 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized moral inference
Aug 25, 2020



Developing moral awareness in intelligent systems has shifted from a topic of philosophical inquiry to a critical and practical issue in artificial intelligence over the past decades. However, automated inference of everyday moral situations remains an under-explored problem. We present a text-based approach that predicts people's intuitive judgment of moral vignettes. Our methodology builds on recent work in contextualized language models and textual inference of moral sentiment. We show that a contextualized representation offers a substantial advantage over alternative representations based on word embeddings and emotion sentiment in inferring human moral judgment, evaluated and reflected in three independent datasets from moral psychology. We discuss the promise and limitations of our approach toward automated textual moral reasoning.
Text-based inference of moral sentiment change
Jan 20, 2020



We present a text-based framework for investigating moral sentiment change of the public via longitudinal corpora. Our framework is based on the premise that language use can inform people's moral perception toward right or wrong, and we build our methodology by exploring moral biases learned from diachronic word embeddings. We demonstrate how a parameter-free model supports inference of historical shifts in moral sentiment toward concepts such as slavery and democracy over centuries at three incremental levels: moral relevance, moral polarity, and fine-grained moral dimensions. We apply this methodology to visualizing moral time courses of individual concepts and analyzing the relations between psycholinguistic variables and rates of moral sentiment change at scale. Our work offers opportunities for applying natural language processing toward characterizing moral sentiment change in society.
Representation Learning for Discovering Phonemic Tone Contours
Oct 20, 2019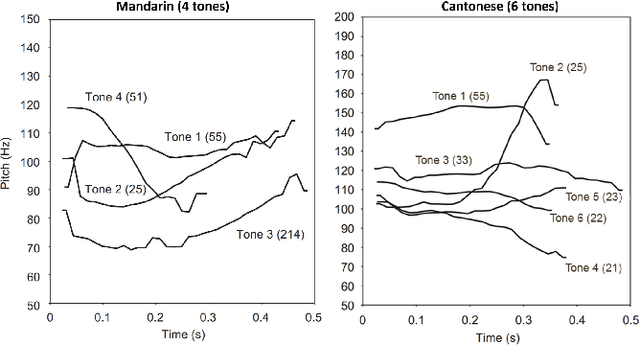
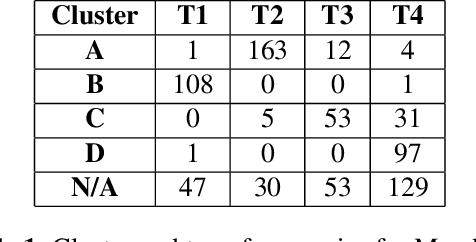
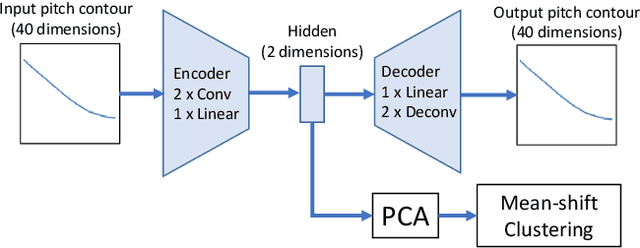
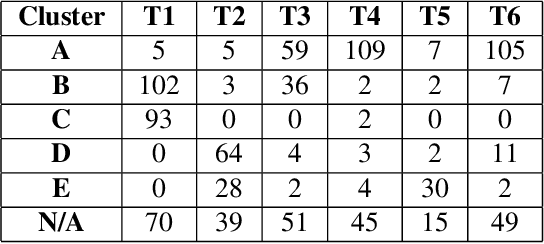
Tone is a prosodic feature used to distinguish words in many languages, some of which are endangered and scarcely documented. In this work, we use unsupervised representation learning to identify probable clusters of syllables that share the same phonemic tone. Our method extracts the pitch for each syllable, then trains a convolutional autoencoder to learn a low dimensional representation for each contour. We then apply the mean shift algorithm to cluster tones in high-density regions of the latent space. Furthermore, by feeding the centers of each cluster into the decoder, we produce a prototypical contour that represents each cluster. We apply this method to spoken multi-syllable words in Mandarin Chinese and Cantonese and evaluate how closely our clusters match the ground truth tone categories. Finally, we discuss some difficulties with our approach, including contextual tone variation and allophony effects.