 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryBlender: Inter-Shot Consistent and Editable 3D Storyboard with Spatial-temporal Dynamics
Apr 01, 2026Storyboarding is a core skill in visual storytelling for film, animation, and games. However, automating this process requires a system to achieve two properties that current approaches rarely satisfy simultaneously: inter-shot consistency and explicit editability. While 2D diffusion-based generators produce vivid imagery, they often suffer from identity drift along with limited geometric control; conversely, traditional 3D animation workflows are consistent and editable but require expert-heavy, labor-intensive authoring. We present StoryBlender, a grounded 3D storyboard generation framework governed by a Story-centric Reflection Scheme. At its core, we propose the StoryBlender system, which is built on a three-stage pipeline: (1) Semantic-Spatial Grounding, to construct a continuity memory graph to decouple global assets from shot-specific variables for long-horizon consistency; (2) Canonical Asset Materialization, to instantiate entities in a unified coordinate space to maintain visual identity; and (3) Spatial-Temporal Dynamics, to achieve layout design and cinematic evolution through visual metrics. By orchestrating multiple agents in a hierarchical manner within a verification loop, StoryBlender iteratively self-corrects spatial hallucinations via engine-verified feedback. The resulting native 3D scenes support direct, precise editing of cameras and visual assets while preserving unwavering multi-shot continuity. Experiments demonstrate that StoryBlender significantly improves consistency and editability over both diffusion-based and 3D-grounded baselines. Code, data, and demonstration video will be available on https://engineeringai-lab.github.io/StoryBlender/
3DXTalker: Unifying Identity, Lip Sync, Emotion, and Spatial Dynamics in Expressive 3D Talking Avatars
Feb 12, 2026Audio-driven 3D talking avatar generation is increasingly important in virtual communication, digital humans, and interactive media, where avatars must preserve identity, synchronize lip motion with speech, express emotion, and exhibit lifelike spatial dynamics, collectively defining a broader objective of expressivity. However, achieving this remains challenging due to insufficient training data with limited subject identities, narrow audio representations, and restricted explicit controllability. In this paper, we propose 3DXTalker, an expressive 3D talking avatar through data-curated identity modeling, audio-rich representations, and spatial dynamics controllability. 3DXTalker enables scalable identity modeling via 2D-to-3D data curation pipeline and disentangled representations, alleviating data scarcity and improving identity generalization. Then, we introduce frame-wise amplitude and emotional cues beyond standard speech embeddings, ensuring superior lip synchronization and nuanced expression modulation. These cues are unified by a flow-matching-based transformer for coherent facial dynamics. Moreover, 3DXTalker also enables natural head-pose motion generation while supporting stylized control via prompt-based conditioning. Extensive experiments show that 3DXTalker integrates lip synchronization, emotional expression, and head-pose dynamics within a unified framework, achieves superior performance in 3D talking avatar generation.
Beyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025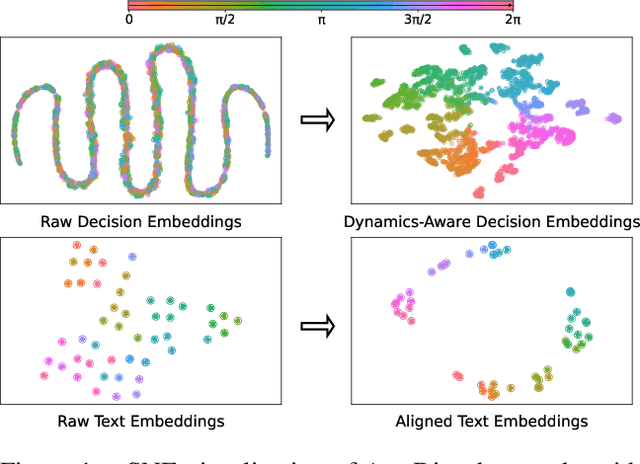

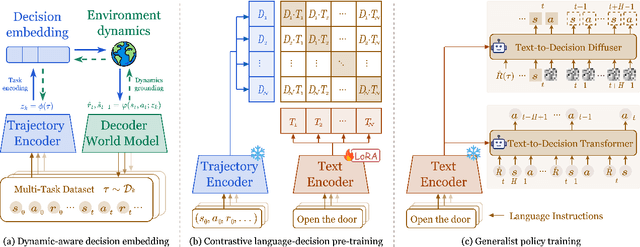
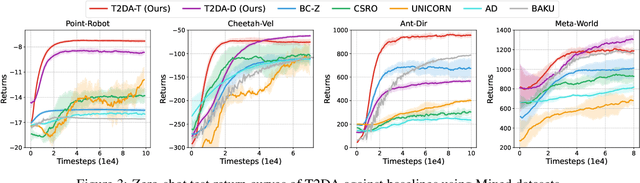
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
Hierarchical and Step-Layer-Wise Tuning of Attention Specialty for Multi-Instance Synthesis in Diffusion Transformers
Apr 14, 2025Text-to-image (T2I) generation models often struggle with multi-instance synthesis (MIS), where they must accurately depict multiple distinct instances in a single image based on complex prompts detailing individual features. Traditional MIS control methods for UNet architectures like SD v1.5/SDXL fail to adapt to DiT-based models like FLUX and SD v3.5, which rely on integrated attention between image and text tokens rather than text-image cross-attention. To enhance MIS in DiT, we first analyze the mixed attention mechanism in DiT. Our token-wise and layer-wise analysis of attention maps reveals a hierarchical response structure: instance tokens dominate early layers, background tokens in middle layers, and attribute tokens in later layers. Building on this observation, we propose a training-free approach for enhancing MIS in DiT-based models with hierarchical and step-layer-wise attention specialty tuning (AST). AST amplifies key regions while suppressing irrelevant areas in distinct attention maps across layers and steps, guided by the hierarchical structure. This optimizes multimodal interactions by hierarchically decoupling the complex prompts with instance-based sketches. We evaluate our approach using upgraded sketch-based layouts for the T2I-CompBench and customized complex scenes. Both quantitative and qualitative results confirm our method enhances complex layout generation, ensuring precise instance placement and attribute representation in MIS.
T$^3$-S2S: Training-free Triplet Tuning for Sketch to Scene Generation
Dec 18, 2024Scene generation is crucial to many computer graphics applications. Recent advances in generative AI have streamlined sketch-to-image workflows, easing the workload for artists and designers in creating scene concept art. However, these methods often struggle for complex scenes with multiple detailed objects, sometimes missing small or uncommon instances. In this paper, we propose a Training-free Triplet Tuning for Sketch-to-Scene (T3-S2S) generation after reviewing the entire cross-attention mechanism. This scheme revitalizes the existing ControlNet model, enabling effective handling of multi-instance generations, involving prompt balance, characteristics prominence, and dense tuning. Specifically, this approach enhances keyword representation via the prompt balance module, reducing the risk of missing critical instances. It also includes a characteristics prominence module that highlights TopK indices in each channel, ensuring essential features are better represented based on token sketches. Additionally, it employs dense tuning to refine contour details in the attention map, compensating for instance-related regions. Experiments validate that our triplet tuning approach substantially improves the performance of existing sketch-to-image models. It consistently generates detailed, multi-instance 2D images, closely adhering to the input prompts and enhancing visual quality in complex multi-instance scenes. Code is available at https://github.com/chaos-sun/t3s2s.git.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Mar 08, 2024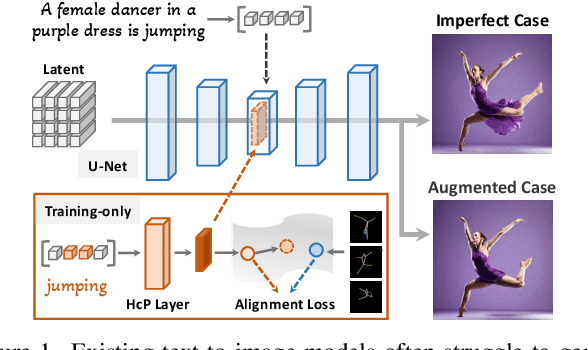
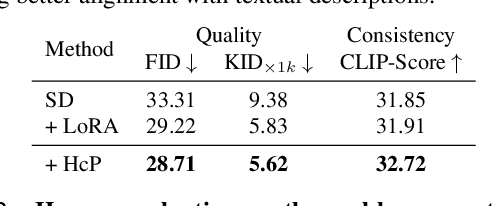
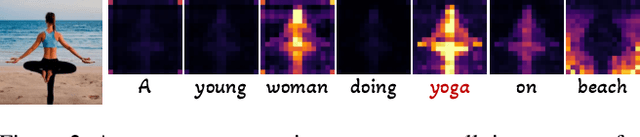
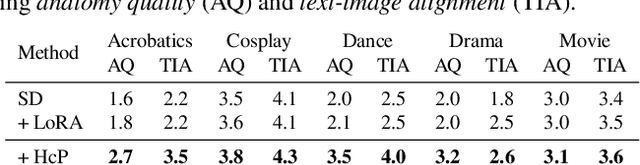
