 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical evaluation of Uncertainty Quantification in Retrieval-Augmented Language Models for Science
Paper and Code
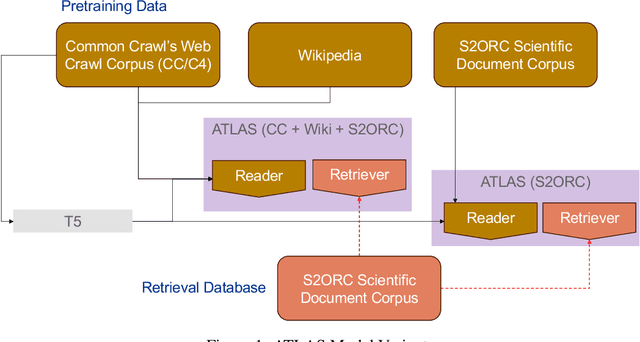
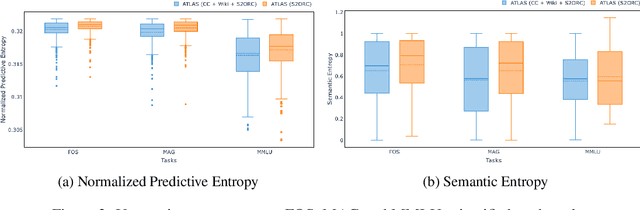

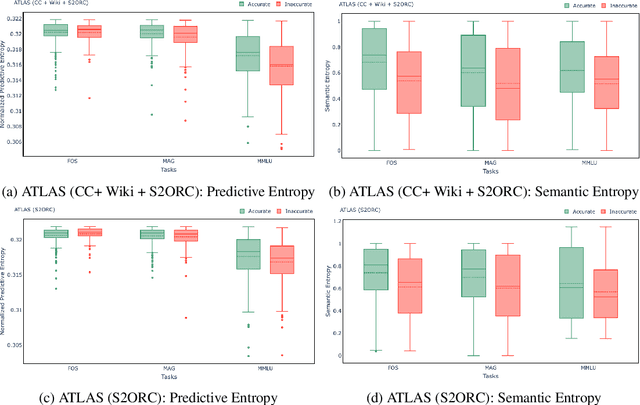
Large language models (LLMs) have shown remarkable achievements in natural language processing tasks, producing high-quality outputs. However, LLMs still exhibit limitations, including the generation of factually incorrect information. In safety-critical applications, it is important to assess the confidence of LLM-generated content to make informed decisions. Retrieval Augmented Language Models (RALMs) is relatively a new area of research in NLP. RALMs offer potential benefits for scientific NLP tasks, as retrieved documents, can serve as evidence to support model-generated content. This inclusion of evidence enhances trustworthiness, as users can verify and explore the retrieved documents to validate model outputs. Quantifying uncertainty in RALM generations further improves trustworthiness, with retrieved text and confidence scores contributing to a comprehensive and reliable model for scientific applications. However, there is limited to no research on UQ for RALMs, particularly in scientific contexts. This study aims to address this gap by conducting a comprehensive evaluation of UQ in RALMs, focusing on scientific tasks. This research investigates how uncertainty scores vary when scientific knowledge is incorporated as pretraining and retrieval data and explores the relationship between uncertainty scores and the accuracy of model-generated outputs. We observe that an existing RALM finetuned with scientific knowledge as the retrieval data tends to be more confident in generating predictions compared to the model pretrained only with scientific knowledge. We also found that RALMs are overconfident in their predictions, making inaccurate predictions more confidently than accurate ones. Scientific knowledge provided either as pretraining or retrieval corpus does not help alleviate this issue. We released our code, data and dashboards at https://github.com/pnnl/EXPERT2.