 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS2Edge: Towards Energy-Efficient and Crisp Edge Detection with Multi-Scale Residual Learning in SNNs
Nov 05, 2025Edge detection with Artificial Neural Networks (ANNs) has achieved remarkable prog\-ress but faces two major challenges. First, it requires pre-training on large-scale extra data and complex designs for prior knowledge, leading to high energy consumption. Second, the predicted edges perform poorly in crispness and heavily rely on post-processing. Spiking Neural Networks (SNNs), as third generation neural networks, feature quantization and spike-driven computation mechanisms. They inherently provide a strong prior for edge detection in an energy-efficient manner, while its quantization mechanism helps suppress texture artifact interference around true edges, improving prediction crispness. However, the resulting quantization error inevitably introduces sparse edge discontinuities, compromising further enhancement of crispness. To address these challenges, we propose MS2Edge, the first SNN-based model for edge detection. At its core, we build a novel spiking backbone named MS2ResNet that integrates multi-scale residual learning to recover missing boundary lines and generate crisp edges, while combining I-LIF neurons with Membrane-based Deformed Shortcut (MDS) to mitigate quantization errors. The model is complemented by a Spiking Multi-Scale Upsample Block (SMSUB) for detail reconstruction during upsampling and a Membrane Average Decoding (MAD) method for effective integration of edge maps across multiple time steps. Experimental results demonstrate that MS2Edge outperforms ANN-based methods and achieves state-of-the-art performance on the BSDS500, NYUDv2, BIPED, PLDU, and PLDM datasets without pre-trained backbones, while maintaining ultralow energy consumption and generating crisp edge maps without post-processing.
SpikSSD: Better Extraction and Fusion for Object Detection with Spiking Neuron Networks
Jan 25, 2025



As the third generation of neural networks, Spiking Neural Networks (SNNs) have gained widespread attention due to their low energy consumption and biological interpretability. Recently, SNNs have made considerable advancements in computer vision. However, efficiently conducting feature extraction and fusion under the spiking characteristics of SNNs for object detection remains a pressing challenge. To address this problem, we propose the SpikSSD, a novel Spiking Single Shot Multibox Detector. Specifically, we design a full-spiking backbone network, MDS-ResNet, which effectively adjusts the membrane synaptic input distribution at each layer, achieving better spiking feature extraction. Additionally, for spiking feature fusion, we introduce the Spiking Bi-direction Fusion Module (SBFM), which for the first time realizes bi-direction fusion of spiking features, enhancing the multi-scale detection capability of the model. Experimental results show that SpikSSD achieves 40.8\% mAP on the GEN1 dataset, 76.3\% and 52.4\% mAP@0.5 on VOC 2007 and COCO 2017 datasets respectively with the lowest firing rate, outperforming existing SNN-based approaches at ultralow energy consumption. This work sets a new benchmark for future research in SNN-based object detection. Our code is publicly available in https://github.com/yimeng-fan/SpikSSD.
Cycle Pixel Difference Network for Crisp Edge Detection
Sep 06, 2024
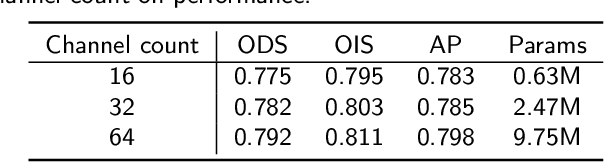


