 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
REMOD: Relation Extraction for Modeling Online Discourse
Feb 22, 2021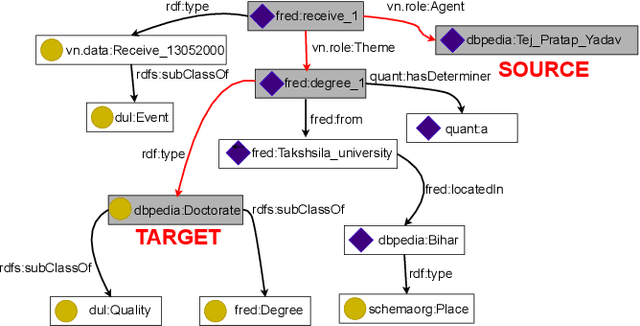
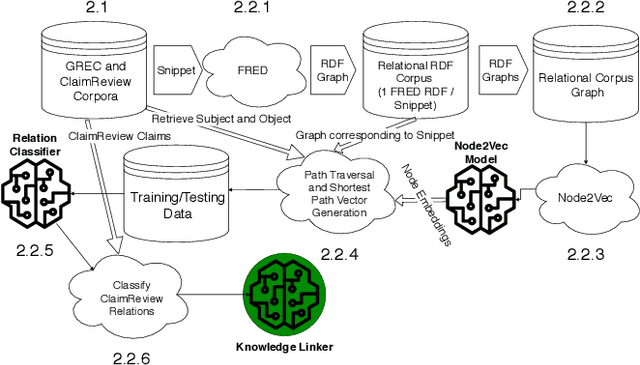

The enormous amount of discourse taking place online poses challenges to the functioning of a civil and informed public sphere. Efforts to standardize online discourse data, such as ClaimReview, are making available a wealth of new data about potentially inaccurate claims, reviewed by third-party fact-checkers. These data could help shed light on the nature of online discourse, the role of political elites in amplifying it, and its implications for the integrity of the online information ecosystem. Unfortunately, the semi-structured nature of much of this data presents significant challenges when it comes to modeling and reasoning about online discourse. A key challenge is relation extraction, which is the task of determining the semantic relationships between named entities in a claim. Here we develop a novel supervised learning method for relation extraction that combines graph embedding techniques with path traversal on semantic dependency graphs. Our approach is based on the intuitive observation that knowledge of the entities along the path between the subject and object of a triple (e.g. Washington,_D.C.}, and United_States_of_America) provides useful information that can be leveraged for extracting its semantic relation (i.e. capitalOf). As an example of a potential application of this technique for modeling online discourse, we show that our method can be integrated into a pipeline to reason about potential misinformation claims.
HONEM: Network Embedding Using Higher-Order Patterns in Sequential Data
Aug 15, 2019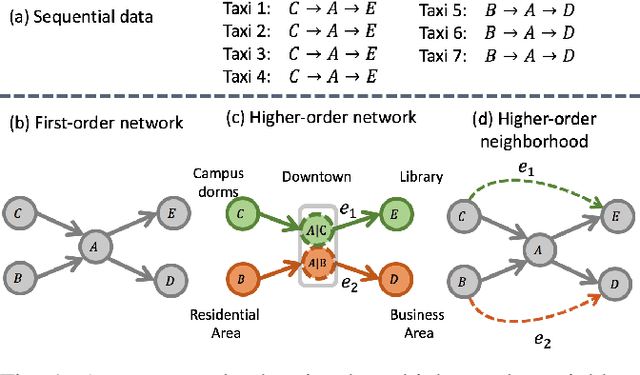
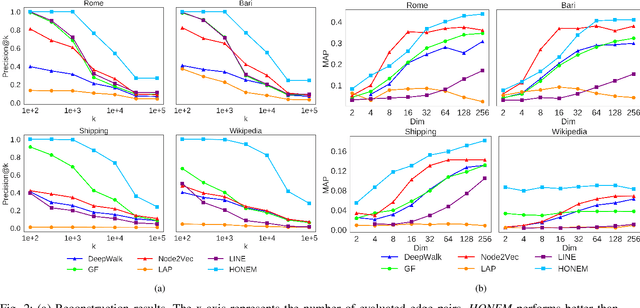
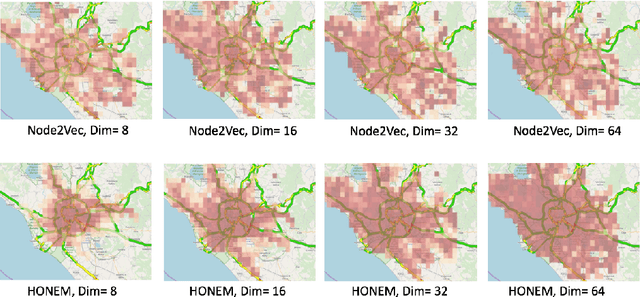
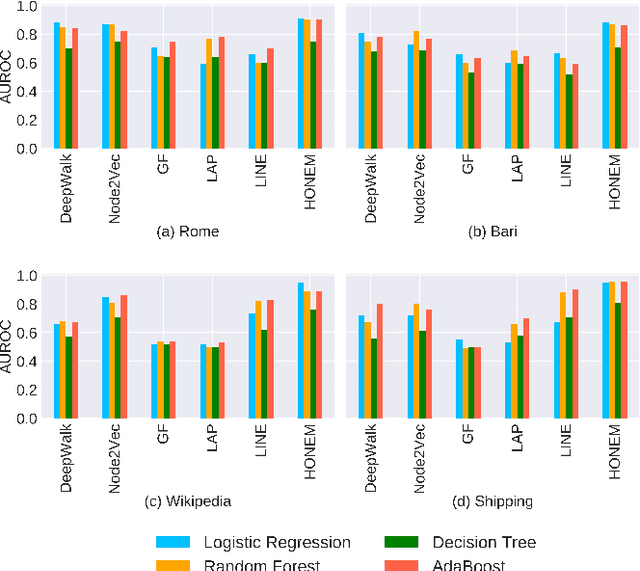
Representation learning offers a powerful alternative to the oft painstaking process of manual feature engineering, and as a result, has enjoyed considerable success in recent years. This success is especially striking in the context of graph mining, since networks can take advantage of vast troves of sequential data to encode information about interactions between entities of interest. But how do we learn embeddings on networks that have higher-order and sequential dependencies? Existing network