 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocFormer: Enabling Transformers to Perform Temporal Moment Localization on Long Untrimmed Videos With a Feature Sampling Approach
Paper and Code
Dec 19, 2021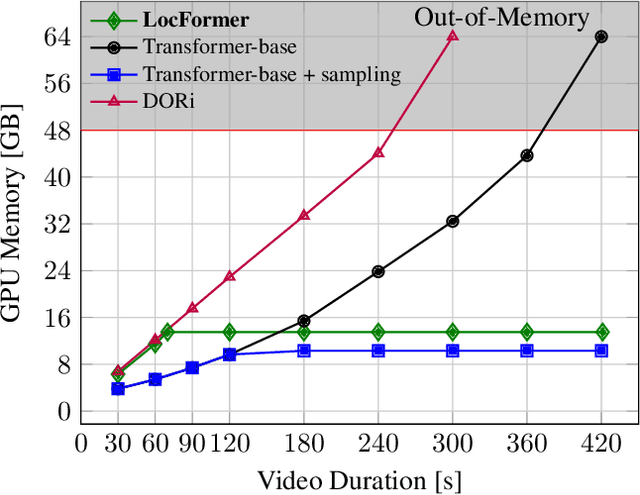
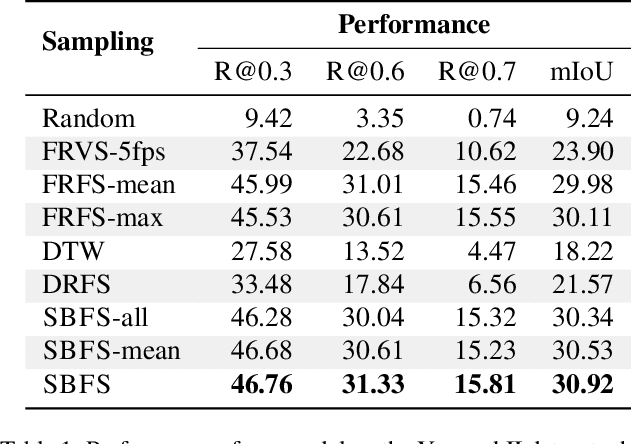
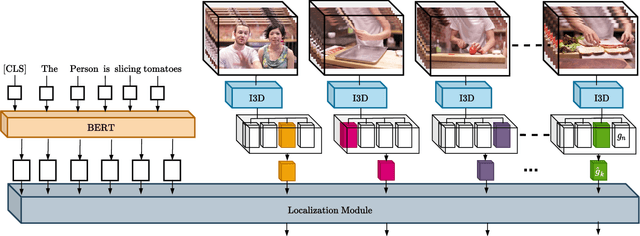
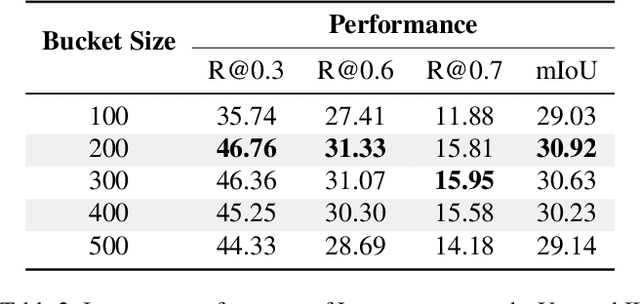
We propose LocFormer, a Transformer-based model for video grounding which operates at a constant memory footprint regardless of the video length, i.e. number of frames. LocFormer is designed for tasks where it is necessary to process the entire long video and at its core lie two main contributions. First, our model incorporates a new sampling technique that splits the input feature sequence into a fixed number of sections and selects a single feature per section using a stochastic approach, which allows us to obtain a feature sample set that is representative of the video content for the task at hand while keeping the memory footprint constant. Second, we propose a modular design that separates functionality, enabling us to learn an inductive bias via supervising the self-attention heads, while also effectively leveraging pre-trained text and video encoders. We test our proposals on relevant benchmark datasets for video grounding, showing that not only LocFormer can achieve excellent results including state-of-the-art performance on YouCookII, but also that our sampling technique is more effective than competing counterparts and that it consistently improves the performance of prior work, by up to 3.13\% in the mean temporal IoU, ultimately leading to a new state-of-the-art performance on Charades-STA.