 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical and Step-Layer-Wise Tuning of Attention Specialty for Multi-Instance Synthesis in Diffusion Transformers
Apr 14, 2025Text-to-image (T2I) generation models often struggle with multi-instance synthesis (MIS), where they must accurately depict multiple distinct instances in a single image based on complex prompts detailing individual features. Traditional MIS control methods for UNet architectures like SD v1.5/SDXL fail to adapt to DiT-based models like FLUX and SD v3.5, which rely on integrated attention between image and text tokens rather than text-image cross-attention. To enhance MIS in DiT, we first analyze the mixed attention mechanism in DiT. Our token-wise and layer-wise analysis of attention maps reveals a hierarchical response structure: instance tokens dominate early layers, background tokens in middle layers, and attribute tokens in later layers. Building on this observation, we propose a training-free approach for enhancing MIS in DiT-based models with hierarchical and step-layer-wise attention specialty tuning (AST). AST amplifies key regions while suppressing irrelevant areas in distinct attention maps across layers and steps, guided by the hierarchical structure. This optimizes multimodal interactions by hierarchically decoupling the complex prompts with instance-based sketches. We evaluate our approach using upgraded sketch-based layouts for the T2I-CompBench and customized complex scenes. Both quantitative and qualitative results confirm our method enhances complex layout generation, ensuring precise instance placement and attribute representation in MIS.
Academic Network Representation via Prediction-Sampling Incorporated Tensor Factorization
Apr 11, 2025



Accurate representation to an academic network is of great significance to academic relationship mining like predicting scientific impact. A Latent Factorization of Tensors (LFT) model is one of the most effective models for learning the representation of a target network. However, an academic network is often High-Dimensional and Incomplete (HDI) because the relationships among numerous network entities are impossible to be fully explored, making it difficult for an LFT model to learn accurate representation of the academic network. To address this issue, this paper proposes a Prediction-sampling-based Latent Factorization of Tensors (PLFT) model with two ideas: 1) constructing a cascade LFT architecture to enhance model representation learning ability via learning academic network hierarchical features, and 2) introducing a nonlinear activation-incorporated predicting-sampling strategy to more accurately learn the network representation via generating new academic network data layer by layer. Experimental results from the three real-world academic network datasets show that the PLFT model outperforms existing models when predicting the unexplored relationships among network entities.
Graph Representation Learning via Contrasting Cluster Assignments
Dec 15, 2021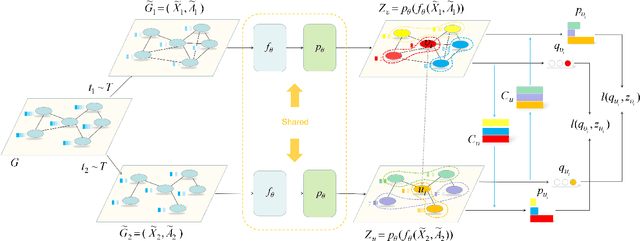



With the rise of contrastive learning, unsupervised graph representation learning has been booming recently, even surpassing the supervised counterparts in some machine learning tasks. Most of existing contrastive models for graph representation learning either focus on maximizing mutual information between local and global embeddings, or primarily depend on contrasting embeddings at node level. However, they are still not exquisite enough to comprehensively explore the local and global views of network topology. Although the former considers local-global relationship, its coarse global information leads to grudging cooperation between local and global views. The latter pays attention to node-level feature alignment, so that the role of global view appears inconspicuous. To avoid falling into these two extreme cases, we propose a novel unsupervised graph representation model by contrasting cluster assignments, called as GRCCA. It is motivated to make good use of local and global information synthetically through combining clustering algorithms and contrastive learning. This not only facilitates the contrastive effect, but also provides the more high-quality graph information. Meanwhile, GRCCA further excavates cluster-level information, which make it get insight to the elusive association between nodes beyond graph topology. Specifically, we first generate two augmented graphs with distinct graph augmentation strategies, then employ clustering algorithms to obtain their cluster assignments and prototypes respectively. The proposed GRCCA further compels the identical nodes from different augmented graphs to recognize their cluster assignments mutually by minimizing a cross entropy loss. To demonstrate its effectiveness, we compare with the state-of-the-art models in three different downstream tasks. The experimental results show that GRCCA has strong competitiveness in most tasks.