 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermitQA: A Benchmark for Retrieval Augmented Generation in Wind Siting and Permitting domain
Aug 21, 2024
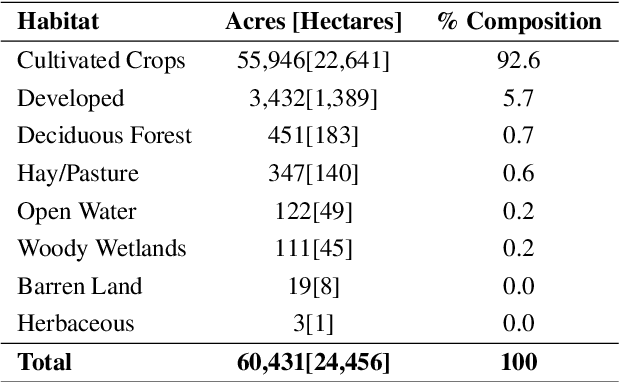

In the rapidly evolving landscape of Natural Language Processing (NLP) and text generation, the emergence of Retrieval Augmented Generation (RAG) presents a promising avenue for improving the quality and reliability of generated text by leveraging information retrieved from user specified database. Benchmarking is essential to evaluate and compare the performance of the different RAG configurations in terms of retriever and generator, providing insights into their effectiveness, scalability, and suitability for the specific domain and applications. In this paper, we present a comprehensive framework to generate a domain relevant RAG benchmark. Our framework is based on automatic question-answer generation with Human (domain experts)-AI Large Language Model (LLM) teaming. As a case study, we demonstrate the framework by introducing PermitQA, a first-of-its-kind benchmark on the wind siting and permitting domain which comprises of multiple scientific documents/reports related to environmental impact of wind energy projects. Our framework systematically evaluates RAG performance using diverse metrics and multiple question types with varying complexity level. We also demonstrate the performance of different models on our benchmark.
ATLANTIC: Structure-Aware Retrieval-Augmented Language Model for Interdisciplinary Science
Nov 21, 2023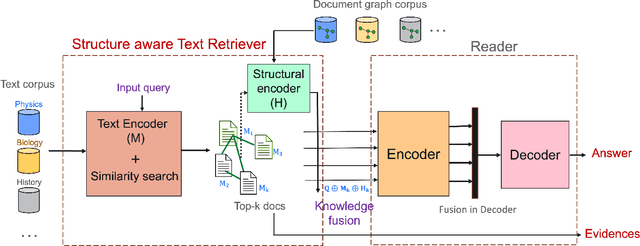

