 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Sentences Semantically Related: A Textual Relatedness Dataset and Empirical Study
Paper and Code
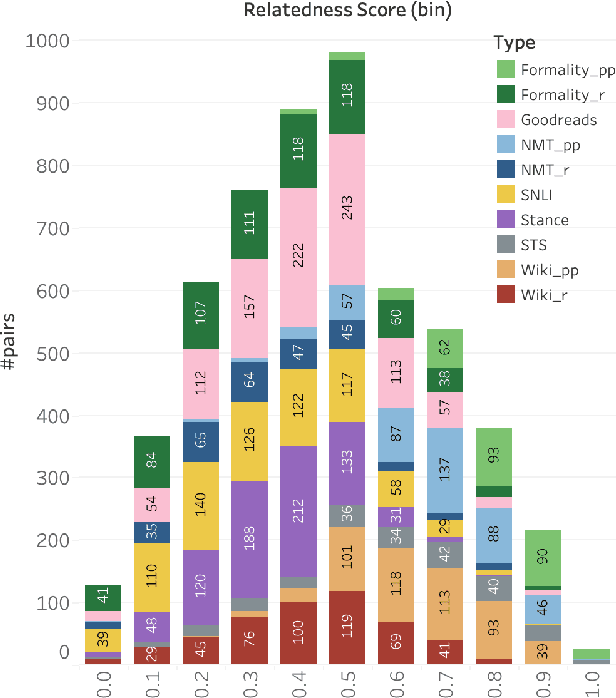
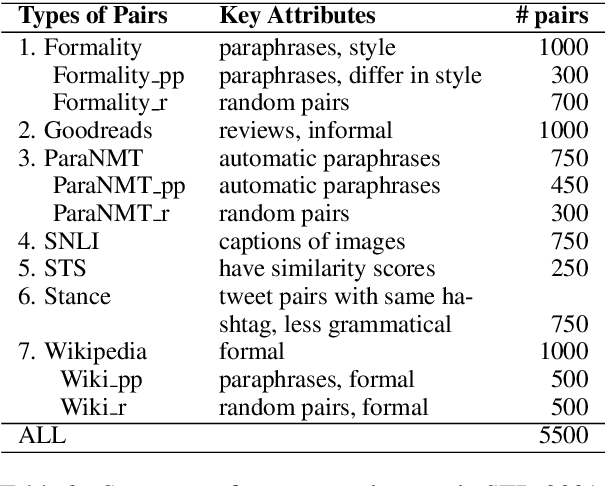
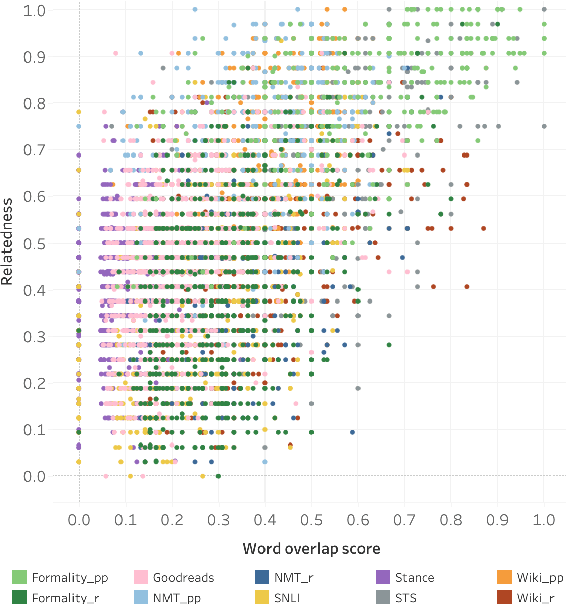

The degree of semantic relatedness (or, closeness in meaning) of two units of language has long been considered fundamental to understanding meaning. Automatically determining relatedness has many applications such as question answering and summarization. However, prior NLP work has largely focused on semantic similarity (a subset of relatedness), because of a lack of relatedness datasets. Here for the first time, we introduce a dataset of semantic relatedness for sentence pairs. This dataset, STR-2021, has 5,500 English sentence pairs manually annotated for semantic relatedness using a comparative annotation framework. We show that the resulting scores have high reliability (repeat annotation correlation of 0.84). We use the dataset to explore a number of questions on what makes two sentences more semantically related. We also evaluate a suite of sentence representation methods on their ability to place pairs that are more related closer to each other in vector space.