 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuclearQA: A Human-Made Benchmark for Language Models for the Nuclear Domain
Oct 17, 2023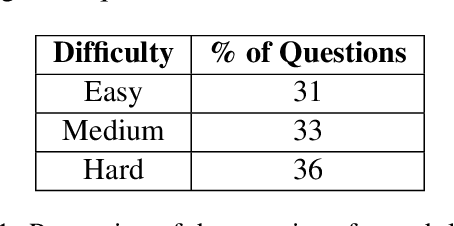

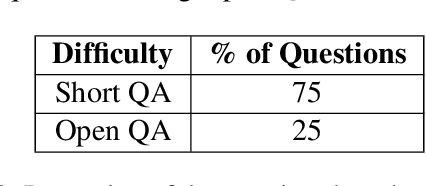
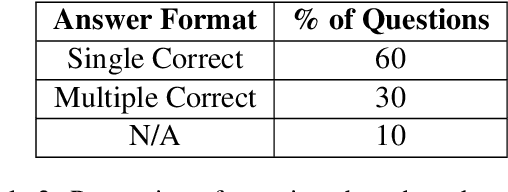
As LLMs have become increasingly popular, they have been used in almost every field. But as the application for LLMs expands from generic fields to narrow, focused science domains, there exists an ever-increasing gap in ways to evaluate their efficacy in those fields. For the benchmarks that do exist, a lot of them focus on questions that don't require proper understanding of the subject in question. In this paper, we present NuclearQA, a human-made benchmark of 100 questions to evaluate language models in the nuclear domain, consisting of a varying collection of questions that have been specifically designed by experts to test the abilities of language models. We detail our approach and show how the mix of several types of questions makes our benchmark uniquely capable of evaluating models in the nuclear domain. We also present our own evaluation metric for assessing LLM's performances due to the limitations of existing ones. Our experiments on state-of-the-art models suggest that even the best LLMs perform less than satisfactorily on our benchmark, demonstrating the scientific knowledge gap of existing LLMs.