 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Financial Reasoning via Deterministic Fact Ledgers and Adversarial Low-Latency Hallucination Detector
Mar 04, 2026Standard Retrieval-Augmented Generation (RAG) architectures fail in high-stakes financial domains due to two fundamental limitations: the inherent arithmetic incompetence of Large Language Models (LLMs) and the distributional semantic conflation of dense vector retrieval (e.g., mapping ``Net Income'' to ``Net Sales'' due to contextual proximity). In deterministic domains, a 99% accuracy rate yields 0% operational trust. To achieve zero-hallucination financial reasoning, we introduce the Verifiable Numerical Reasoning Agent (VeNRA). VeNRA shifts the RAG paradigm from retrieving probabilistic text to retrieving deterministic variables via a strictly typed Universal Fact Ledger (UFL), mathematically bounded by a novel Double-Lock Grounding algorithm. Recognizing that upstream parsing anomalies inevitably occur, we introduce the VeNRA Sentinel: a 3-billion parameter SLM trained to forensically audit Python execution traces with only one token test budget. To train this model, we avoid traditional generative hallucination datasets in favor of Adversarial Simulation, programmatically sabotaging golden financial records to simulate production-level ``Ecological Errors'' (e.g., Logic Code Lies and Numeric Neighbor Traps). Finally, to optimize the Sentinel under strict latency budgets, we utilize a single-pass classification paradigm with optional post thinking for debug. We identify the phenomenon of Loss Dilution in Reverse-Chain-of-Thought training and present a novel, OOM-safe Micro-Chunking loss algorithm to stabilize gradients under extreme differential penalization.
Beyond Static Datasets: Robust Offline Policy Optimization via Vetted Synthetic Transitions
Jan 26, 2026Offline Reinforcement Learning (ORL) holds immense promise for safety-critical domains like industrial robotics, where real-time environmental interaction is often prohibitive. A primary obstacle in ORL remains the distributional shift between the static dataset and the learned policy, which typically mandates high degrees of conservatism that can restrain potential policy improvements. We present MoReBRAC, a model-based framework that addresses this limitation through Uncertainty-Aware latent synthesis. Instead of relying solely on the fixed data, MoReBRAC utilizes a dual-recurrent world model to synthesize high-fidelity transitions that augment the training manifold. To ensure the reliability of this synthetic data, we implement a hierarchical uncertainty pipeline integrating Variational Autoencoder (VAE) manifold detection, model sensitivity analysis, and Monte Carlo (MC) dropout. This multi-layered filtering process guarantees that only transitions residing within high-confidence regions of the learned dynamics are utilized. Our results on D4RL Gym-MuJoCo benchmarks reveal significant performance gains, particularly in ``random'' and ``suboptimal'' data regimes. We further provide insights into the role of the VAE as a geometric anchor and discuss the distributional trade-offs encountered when learning from near-optimal datasets.
Sequential Modeling of Complex Marine Navigation: Case Study on a Passenger Vessel (Student Abstract)
Mar 20, 2024



The maritime industry's continuous commitment to sustainability has led to a dedicated exploration of methods to reduce vessel fuel consumption. This paper undertakes this challenge through a machine learning approach, leveraging a real-world dataset spanning two years of a ferry in west coast Canada. Our focus centers on the creation of a time series forecasting model given the dynamic and static states, actions, and disturbances. This model is designed to predict dynamic states based on the actions provided, subsequently serving as an evaluative tool to assess the proficiency of the ferry's operation under the captain's guidance. Additionally, it lays the foundation for future optimization algorithms, providing valuable feedback on decision-making processes. To facilitate future studies, our code is available at \url{https://github.com/pagand/model_optimze_vessel/tree/AAAI}
Deep Reinforcement Learning-based Intelligent Traffic Signal Controls with Optimized CO2 emissions
Oct 23, 2023Nowadays, transportation networks face the challenge of sub-optimal control policies that can have adverse effects on human health, the environment, and contribute to traffic congestion. Increased levels of air pollution and extended commute times caused by traffic bottlenecks make intersection traffic signal controllers a crucial component of modern transportation infrastructure. Despite several adaptive traffic signal controllers in literature, limited research has been conducted on their comparative performance. Furthermore, despite carbon dioxide (CO2) emissions' significance as a global issue, the literature has paid limited attention to this area. In this report, we propose EcoLight, a reward shaping scheme for reinforcement learning algorithms that not only reduces CO2 emissions but also achieves competitive results in metrics such as travel time. We compare the performance of tabular Q-Learning, DQN, SARSA, and A2C algorithms using metrics such as travel time, CO2 emissions, waiting time, and stopped time. Our evaluation considers multiple scenarios that encompass a range of road users (trucks, buses, cars) with varying pollution levels.
Fuel Consumption Prediction for a Passenger Ferry using Machine Learning and In-service Data: A Comparative Study
Oct 23, 2023