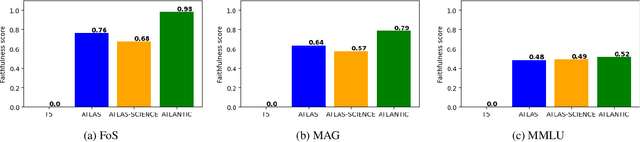

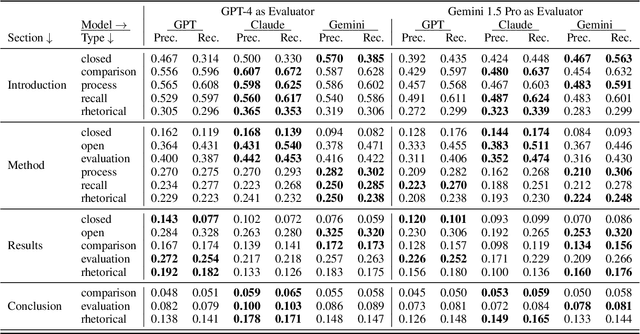
Large language models record impressive performance on many natural language processing tasks. However, their knowledge capacity is limited to the pretraining corpus. Retrieval augmentation offers an effective solution by retrieving context from external knowledge sources to complement the language model. However, existing retrieval augmentation techniques ignore the structural relationships between these documents. Furthermore, retrieval models are not explored much in scientific tasks, especially in regard to the faithfulness of retrieved documents. In this paper, we propose a novel structure-aware retrieval augmented language model that accommodates document structure during retrieval augmentation. We create a heterogeneous document graph capturing multiple types of relationships (e.g., citation, co-authorship, etc.) that connect documents from more than 15 scientific disciplines (e.g., Physics, Medicine, Chemistry, etc.). We train a graph neural network on the curated document graph to act as a structural encoder for the corresponding passages retrieved during the model pretraining. Particularly, along with text embeddings of the retrieved passages, we obtain structural embeddings of the documents (passages) and fuse them together before feeding them to the language model. We evaluate our model extensively on various scientific benchmarks that include science question-answering and scientific document classification tasks. Experimental results demonstrate that structure-aware retrieval improves retrieving more coherent, faithful and contextually relevant passages, while showing a comparable performance in the overall accuracy.
Empirical evaluation of Uncertainty Quantification in Retrieval-Augmented Language Models for Science
Nov 15, 2023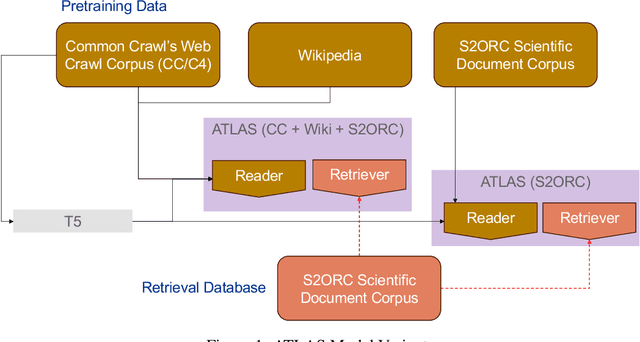
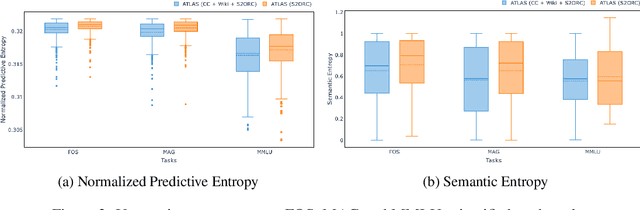

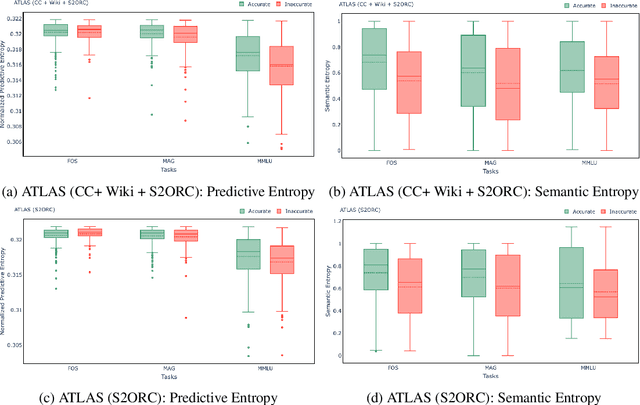
Large language models (LLMs) have shown remarkable achievements in natural language processing tasks, producing high-quality outputs. However, LLMs still exhibit limitations, including the generation of factually incorrect information. In safety-critical applications, it is important to assess the confidence of LLM-generated content to make informed decisions. Retrieval Augmented Language Models (RALMs) is relatively a new area of research in NLP. RALMs offer potential benefits for scientific NLP tasks, as retrieved documents, can serve as evidence to support model-generated content. This inclusion of evidence enhances trustworthiness, as users can verify and explore the retrieved documents to validate model outputs. Quantifying uncertainty in RALM generations further improves trustworthiness, with retrieved text and confidence scores contributing to a comprehensive and reliable model for scientific applications. However, there is limited to no research on UQ for RALMs, particularly in scientific contexts. This study aims to address this gap by conducting a comprehensive evaluation of UQ in RALMs, focusing on scientific tasks. This research investigates how uncertainty scores vary when scientific knowledge is incorporated as pretraining and retrieval data and explores the relationship between uncertainty scores and the accuracy of model-generated outputs. We observe that an existing RALM finetuned with scientific knowledge as the retrieval data tends to be more confident in generating predictions compared to the model pretrained only with scientific knowledge. We also found that RALMs are overconfident in their predictions, making inaccurate predictions more confidently than accurate ones. Scientific knowledge provided either as pretraining or retrieval corpus does not help alleviate this issue. We released our code, data and dashboards at https://github.com/pnnl/EXPERT2.
Evaluating the Effectiveness of Retrieval-Augmented Large Language Models in Scientific Document Reasoning
Nov 07, 2023Despite the dramatic progress in Large Language Model (LLM) development, LLMs often provide seemingly plausible but not factual information, often referred to as hallucinations. Retrieval-augmented LLMs provide a non-parametric approach to solve these issues by retrieving relevant information from external data sources and augment the training process. These models help to trace evidence from an externally provided knowledge base allowing the model predictions to be better interpreted and verified. In this work, we critically evaluate these models in their ability to perform in scientific document reasoning tasks. To this end, we tuned multiple such model variants with science-focused instructions and evaluated them on a scientific document reasoning benchmark for the usefulness of the retrieved document passages. Our findings suggest that models justify predictions in science tasks with fabricated evidence and leveraging scientific corpus as pretraining data does not alleviate the risk of evidence fabrication.
NuclearQA: A Human-Made Benchmark for Language Models for the Nuclear Domain
Oct 17, 2023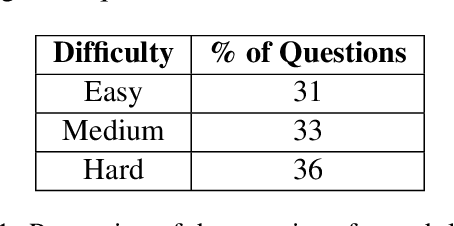

