 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalLens Shared Task 2024: Legal Violation Identification in Unstructured Text
Paper and Code



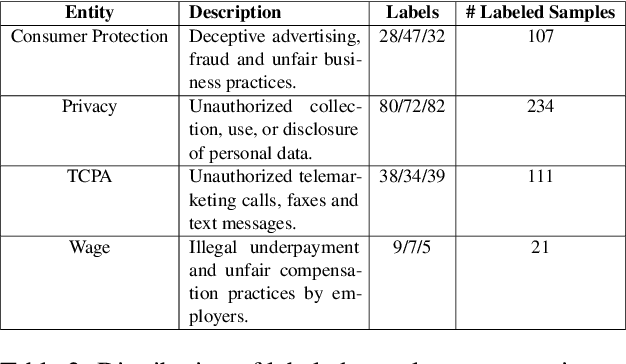
This paper presents the results of the LegalLens Shared Task, focusing on detecting legal violations within text in the wild across two sub-tasks: LegalLens-NER for identifying legal violation entities and LegalLens-NLI for associating these violations with relevant legal contexts and affected individuals. Using an enhanced LegalLens dataset covering labor, privacy, and consumer protection domains, 38 teams participated in the task. Our analysis reveals that while a mix of approaches was used, the top-performing teams in both tasks consistently relied on fine-tuning pre-trained language models, outperforming legal-specific models and few-shot methods. The top-performing team achieved a 7.11% improvement in NER over the baseline, while NLI saw a more marginal improvement of 5.7%. Despite these gains, the complexity of legal texts leaves room for further advancements.