As the importance of eco-friendly transportation increases, providing an efficient approach for marine vessel operation is essential. Methods for status monitoring with consideration to the weather condition and forecasting with the use of in-service data from ships requires accurate and complete models for predicting the energy efficiency of a ship. The models need to effectively process all the operational data in real-time. This paper presents models that can predict fuel consumption using in-service data collected from a passenger ship. Statistical and domain-knowledge methods were used to select the proper input variables for the models. These methods prevent over-fitting, missing data, and multicollinearity while providing practical applicability. Prediction models that were investigated include multiple linear regression (MLR), decision tree approach (DT), an artificial neural network (ANN), and ensemble methods. The best predictive performance was from a model developed using the XGboost technique which is a boosting ensemble approach. \rvv{Our code is available on GitHub at \url{https://github.com/pagand/model_optimze_vessel/tree/OE} for future research.
* 20 pages, 11 figures, 7 tables
LeTFuser: Light-weight End-to-end Transformer-Based Sensor Fusion for Autonomous Driving with Multi-Task Learning
Oct 19, 2023



In end-to-end autonomous driving, the utilization of existing sensor fusion techniques for imitation learning proves inadequate in challenging situations that involve numerous dynamic agents. To address this issue, we introduce LeTFuser, a transformer-based algorithm for fusing multiple RGB-D camera representations. To perform perception and control tasks simultaneously, we utilize multi-task learning. Our model comprises of two modules, the first being the perception module that is responsible for encoding the observation data obtained from the RGB-D cameras. It carries out tasks such as semantic segmentation, semantic depth cloud mapping (SDC), and traffic light state recognition. Our approach employs the Convolutional vision Transformer (CvT) \cite{wu2021cvt} to better extract and fuse features from multiple RGB cameras due to local and global feature extraction capability of convolution and transformer modules, respectively. Following this, the control module undertakes the decoding of the encoded characteristics together with supplementary data, comprising a rough simulator for static and dynamic environments, as well as various measurements, in order to anticipate the waypoints associated with a latent feature space. We use two methods to process these outputs and generate the vehicular controls (e.g. steering, throttle, and brake) levels. The first method uses a PID algorithm to follow the waypoints on the fly, whereas the second one directly predicts the control policy using the measurement features and environmental state. We evaluate the model and conduct a comparative analysis with recent models on the CARLA simulator using various scenarios, ranging from normal to adversarial conditions, to simulate real-world scenarios. Our code is available at \url{https://github.com/pagand/e2etransfuser/tree/cvpr-w} to facilitate future studies.
Adaptive Model Learning of Neural Networks with UUB Stability for Robot Dynamic Estimation
Oct 26, 2022



Since batch algorithms suffer from lack of proficiency in confronting model mismatches and disturbances, this contribution proposes an adaptive scheme based on continuous Lyapunov function for online robot dynamic identification. This paper suggests stable updating rules to drive neural networks inspiring from model reference adaptive paradigm. Network structure consists of three parallel self-driving neural networks which aim to estimate robot dynamic terms individually. Lyapunov candidate is selected to construct energy surface for a convex optimization framework. Learning rules are driven directly from Lyapunov functions to make the derivative negative. Finally, experimental results on 3-DOF Phantom Omni Haptic device demonstrate efficiency of the proposed method.
* 6 pages, 12 figures
Online Probabilistic Model Identification using Adaptive Recursive MCMC
Oct 23, 2022