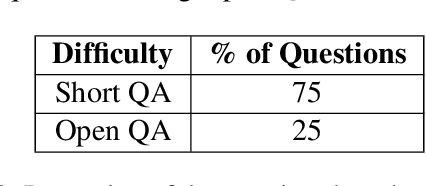
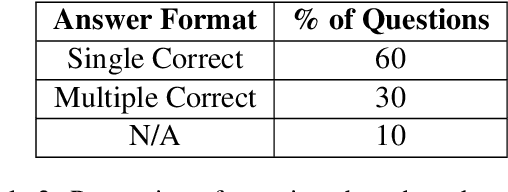
As LLMs have become increasingly popular, they have been used in almost every field. But as the application for LLMs expands from generic fields to narrow, focused science domains, there exists an ever-increasing gap in ways to evaluate their efficacy in those fields. For the benchmarks that do exist, a lot of them focus on questions that don't require proper understanding of the subject in question. In this paper, we present NuclearQA, a human-made benchmark of 100 questions to evaluate language models in the nuclear domain, consisting of a varying collection of questions that have been specifically designed by experts to test the abilities of language models. We detail our approach and show how the mix of several types of questions makes our benchmark uniquely capable of evaluating models in the nuclear domain. We also present our own evaluation metric for assessing LLM's performances due to the limitations of existing ones. Our experiments on state-of-the-art models suggest that even the best LLMs perform less than satisfactorily on our benchmark, demonstrating the scientific knowledge gap of existing LLMs.
Interactive Decision Tree Creation and Enhancement with Complete Visualization for Explainable Modeling
May 28, 2023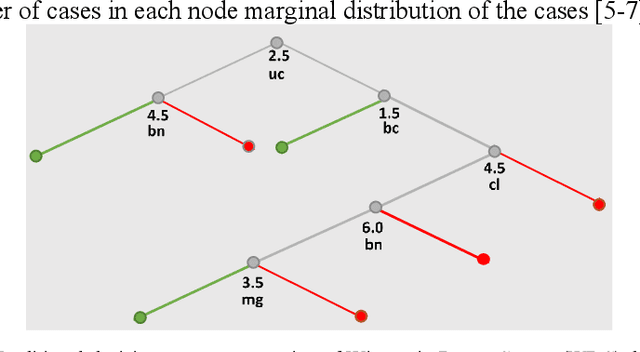
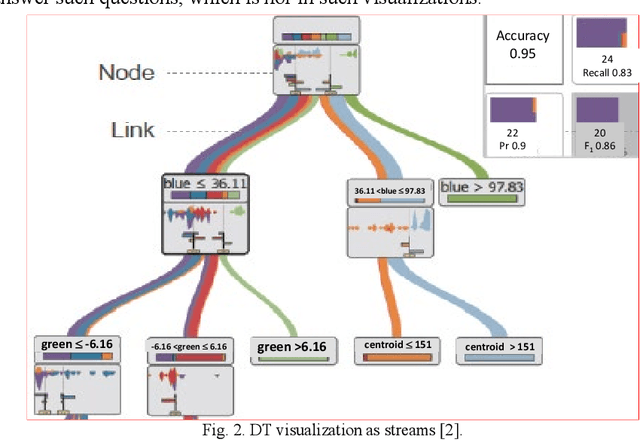


