 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-Based Candidate Node Predictor for Influence Maximization in Temporal Graphs
Mar 31, 2025



In an age where information spreads rapidly across social media, effectively identifying influential nodes in dynamic networks is critical. Traditional influence maximization strategies often fail to keep up with rapidly evolving relationships and structures, leading to missed opportunities and inefficiencies. To address this, we propose a novel learning-based approach integrating Graph Neural Networks (GNNs) with Bidirectional Long Short-Term Memory (BiLSTM) models. This hybrid framework captures both structural and temporal dynamics, enabling accurate prediction of candidate nodes for seed set selection. The bidirectional nature of BiLSTM allows our model to analyze patterns from both past and future network states, ensuring adaptability to changes over time. By dynamically adapting to graph evolution at each time snapshot, our approach improves seed set calculation efficiency, achieving an average of 90% accuracy in predicting potential seed nodes across diverse networks. This significantly reduces computational overhead by optimizing the number of nodes evaluated for seed selection. Our method is particularly effective in fields like viral marketing and social network analysis, where understanding temporal dynamics is crucial.
Disharmony: Forensics using Reverse Lighting Harmonization
Jan 17, 2025



Content generation and manipulation approaches based on deep learning methods have seen significant advancements, leading to an increased need for techniques to detect whether an image has been generated or edited. Another area of research focuses on the insertion and harmonization of objects within images. In this study, we explore the potential of using harmonization data in conjunction with a segmentation model to enhance the detection of edited image regions. These edits can be either manually crafted or generated using deep learning methods. Our findings demonstrate that this approach can effectively identify such edits. Existing forensic models often overlook the detection of harmonized objects in relation to the background, but our proposed Disharmony Network addresses this gap. By utilizing an aggregated dataset of harmonization techniques, our model outperforms existing forensic networks in identifying harmonized objects integrated into their backgrounds, and shows potential for detecting various forms of edits, including virtual try-on tasks.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
DISHONEST: Dissecting misInformation Spread using Homogeneous sOcial NEtworks and Semantic Topic classification
Dec 12, 2024The emergence of the COVID-19 pandemic resulted in a significant rise in the spread of misinformation on online platforms such as Twitter. Oftentimes this growth is blamed on the idea of the "echo chamber." However, the behavior said to characterize these echo chambers exists in two dimensions. The first is in a user's social interactions, where they are said to stick with the same clique of like-minded users. The second is in the content of their posts, where they are said to repeatedly espouse homogeneous ideas. In this study, we link the two by using Twitter's network of retweets to study social interactions and topic modeling to study tweet content. In order to measure the diversity of a user's interactions over time, we develop a novel metric to track the speed at which they travel through the social network. The application of these analysis methods to misinformation-focused data from the pandemic demonstrates correlation between social behavior and tweet content. We believe this correlation supports the common intuition about how antisocial users behave, and further suggests that it holds even in subcommunities already rife with misinformation.
Learning to Simulate Aerosol Dynamics with Graph Neural Networks
Sep 20, 2024



Aerosol effects on climate, weather, and air quality depend on characteristics of individual particles, which are tremendously diverse and change in time. Particle-resolved models are the only models able to capture this diversity in particle physiochemical properties, and these models are computationally expensive. As a strategy for accelerating particle-resolved microphysics models, we introduce Graph-based Learning of Aerosol Dynamics (GLAD) and use this model to train a surrogate of the particle-resolved model PartMC-MOSAIC. GLAD implements a Graph Network-based Simulator (GNS), a machine learning framework that has been used to simulate particle-based fluid dynamics models. In GLAD, each particle is represented as a node in a graph, and the evolution of the particle population over time is simulated through learned message passing. We demonstrate our GNS approach on a simple aerosol system that includes condensation of sulfuric acid onto particles composed of sulfate, black carbon, organic carbon, and water. A graph with particles as nodes is constructed, and a graph neural network (GNN) is then trained using the model output from PartMC-MOSAIC. The trained GNN can then be used for simulating and predicting aerosol dynamics over time. Results demonstrate the framework's ability to accurately learn chemical dynamics and generalize across different scenarios, achieving efficient training and prediction times. We evaluate the performance across three scenarios, highlighting the framework's robustness and adaptability in modeling aerosol microphysics and chemistry.
Parallel Algorithms for Median Consensus Clustering in Complex Networks
Aug 21, 2024We develop an algorithm that finds the consensus of many different clustering solutions of a graph. We formulate the problem as a median set partitioning problem and propose a greedy optimization technique. Unlike other approaches that find median set partitions, our algorithm takes graph structure into account and finds a comparable quality solution much faster than the other approaches. For graphs with known communities, our consensus partition captures the actual community structure more accurately than alternative approaches. To make it applicable to large graphs, we remove sequential dependencies from our algorithm and design a parallel algorithm. Our parallel algorithm achieves 35x speedup when utilizing 64 processing cores for large real-world graphs from single-cell experiments.
PermitQA: A Benchmark for Retrieval Augmented Generation in Wind Siting and Permitting domain
Aug 21, 2024
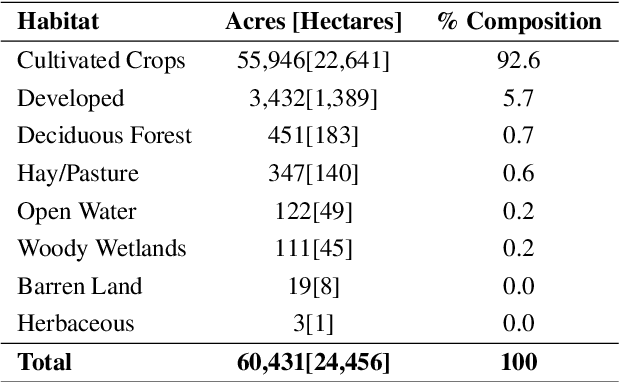

