 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Entropy Model is All You Need for Learned Video Compression
Paper and Code
Apr 13, 2021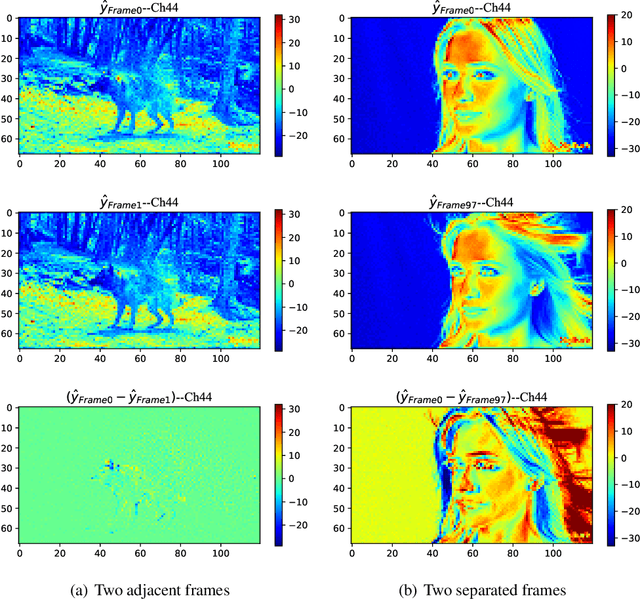

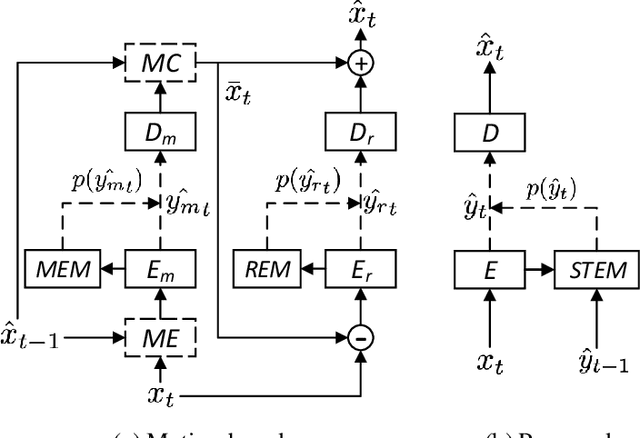
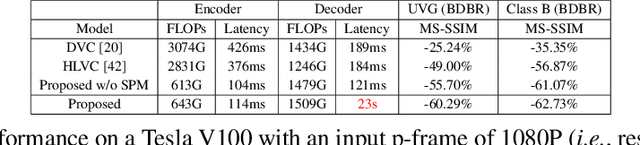
The framework of dominant learned video compression methods is usually composed of motion prediction modules as well as motion vector and residual image compression modules, suffering from its complex structure and error propagation problem. Approaches have been proposed to reduce the complexity by replacing motion prediction modules with implicit flow networks. Error propagation aware training strategy is also proposed to alleviate incremental reconstruction errors from previously decoded frames. Although these methods have brought some improvement, little attention has been paid to the framework itself. Inspired by the success of learned image compression through simplifying the framework with a single deep neural network, it is natural to expect a better performance in video compression via a simple yet appropriate framework. Therefore, we propose a framework to directly compress raw-pixel frames (rather than residual images), where no extra motion prediction module is required. Instead, an entropy model is used to estimate the spatiotemporal redundancy in a latent space rather than pixel level, which significantly reduces the complexity of the framework. Specifically, the whole framework is a compression module, consisting of a unified auto-encoder which produces identically distributed latents for all frames, and a spatiotemporal entropy estimation model to minimize the entropy of these latents. Experiments showed that the proposed method outperforms state-of-the-art (SOTA) performance under the metric of multiscale structural similarity (MS-SSIM) and achieves competitive results under the metric of PSNR.