 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNILC-USP at SemEval-2017 Task 4: A Multi-view Ensemble for Twitter Sentiment Analysis
Apr 07, 2017
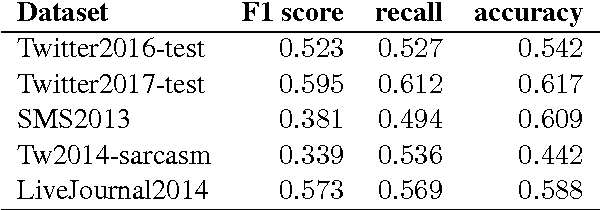
This paper describes our multi-view ensemble approach to SemEval-2017 Task 4 on Sentiment Analysis in Twitter, specifically, the Message Polarity Classification subtask for English (subtask A). Our system is a voting ensemble, where each base classifier is trained in a different feature space. The first space is a bag-of-words model and has a Linear SVM as base classifier. The second and third spaces are two different strategies of combining word embeddings to represent sentences and use a Linear SVM and a Logistic Regressor as base classifiers. The proposed system was ranked 18th out of 38 systems considering F1 score and 20th considering recall.
Authorship attribution via network motifs identification
Jul 23, 2016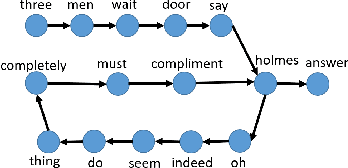
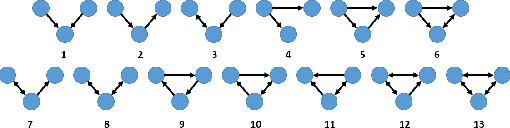
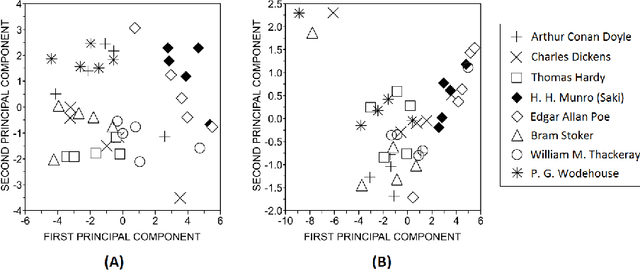
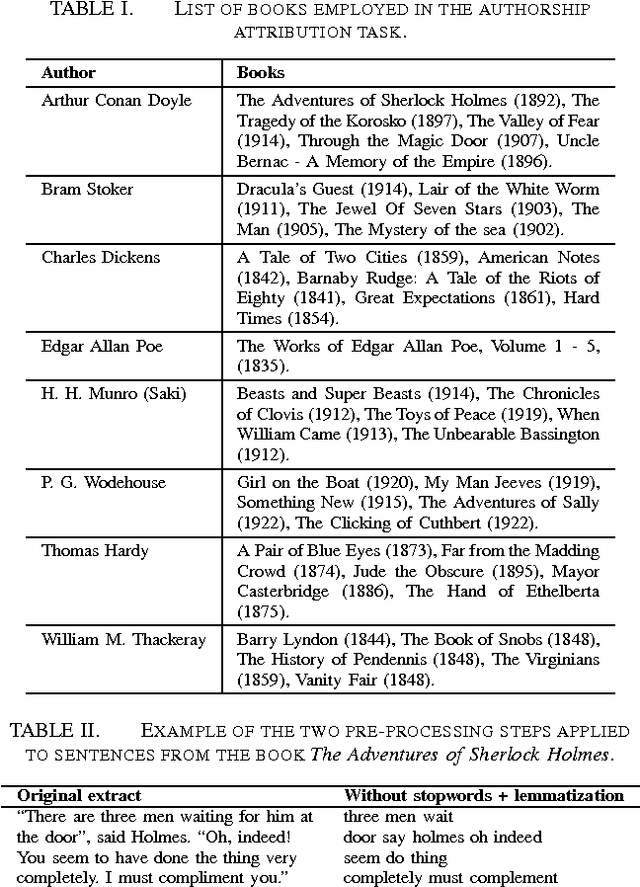
Concepts and methods of complex networks can be used to analyse texts at their different complexity levels. Examples of natural language processing (NLP) tasks studied via topological analysis of networks are keyword identification, automatic extractive summarization and authorship attribution. Even though a myriad of network measurements have been applied to study the authorship attribution problem, the use of motifs for text analysis has been restricted to a few works. The goal of this paper is to apply the concept of motifs, recurrent interconnection patterns, in the authorship attribution task. The absolute frequencies of all thirteen directed motifs with three nodes were extracted from the co-occurrence networks and used as classification features. The effectiveness of these features was verified with four machine learning methods. The results show that motifs are able to distinguish the writing style of different authors. In our best scenario, 57.5% of the books were correctly classified. The chance baseline for this problem is 12.5%. In addition, we have found that function words play an important role in these recurrent patterns. Taken together, our findings suggest that motifs should be further explored in other related linguistic tasks.
* Preprint submitted for the 5th Brazilian Conference on Intelligent Systems