In the rapidly evolving landscape of Natural Language Processing (NLP) and text generation, the emergence of Retrieval Augmented Generation (RAG) presents a promising avenue for improving the quality and reliability of generated text by leveraging information retrieved from user specified database. Benchmarking is essential to evaluate and compare the performance of the different RAG configurations in terms of retriever and generator, providing insights into their effectiveness, scalability, and suitability for the specific domain and applications. In this paper, we present a comprehensive framework to generate a domain relevant RAG benchmark. Our framework is based on automatic question-answer generation with Human (domain experts)-AI Large Language Model (LLM) teaming. As a case study, we demonstrate the framework by introducing PermitQA, a first-of-its-kind benchmark on the wind siting and permitting domain which comprises of multiple scientific documents/reports related to environmental impact of wind energy projects. Our framework systematically evaluates RAG performance using diverse metrics and multiple question types with varying complexity level. We also demonstrate the performance of different models on our benchmark.
RAG vs. Long Context: Examining Frontier Large Language Models for Environmental Review Document Comprehension
Jul 10, 2024



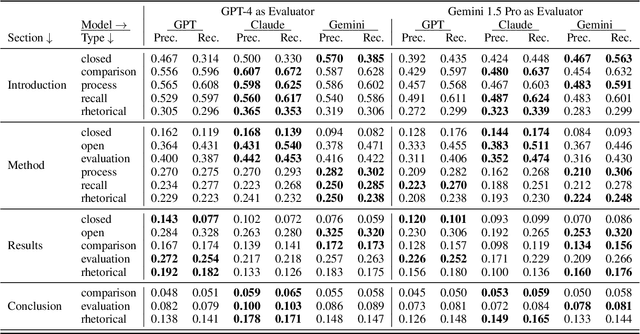
Large Language Models (LLMs) have been applied to many research problems across various domains. One of the applications of LLMs is providing question-answering systems that cater to users from different fields. The effectiveness of LLM-based question-answering systems has already been established at an acceptable level for users posing questions in popular and public domains such as trivia and literature. However, it has not often been established in niche domains that traditionally require specialized expertise. To this end, we construct the NEPAQuAD1.0 benchmark to evaluate the performance of three frontier LLMs -- Claude Sonnet, Gemini, and GPT-4 -- when answering questions originating from Environmental Impact Statements prepared by U.S. federal government agencies in accordance with the National Environmental Environmental Act (NEPA). We specifically measure the ability of LLMs to understand the nuances of legal, technical, and compliance-related information present in NEPA documents in different contextual scenarios. For example, we test the LLMs' internal prior NEPA knowledge by providing questions without any context, as well as assess how LLMs synthesize the contextual information present in long NEPA documents to facilitate the question/answering task. We compare the performance of the long context LLMs and RAG powered models in handling different types of questions (e.g., problem-solving, divergent). Our results suggest that RAG powered models significantly outperform the long context models in the answer accuracy regardless of the choice of the frontier LLM. Our further analysis reveals that many models perform better answering closed questions than divergent and problem-solving questions.
