it is difficult to collect sufficiently large training datasets. Transfer learning can help overcome this issue by transferring the knowledge from readily available datasets (source) to a new dataset (target). In this work, we propose a hybrid instance-based transfer learning method that outperforms a set of baselines including state-of-the-art instance-based transfer learning approaches. Our method uses a probabilistic weighting strategy to fuse information from the source domain to the model learned in the target domain. Our method is generic, applicable to multiple source domains, and robust with respect to negative transfer. We demonstrate the effectiveness of our approach through extensive experiments for two different applications.