To increase the interpretability and prediction accuracy of the Machine Learning (ML) models, visualization of ML models is a key part of the ML process. Decision Trees (DTs) are essential in machine learning (ML) because they are used to understand many black box ML models including Deep Learning models. In this research, two new methods for creation and enhancement with complete visualizing Decision Trees as understandable models are suggested. These methods use two versions of General Line Coordinates (GLC): Bended Coordinates (BC) and Shifted Paired Coordinates (SPC). The Bended Coordinates are a set of line coordinates, where each coordinate is bended in a threshold point of the respective DT node. In SPC, each n-D point is visualized in a set of shifted pairs of 2-D Cartesian coordinates as a directed graph. These new methods expand and complement the capabilities of existing methods to visualize DT models more completely. These capabilities allow us to observe and analyze: (1) relations between attributes, (2) individual cases relative to the DT structure, (3) data flow in the DT, (4) sensitivity of each split threshold in the DT nodes, and (5) density of cases in parts of the n-D space. These features are critical for DT models' performance evaluation and improvement by domain experts and end users as they help to prevent overgeneralization and overfitting of the models. The advantages of this methodology are illustrated in the case studies on benchmark real-world datasets. The paper also demonstrates how to generalize them for decision tree visualizations in different General Line Coordinates.
Visualization of Decision Trees based on General Line Coordinates to Support Explainable Models
May 09, 2022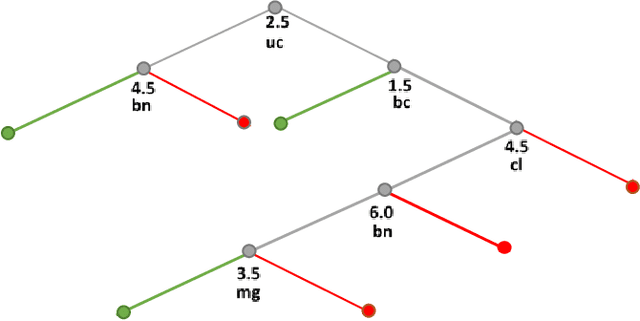


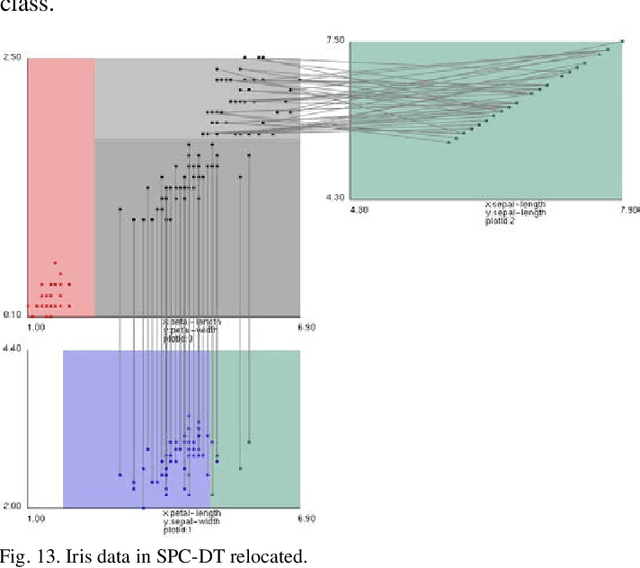
Visualization of Machine Learning (ML) models is an important part of the ML process to enhance the interpretability and prediction accuracy of the ML models. This paper proposes a new method SPC-DT to visualize the Decision Tree (DT) as interpretable models. These methods use a version of General Line Coordinates called Shifted Paired Coordinates (SPC). In SPC, each n-D point is visualized in a set of shifted pairs of 2-D Cartesian coordinates as a directed graph. The new method expands and complements the capabilities of existing methods, to visualize DT models. It shows: (1) relations between attributes, (2) individual cases relative to the DT structure, (3) data flow in the DT, (4) how tight each split is to thresholds in the DT nodes, and (5) the density of cases in parts of the n-D space. This information is important for domain experts for evaluating and improving the DT models, including avoiding overgeneralization and overfitting of models, along with their performance. The benefits of the methods are demonstrated in the case studies, using three real datasets.