Predictive Analytics of Varieties of Potatoes
Apr 04, 2024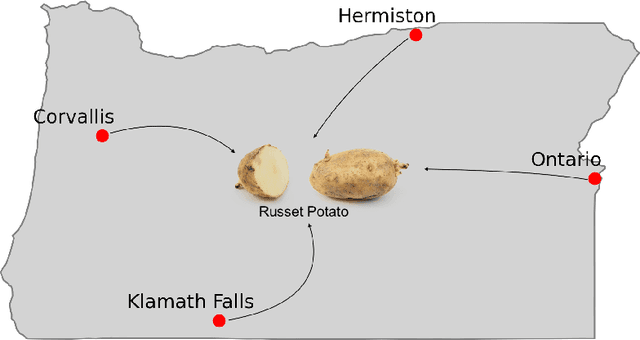
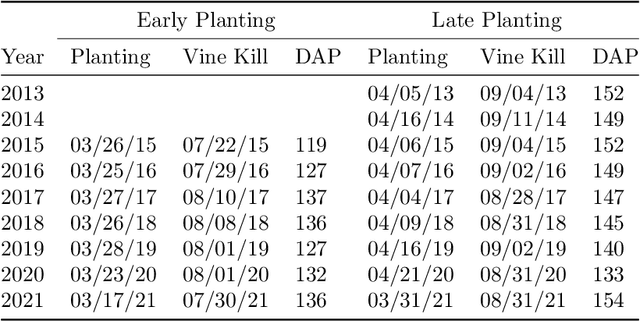
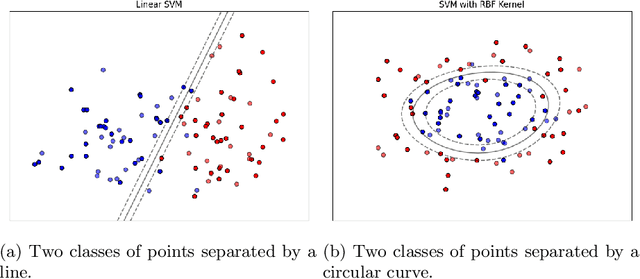
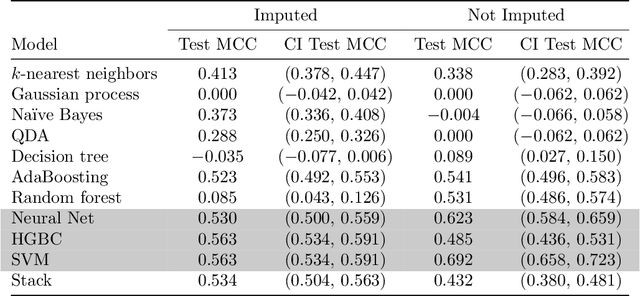
We explore the application of machine learning algorithms to predict the suitability of Russet potato clones for advancement in breeding trials. Leveraging data from manually collected trials in the state of Oregon, we investigate the potential of a wide variety of state-of-the-art binary classification models. We conduct a comprehensive analysis of the dataset that includes preprocessing, feature engineering, and imputation to address missing values. We focus on several key metrics such as accuracy, F1-score, and Matthews correlation coefficient (MCC) for model evaluation. The top-performing models, namely the multi-layer perceptron (MLPC), histogram-based gradient boosting classifier (HGBC), and a support vector machine (SVC), demonstrate consistent and significant results. Variable selection further enhances model performance and identifies influential features in predicting trial outcomes. The findings emphasize the potential of machine learning in streamlining the selection process for potato varieties, offering benefits such as increased efficiency, substantial cost savings, and judicious resource utilization. Our study contributes insights into precision agriculture and showcases the relevance of advanced technologies for informed decision-making in breeding programs.
Semi-Supervised Learning of Dynamical Systems with Neural Ordinary Differential Equations: A Teacher-Student Model Approach
Oct 19, 2023Modeling dynamical systems is crucial for a wide range of tasks, but it remains challenging due to complex nonlinear dynamics, limited observations, or lack of prior knowledge. Recently, data-driven approaches such as Neural Ordinary Differential Equations (NODE) have shown promising results by leveraging the expressive power of neural networks to model unknown dynamics. However, these approaches often suffer from limited labeled training data, leading to poor generalization and suboptimal predictions. On the other hand, semi-supervised algorithms can utilize abundant unlabeled data and have demonstrated good performance in classification and regression tasks. We propose TS-NODE, the first semi-supervised approach to modeling dynamical systems with NODE. TS-NODE explores cheaply generated synthetic pseudo rollouts to broaden exploration in the state space and to tackle the challenges brought by lack of ground-truth system data under a teacher-student model. TS-NODE employs an unified optimization framework that corrects the teacher model based on the student's feedback while mitigating the potential false system dynamics present in pseudo rollouts. TS-NODE demonstrates significant performance improvements over a baseline Neural ODE model on multiple dynamical system modeling tasks.