 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn granularity of prosodic representations in expressive text-to-speech
Jan 26, 2023



In expressive speech synthesis it is widely adopted to use latent prosody representations to deal with variability of the data during training. Same text may correspond to various acoustic realizations, which is known as a one-to-many mapping problem in text-to-speech. Utterance, word, or phoneme-level representations are extracted from target signal in an auto-encoding setup, to complement phonetic input and simplify that mapping. This paper compares prosodic embeddings at different levels of granularity and examines their prediction from text. We show that utterance-level embeddings have insufficient capacity and phoneme-level tend to introduce instabilities when predicted from text. Word-level representations impose balance between capacity and predictability. As a result, we close the gap in naturalness by 90% between synthetic speech and recordings on LibriTTS dataset, without sacrificing intelligibility.
GaLeNet: Multimodal Learning for Disaster Prediction, Management and Relief
Jun 18, 2022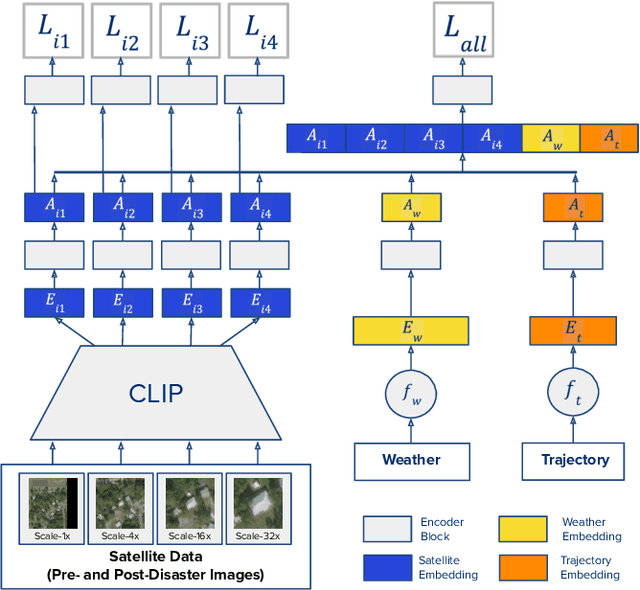
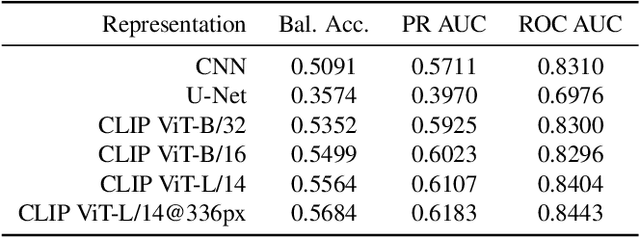
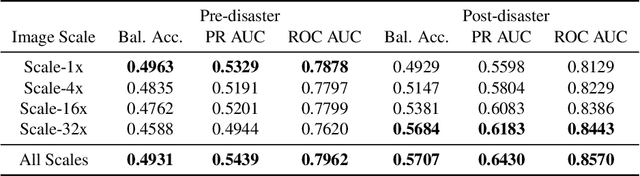
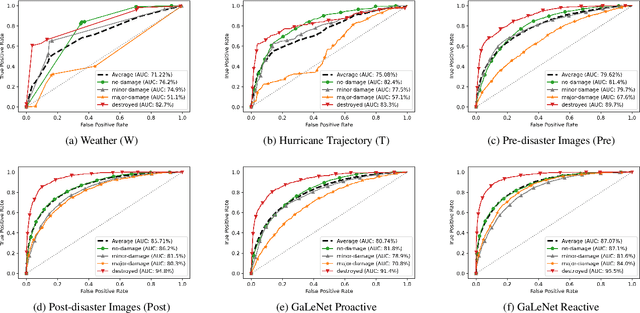
After a natural disaster, such as a hurricane, millions are left in need of emergency assistance. To allocate resources optimally, human planners need to accurately analyze data that can flow in large volumes from several sources. This motivates the development of multimodal machine learning frameworks that can integrate multiple data sources and leverage them efficiently. To date, the research community has mainly focused on unimodal reasoning to provide granular assessments of the damage. Moreover, previous studies mostly rely on post-disaster images, which may take several days to become available. In this work, we propose a multimodal framework (GaLeNet) for assessing the severity of damage by complementing pre-disaster images with weather data and the trajectory of the hurricane. Through extensive experiments on data from two hurricanes, we demonstrate (i) the merits of multimodal approaches compared to unimodal methods, and (ii) the effectiveness of GaLeNet at fusing various modalities. Furthermore, we show that GaLeNet can leverage pre-disaster images in the absence of post-disaster images, preventing substantial delays in decision making.
Non-Autoregressive TTS with Explicit Duration Modelling for Low-Resource Highly Expressive Speech
Jun 25, 2021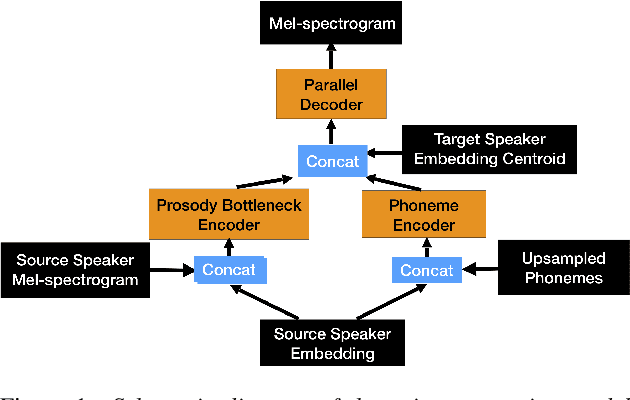
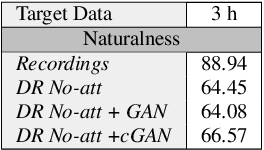

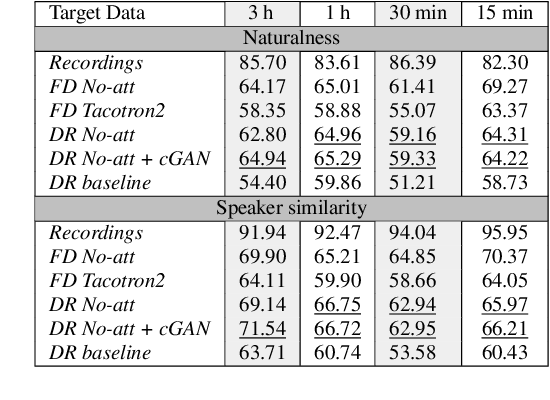
Whilst recent neural text-to-speech (TTS) approaches produce high-quality speech, they typically require a large amount of recordings from the target speaker. In previous work, a 3-step method was proposed to generate high-quality TTS while greatly reducing the amount of data required for training. However, we have observed a ceiling effect in the level of naturalness achievable for highly expressive voices when using this approach. In this paper, we present a method for building highly expressive TTS voices with as little as 15 minutes of speech data from the target speaker. Compared to the current state-of-the-art approach, our proposed improvements close the gap to recordings by 23.3% for naturalness of speech and by 16.3% for speaker similarity. Further, we match the naturalness and speaker similarity of a Tacotron2-based full-data (~10 hours) model using only 15 minutes of target speaker data, whereas with 30 minutes or more, we significantly outperform it. The following improvements are proposed: 1) changing from an autoregressive, attention-based TTS model to a non-autoregressive model replacing attention with an external duration model and 2) an additional Conditional Generative Adversarial Network (cGAN) based fine-tuning step.