embedding methods naively assume the Markovian property (first-order dependency) for node interactions, which may not capture the time-dependent and longer-range underlying complex interactions of the raw data. To address the limitation of current methods, we propose a network embedding method for higher-order networks (HON). We demonstrate that the higher-order network embedding (HONEM) method is able to extract higher-order dependencies from HON to construct the higher-order neighborhood matrix of the network, while existing methods are not able to capture these higher-order dependencies. We show that our method outperforms other state-of-the-art methods in node classification, network reconstruction, link prediction, and visualization.
Finding Streams in Knowledge Graphs to Support Fact Checking
Aug 24, 2017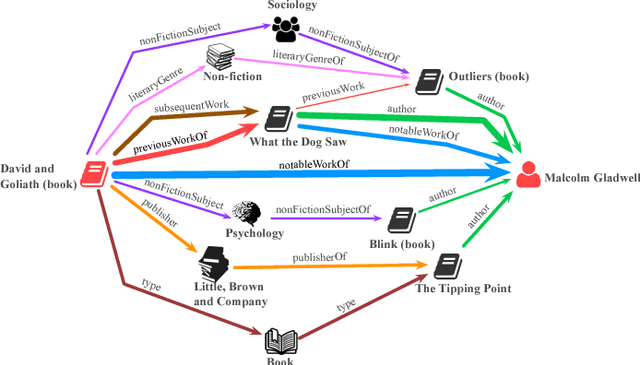
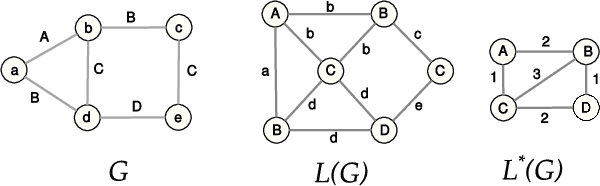

The volume and velocity of information that gets generated online limits current journalistic practices to fact-check claims at the same rate. Computational approaches for fact checking may be the key to help mitigate the risks of massive misinformation spread. Such approaches can be designed to not only be scalable and effective at assessing veracity of dubious claims, but also to boost a human fact checker's productivity by surfacing relevant facts and patterns to aid their analysis. To this end, we present a novel, unsupervised network-flow based approach to determine the truthfulness of a statement of fact expressed in the form of a (subject, predicate, object) triple. We view a knowledge graph of background information about real-world entities as a flow network, and knowledge as a fluid, abstract commodity. We show that computational fact checking of such a triple then amounts to finding a "knowledge stream" that emanates from the subject node and flows toward the object node through paths connecting them. Evaluation on a range of real-world and hand-crafted datasets of facts related to entertainment, business, sports, geography and more reveals that this network-flow model can be very effective in discerning true statements from false ones, outperforming existing algorithms on many test cases. Moreover, the model is expressive in its ability to automatically discover several useful path patterns and surface relevant facts that may help a human fact checker corroborate or refute a claim.