The Bayesian paradigm provides a rigorous framework for estimating the whole probability distribution over unknown parameters, but due to high computational costs, its online application can be difficult. We propose the Adaptive Recursive Markov Chain Monte Carlo (ARMCMC) method, which calculates the complete probability density function of model parameters while alleviating the drawbacks of traditional online methods. These flaws include being limited to Gaussian noise, being solely applicable to linear in the parameters (LIP) systems, and having persisting excitation requirements (PE). A variable jump distribution based on a temporal forgetting factor (TFF) is proposed in ARMCMC. The TFF can be utilized in many dynamical systems as an effective way to adaptively present the forgetting factor instead of a constant hyperparameter. The particular jump distribution has tailored towards hybrid/multi-modal systems that enables inferences among modes by providing a trade-off between exploitation and exploration. These trade-off are adjusted based on parameter evolution rate. In comparison to traditional MCMC techniques, we show that ARMCMC requires fewer samples to obtain the same accuracy and reliability. We show our method on two challenging benchmarks: parameter estimation in a soft bending actuator and the Hunt-Crossley dynamic model. We also compare our method with recursive least squares and the particle filter, and show that our technique has significantly more accurate point estimates as well as a decrease in tracking error of the value of interest.
DMODE: Differential Monocular Object Distance Estimation Module without Class Specific Information
Oct 23, 2022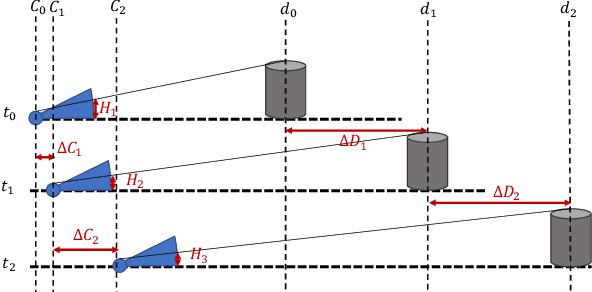
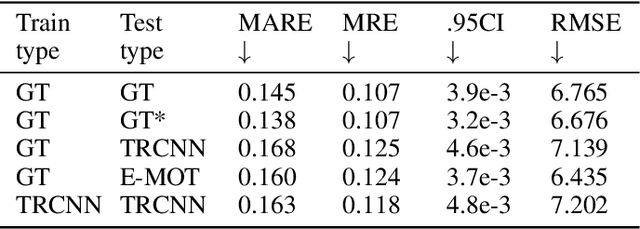
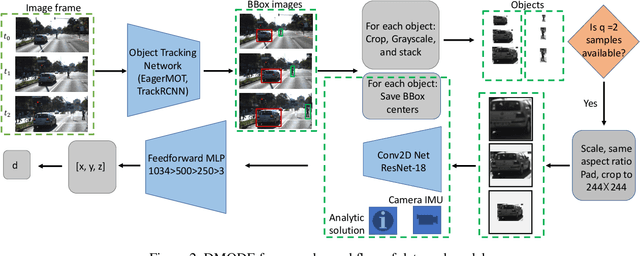
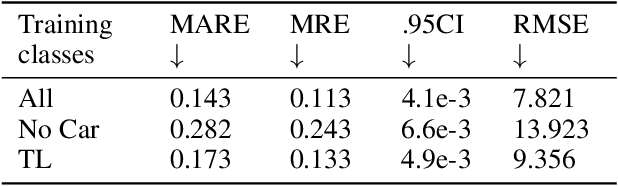
Using a single camera to estimate the distances of objects reduces costs compared to stereo-vision and LiDAR. Although monocular distance estimation has been studied in the literature, previous methods mostly rely on knowing an object's class in some way. This can result in deteriorated performance for dataset with multi-class objects and objects with an undefined class. In this paper, we aim to overcome the potential downsides of class-specific approaches, and provide an alternative technique called DMODE that does not require any information relating to its class. Using differential approaches, we combine the changes in an object's size over time together with the camera's motion to estimate the object's distance. Since DMODE is class agnostic method, it is easily adaptable to new environments. Therefore, it is able to maintain performance across different object detectors, and be easily adapted to new object classes. We tested our model across different scenarios of training and testing on the KITTI MOTS dataset's ground-truth bounding box annotations, and bounding box outputs of TrackRCNN and EagerMOT. The instantaneous change of bounding box sizes and camera position are then used to obtain an object's position in 3D without measuring its detection source or class properties. Our results show that we are able to outperform traditional alternatives methods e.g. IPM \cite{TuohyIPM}, SVR \cite{svr}, and \cite{zhu2019learning} in test environments with multi-class object distance detections.