 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynLP: Parallel Dynamic Batch Update for Label Propagation in Semi-Supervised Learning
Apr 08, 2026Semi-supervised learning aims to infer class labels using only a small fraction of labeled data. In graph-based semi-supervised learning, this is typically achieved through label propagation to predict labels of unlabeled nodes. However, in real-world applications, data often arrive incrementally in batches. Each time a new batch appears, reapplying the traditional label propagation algorithm to recompute all labels is redundant, computationally intensive, and inefficient. To address the absence of an efficient label propagation update method, we propose DynLP, a novel GPU-centric Dynamic Batched Parallel Label Propagation algorithm that performs only the necessary updates, propagating changes to the relevant subgraph without requiring full recalculation. By exploiting GPU architectural optimizations, our algorithm achieves on average 13x and upto 102x speedup on large-scale datasets compared to state-of-the-art approaches.
GNN-Based Candidate Node Predictor for Influence Maximization in Temporal Graphs
Mar 31, 2025



In an age where information spreads rapidly across social media, effectively identifying influential nodes in dynamic networks is critical. Traditional influence maximization strategies often fail to keep up with rapidly evolving relationships and structures, leading to missed opportunities and inefficiencies. To address this, we propose a novel learning-based approach integrating Graph Neural Networks (GNNs) with Bidirectional Long Short-Term Memory (BiLSTM) models. This hybrid framework captures both structural and temporal dynamics, enabling accurate prediction of candidate nodes for seed set selection. The bidirectional nature of BiLSTM allows our model to analyze patterns from both past and future network states, ensuring adaptability to changes over time. By dynamically adapting to graph evolution at each time snapshot, our approach improves seed set calculation efficiency, achieving an average of 90% accuracy in predicting potential seed nodes across diverse networks. This significantly reduces computational overhead by optimizing the number of nodes evaluated for seed selection. Our method is particularly effective in fields like viral marketing and social network analysis, where understanding temporal dynamics is crucial.
AGS-GNN: Attribute-guided Sampling for Graph Neural Networks
May 24, 2024We propose AGS-GNN, a novel attribute-guided sampling algorithm for Graph Neural Networks (GNNs) that exploits node features and connectivity structure of a graph while simultaneously adapting for both homophily and heterophily in graphs. (In homophilic graphs vertices of the same class are more likely to be connected, and vertices of different classes tend to be linked in heterophilic graphs.) While GNNs have been successfully applied to homophilic graphs, their application to heterophilic graphs remains challenging. The best-performing GNNs for heterophilic graphs do not fit the sampling paradigm, suffer high computational costs, and are not inductive. We employ samplers based on feature-similarity and feature-diversity to select subsets of neighbors for a node, and adaptively capture information from homophilic and heterophilic neighborhoods using dual channels. Currently, AGS-GNN is the only algorithm that we know of that explicitly controls homophily in the sampled subgraph through similar and diverse neighborhood samples. For diverse neighborhood sampling, we employ submodularity, which was not used in this context prior to our work. The sampling distribution is pre-computed and highly parallel, achieving the desired scalability. Using an extensive dataset consisting of 35 small ($\le$ 100K nodes) and large (>100K nodes) homophilic and heterophilic graphs, we demonstrate the superiority of AGS-GNN compare to the current approaches in the literature. AGS-GNN achieves comparable test accuracy to the best-performing heterophilic GNNs, even outperforming methods using the entire graph for node classification. AGS-GNN also converges faster compared to methods that sample neighborhoods randomly, and can be incorporated into existing GNN models that employ node or graph sampling.
GreedyML: A Parallel Algorithm for Maximizing Submodular Functions
Mar 15, 2024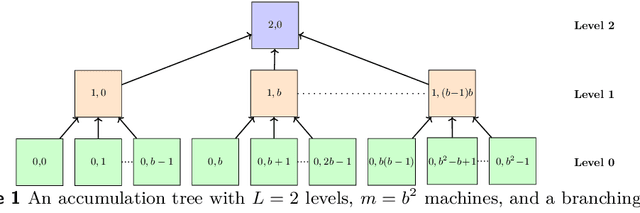
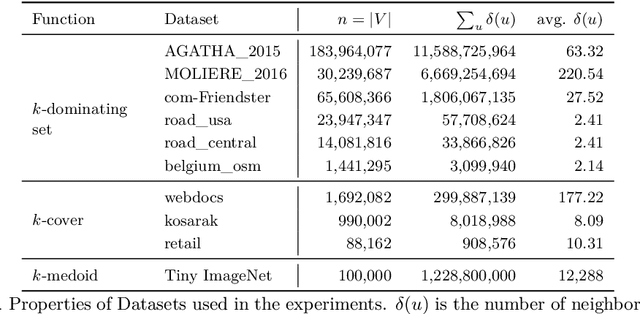
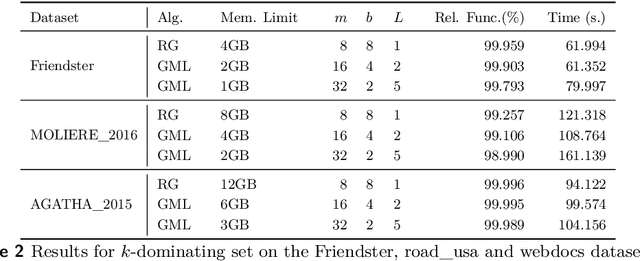
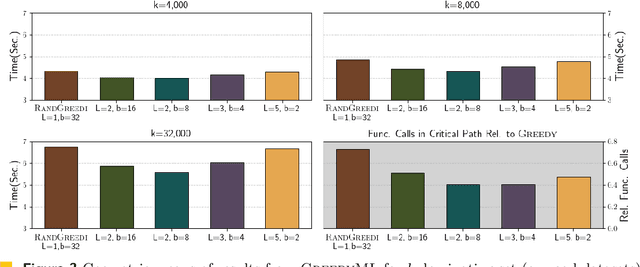
We describe a parallel approximation algorithm for maximizing monotone submodular functions subject to hereditary constraints on distributed memory multiprocessors. Our work is motivated by the need to solve submodular optimization problems on massive data sets, for practical applications in areas such as data summarization, machine learning, and graph sparsification. Our work builds on the randomized distributed RandGreedI algorithm, proposed by Barbosa, Ene, Nguyen, and Ward (2015). This algorithm computes a distributed solution by randomly partitioning the data among all the processors and then employing a single accumulation step in which all processors send their partial solutions to one processor. However, for large problems, the accumulation step could exceed the memory available on a processor, and the processor which performs the accumulation could become a computational bottleneck. Here, we propose a generalization of the RandGreedI algorithm that employs multiple accumulation steps to reduce the memory required. We analyze the approximation ratio and the time complexity of the algorithm (in the BSP model). We also evaluate the new GreedyML algorithm on three classes of problems, and report results from massive data sets with millions of elements. The results show that the GreedyML algorithm can solve problems where the sequential Greedy and distributed RandGreedI algorithms fail due to memory constraints. For certain computationally intensive problems, the GreedyML algorithm can be faster than the RandGreedI algorithm. The observed approximation quality of the solutions computed by the GreedyML algorithm closely matches those obtained by the RandGreedI algorithm on these problems.