Gendered Conversation in a Social Game-Streaming Platform
Nov 22, 2016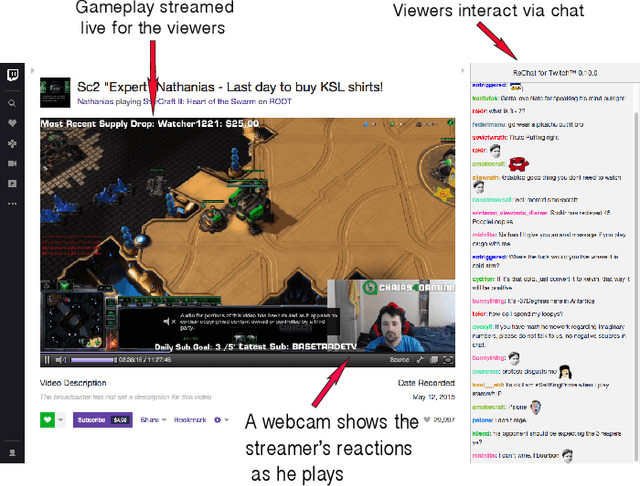

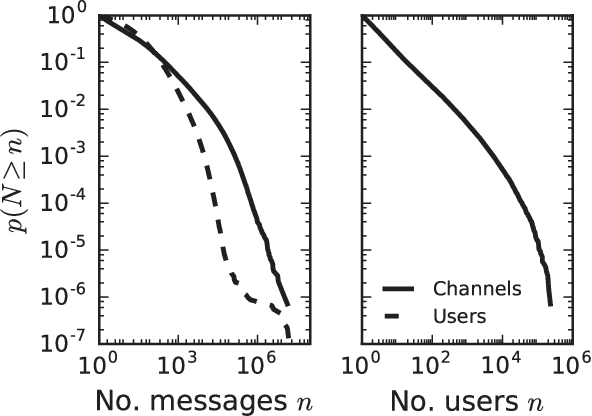
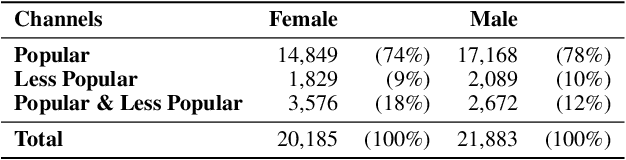
Online social media and games are increasingly replacing offline social activities. Social media is now an indispensable mode of communication; online gaming is not only a genuine social activity but also a popular spectator sport. With support for anonymity and larger audiences, online interaction shrinks social and geographical barriers. Despite such benefits, social disparities such as gender inequality persist in online social media. In particular, online gaming communities have been criticized for persistent gender disparities and objectification. As gaming evolves into a social platform, persistence of gender disparity is a pressing question. Yet, there are few large-scale, systematic studies of gender inequality and objectification in social gaming platforms. Here we analyze more than one billion chat messages from Twitch, a social game-streaming platform, to study how the gender of streamers is associated with the nature of conversation. Using a combination of computational text analysis methods, we show that gendered conversation and objectification is prevalent in chats. Female streamers receive significantly more objectifying comments while male streamers receive more game-related comments. This difference is more pronounced for popular streamers. There also exists a large number of users who post only on female or male streams. Employing a neural vector-space embedding (paragraph vector) method, we analyze gendered chat messages and create prediction models that (i) identify the gender of streamers based on messages posted in the channel and (ii) identify the gender a viewer prefers to watch based on their chat messages. Our findings suggest that disparities in social game-streaming platforms is a nuanced phenomenon that involves the gender of streamers as well as those who produce gendered and game-related conversation.