 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGS-GNN: Attribute-guided Sampling for Graph Neural Networks
May 24, 2024We propose AGS-GNN, a novel attribute-guided sampling algorithm for Graph Neural Networks (GNNs) that exploits node features and connectivity structure of a graph while simultaneously adapting for both homophily and heterophily in graphs. (In homophilic graphs vertices of the same class are more likely to be connected, and vertices of different classes tend to be linked in heterophilic graphs.) While GNNs have been successfully applied to homophilic graphs, their application to heterophilic graphs remains challenging. The best-performing GNNs for heterophilic graphs do not fit the sampling paradigm, suffer high computational costs, and are not inductive. We employ samplers based on feature-similarity and feature-diversity to select subsets of neighbors for a node, and adaptively capture information from homophilic and heterophilic neighborhoods using dual channels. Currently, AGS-GNN is the only algorithm that we know of that explicitly controls homophily in the sampled subgraph through similar and diverse neighborhood samples. For diverse neighborhood sampling, we employ submodularity, which was not used in this context prior to our work. The sampling distribution is pre-computed and highly parallel, achieving the desired scalability. Using an extensive dataset consisting of 35 small ($\le$ 100K nodes) and large (>100K nodes) homophilic and heterophilic graphs, we demonstrate the superiority of AGS-GNN compare to the current approaches in the literature. AGS-GNN achieves comparable test accuracy to the best-performing heterophilic GNNs, even outperforming methods using the entire graph for node classification. AGS-GNN also converges faster compared to methods that sample neighborhoods randomly, and can be incorporated into existing GNN models that employ node or graph sampling.
V2W-BERT: A Framework for Effective Hierarchical Multiclass Classification of Software Vulnerabilities
Feb 23, 2021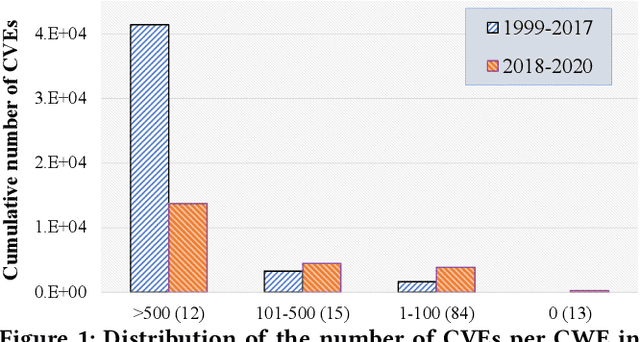

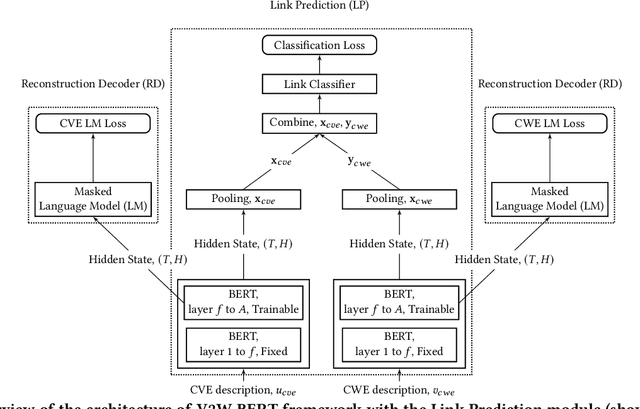
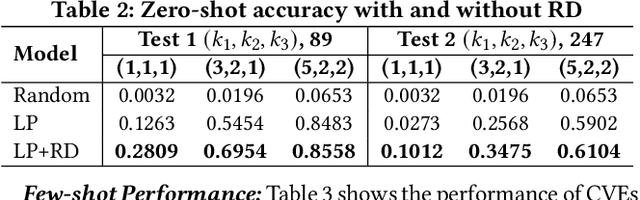
Weaknesses in computer systems such as faults, bugs and errors in the architecture, design or implementation of software provide vulnerabilities that can be exploited by attackers to compromise the security of a system. Common Weakness Enumerations (CWE) are a hierarchically designed dictionary of software weaknesses that provide a means to understand software flaws, potential impact of their exploitation, and means to mitigate these flaws. Common Vulnerabilities and Exposures (CVE) are brief low-level descriptions that uniquely identify vulnerabilities in a specific product or protocol. Classifying or mapping of CVEs to CWEs provides a means to understand the impact and mitigate the vulnerabilities. Since manual mapping of CVEs is not a viable option, automated approaches are desirable but challenging. We present a novel Transformer-based learning framework (V2W-BERT) in this paper. By using ideas from natural language processing, link prediction and transfer learning, our method outperforms previous approaches not only for CWE instances with abundant data to train, but also rare CWE classes with little or no data to train. Our approach also shows significant improvements in using historical data to predict links for future instances of CVEs, and therefore, provides a viable approach for practical applications. Using data from MITRE and National Vulnerability Database, we achieve up to 97% prediction accuracy for randomly partitioned data and up to 94% prediction accuracy in temporally partitioned data. We believe that our work will influence the design of better methods and training models, as well as applications to solve increasingly harder problems in cybersecurity.