 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Representations for Convergent Approximation of Distributional HJB Equations
Mar 07, 2025In reinforcement learning (RL), the long-term behavior of decision-making policies is evaluated based on their average returns. Distributional RL has emerged, presenting techniques for learning return distributions, which provide additional statistics for evaluating policies, incorporating risk-sensitive considerations. When the passage of time cannot naturally be divided into discrete time increments, researchers have studied the continuous-time RL (CTRL) problem, where agent states and decisions evolve continuously. In this setting, the Hamilton-Jacobi-Bellman (HJB) equation is well established as the characterization of the expected return, and many solution methods exist. However, the study of distributional RL in the continuous-time setting is in its infancy. Recent work has established a distributional HJB (DHJB) equation, providing the first characterization of return distributions in CTRL. These equations and their solutions are intractable to solve and represent exactly, requiring novel approximation techniques. This work takes strides towards this end, establishing conditions on the method of parameterizing return distributions under which the DHJB equation can be approximately solved. Particularly, we show that under a certain topological property of the mapping between statistics learned by a distributional RL algorithm and corresponding distributions, approximation of these statistics leads to close approximations of the solution of the DHJB equation. Concretely, we demonstrate that the quantile representation common in distributional RL satisfies this topological property, certifying an efficient approximation algorithm for continuous-time distributional RL.
Topological mapping for traversability-aware long-range navigation in off-road terrain
Oct 02, 2024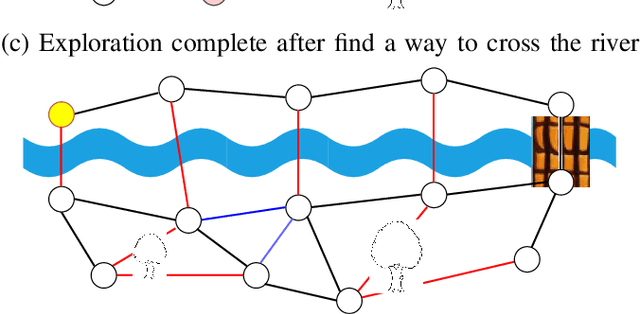

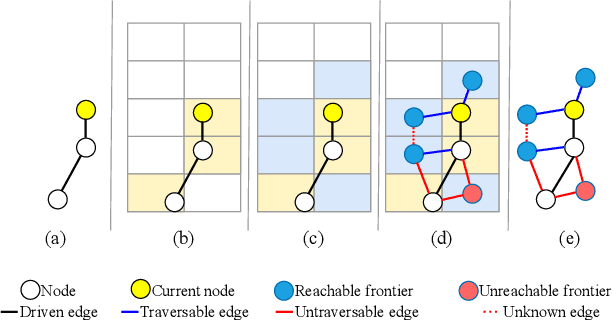
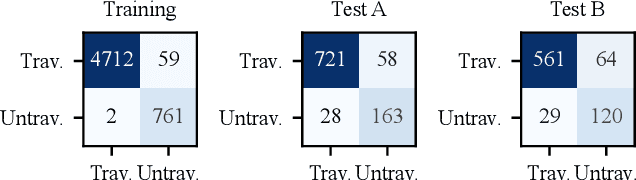
Autonomous robots navigating in off-road terrain like forests open new opportunities for automation. While off-road navigation has been studied, existing work often relies on clearly delineated pathways. We present a method allowing for long-range planning, exploration and low-level control in unknown off-trail forest terrain, using vision and GPS only. We represent outdoor terrain with a topological map, which is a set of panoramic snapshots connected with edges containing traversability information. A novel traversability analysis method is demonstrated, predicting the existence of a safe path towards a target in an image. Navigating between nodes is done using goal-conditioned behavior cloning, leveraging the power of a pretrained vision transformer. An exploration planner is presented, efficiently covering an unknown off-road area with unknown traversability using a frontiers-based approach. The approach is successfully deployed to autonomously explore two 400 meters squared forest sites unseen during training, in difficult conditions for navigation.