Edge detection, as a fundamental task in computer vision, has garnered increasing attention. The advent of deep learning has significantly advanced this field. However, recent deep learning-based methods which rely on large-scale pre-trained weights cannot be trained from scratch, with very limited research addressing this issue. This paper proposes a novel cycle pixel difference convolution (CPDC), which effectively integrates image gradient information with modern convolution operations. Based on the CPDC, we develop a U-shape encoder-decoder model named CPD-Net, which is a purely end-to-end network. Additionally, to address the issue of edge thickness produced by most existing methods, we construct a multi-scale information enhancement module (MSEM) to enhance the discriminative ability of the model, thereby generating crisp and clean contour maps. Comprehensive experiments conducted on three standard benchmarks demonstrate that our method achieves competitive performance on the BSDS500 dataset (ODS=0.813), NYUD-V2 (ODS=0.760), and BIPED dataset (ODS=0.898). Our approach provides a novel perspective for addressing these challenges in edge detection.
Learning to utilize gradient information for crisp edge detection
Jun 09, 2024Edge detection is a fundamental task in computer vision and it has made great progress under the development of deep convolutional neural networks (DCNNs), some of them have achieved a beyond human-level performance. However, recent top-performing edge detection methods tend to generate thick and blurred edge lines. In this work, we propose an effective method to solve this problem. Our approach consists of a lightweight pre-trained backbone, multi-scale contextual enhancement module aggregating gradient information (MCGI), boundary correction module (BCM), and boundary refinement module (BRM). In addition to this, we construct a novel hybrid loss function based on the Tversky index for solving the issue of imbalanced pixel distribution. We test our method on three standard benchmarks and the experiment results illustrate that our method improves the visual effect of edge maps and achieves a top performance among several state-of-the-art methods on the BSDS500 dataset (ODS F-score in standard evaluation is 0.829, in crispness evaluation is 0.720), NYUD-V2 dataset (ODS F-score in standard evaluation is 0.768, in crispness evaluation is \textbf{0.546}), and BIPED dataset (ODS F-score in standard evaluation is 0.903).
SFOD: Spiking Fusion Object Detector
Mar 22, 2024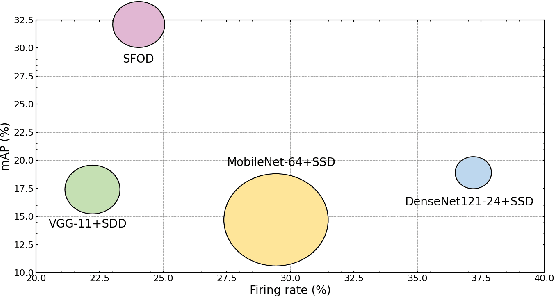
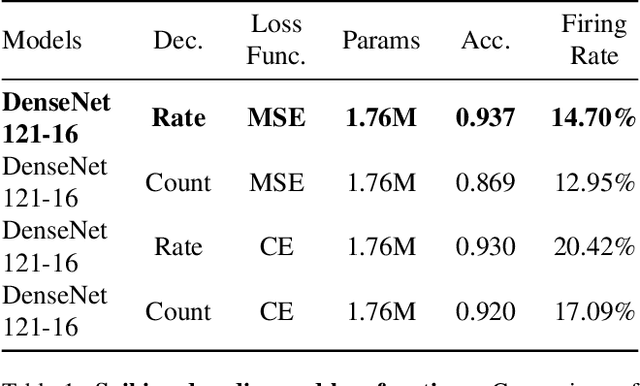
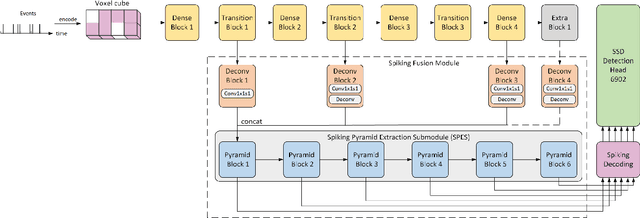
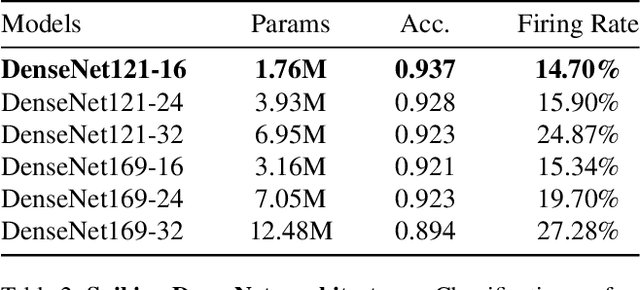
Event cameras, characterized by high temporal resolution, high dynamic range, low power consumption, and high pixel bandwidth, offer unique capabilities for object detection in specialized contexts. Despite these advantages, the inherent sparsity and asynchrony of event data pose challenges to existing object detection algorithms. Spiking Neural Networks (SNNs), inspired by the way the human brain codes and processes information, offer a potential solution to these difficulties. However, their performance in object detection using event cameras is limited in current implementations. In this paper, we propose the Spiking Fusion Object Detector (SFOD), a simple and efficient approach to SNN-based object detection. Specifically, we design a Spiking Fusion Module, achieving the first-time fusion of feature maps from different scales in SNNs applied to event cameras. Additionally, through integrating our analysis and experiments conducted during the pretraining of the backbone network on the NCAR dataset, we delve deeply into the impact of spiking decoding strategies and loss functions on model performance. Thereby, we establish state-of-the-art classification results based on SNNs, achieving 93.7\% accuracy on the NCAR dataset. Experimental results on the GEN1 detection dataset demonstrate that the SFOD achieves a state-of-the-art mAP of 32.1\%, outperforming existing SNN-based approaches. Our research not only underscores the potential of SNNs in object detection with event cameras but also propels the advancement of SNNs. Code is available at https://github.com/yimeng-fan/SFOD.
Sequential Modeling of Complex Marine Navigation: Case Study on a Passenger Vessel (Student Abstract)
Mar 20, 2024



The maritime industry's continuous commitment to sustainability has led to a dedicated exploration of methods to reduce vessel fuel consumption. This paper undertakes this challenge through a machine learning approach, leveraging a real-world dataset spanning two years of a ferry in west coast Canada. Our focus centers on the creation of a time series forecasting model given the dynamic and static states, actions, and disturbances. This model is designed to predict dynamic states based on the actions provided, subsequently serving as an evaluative tool to assess the proficiency of the ferry's operation under the captain's guidance. Additionally, it lays the foundation for future optimization algorithms, providing valuable feedback on decision-making processes. To facilitate future studies, our code is available at \url{https://github.com/pagand/model_optimze_vessel/tree/AAAI}