 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Sentiment Analysis Without (Good) Translation
Paper and Code
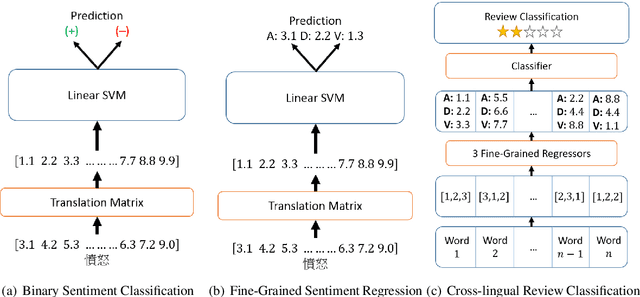

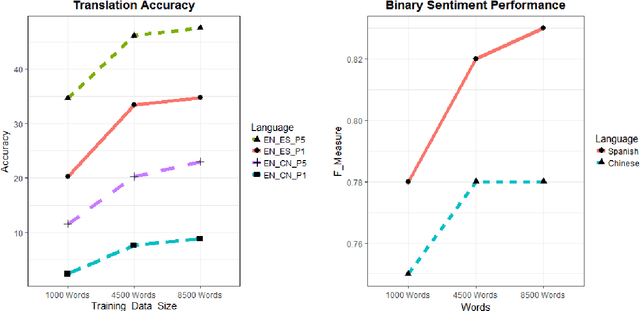
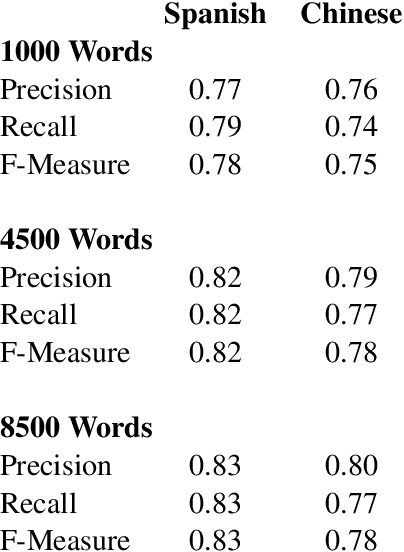
Current approaches to cross-lingual sentiment analysis try to leverage the wealth of labeled English data using bilingual lexicons, bilingual vector space embeddings, or machine translation systems. Here we show that it is possible to use a single linear transformation, with as few as 2000 word pairs, to capture fine-grained sentiment relationships between words in a cross-lingual setting. We apply these cross-lingual sentiment models to a diverse set of tasks to demonstrate their functionality in a non-English context. By effectively leveraging English sentiment knowledge without the need for accurate translation, we can analyze and extract features from other languages with scarce data at a very low cost, thus making sentiment and related analyses for many languages inexpensive.