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs.Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls -- human-centric priors such as pose or depth maps -- during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage, essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning, we introduce scale-aware and step-wise constraints within the diffusion process, according to an in-depth analysis of the cross-attention layer. Extensive experiments show that our method largely improves over state-of-the-art text-to-image models to synthesize high-quality human images based on user-written prompts. Project page: \url{https://hcplayercvpr2024.github.io}.
Learning Informative Latent Representation for Quantum State Tomography
Sep 30, 2023Quantum state tomography (QST) is the process of reconstructing the complete state of a quantum system (mathematically described as a density matrix) through a series of different measurements. These measurements are performed on a number of identical copies of the quantum system, with outcomes gathered as frequencies. QST aims to recover the density matrix and the corresponding properties of the quantum state from the measured frequencies. Although an informationally complete set of measurements can specify quantum state accurately in an ideal scenario with a large number of identical copies, both measurements and identical copies are restricted and imperfect in practical scenarios, making QST highly ill-posed. The conventional QST methods usually assume adequate or accurate measured frequencies or rely on manually designed regularizers to handle the ill-posed reconstruction problem, suffering from limited applications in realistic scenarios. Recent advances in deep neural networks (DNNs) led to the emergence of deep learning (DL) in QST. However, existing DL-based QST approaches often employ generic DNN models that are not optimized for imperfect conditions of QST. In this paper, we propose a transformer-based autoencoder architecture tailored for QST with imperfect measurement data. Our method leverages a transformer-based encoder to extract an informative latent representation (ILR) from imperfect measurement data and employs a decoder to predict the quantum states based on the ILR. We anticipate that the high-dimensional ILR will capture more comprehensive information about quantum states. To achieve this, we conduct pre-training of the encoder using a pretext task that involves reconstructing high-quality frequencies from measured frequencies. Extensive simulations and experiments demonstrate the remarkable ability of the ILR in dealing with imperfect measurement data in QST.
Attention-Based Transformer Networks for Quantum State Tomography
May 09, 2023Neural networks have been actively explored for quantum state tomography (QST) due to their favorable expressibility. To further enhance the efficiency of reconstructing quantum states, we explore the similarity between language modeling and quantum state tomography and propose an attention-based QST method that utilizes the Transformer network to capture the correlations between measured results from different measurements. Our method directly retrieves the density matrices of quantum states from measured statistics, with the assistance of an integrated loss function that helps minimize the difference between the actual states and the retrieved states. Then, we systematically trace different impacts within a bag of common training strategies involving various parameter adjustments on the attention-based QST method. Combining these techniques, we establish a robust baseline that can efficiently reconstruct pure and mixed quantum states. Furthermore, by comparing the performance of three popular neural network architectures (FCNs, CNNs, and Transformer), we demonstrate the remarkable expressiveness of attention in learning density matrices from measured statistics.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 20233D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.