 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Task-aware Contrastive Local Descriptor Selection Strategy for Few-shot Learning between inter class and intra class
Aug 12, 2024Few-shot image classification aims to classify novel classes with few labeled samples. Recent research indicates that deep local descriptors have better representational capabilities. These studies recognize the impact of background noise on classification performance. They typically filter query descriptors using all local descriptors in the support classes or engage in bidirectional selection between local descriptors in support and query sets. However, they ignore the fact that background features may be useful for the classification performance of specific tasks. This paper proposes a novel task-aware contrastive local descriptor selection network (TCDSNet). First, we calculate the contrastive discriminative score for each local descriptor in the support class, and select discriminative local descriptors to form a support descriptor subset. Finally, we leverage support descriptor subsets to adaptively select discriminative query descriptors for specific tasks. Extensive experiments demonstrate that our method outperforms state-of-the-art methods on both general and fine-grained datasets.
DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training
Aug 01, 2024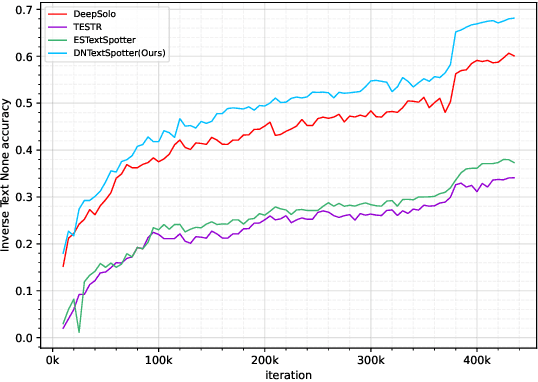
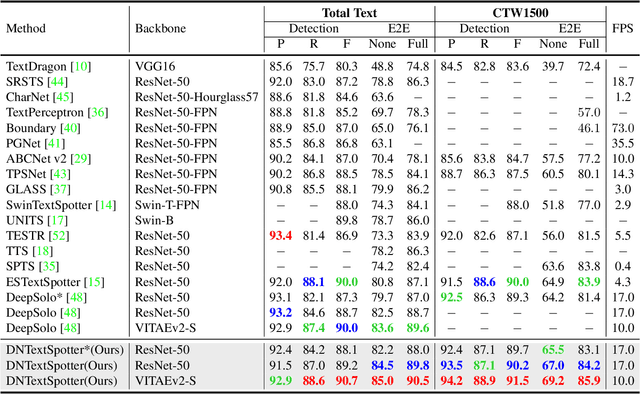
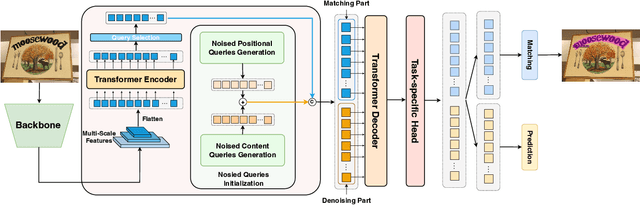
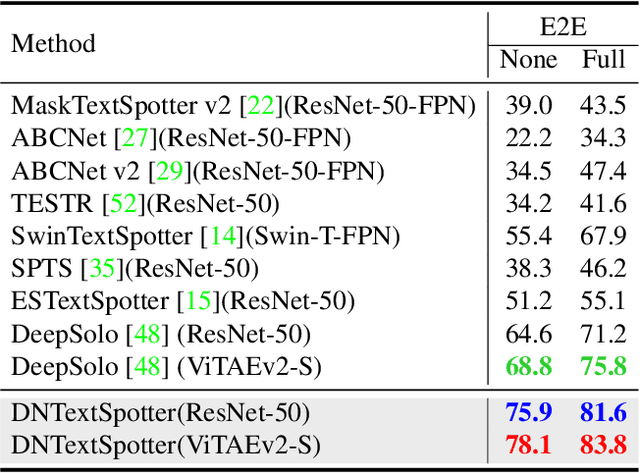
More and more end-to-end text spotting methods based on Transformer architecture have demonstrated superior performance. These methods utilize a bipartite graph matching algorithm to perform one-to-one optimal matching between predicted objects and actual objects. However, the instability of bipartite graph matching can lead to inconsistent optimization targets, thereby affecting the training performance of the model. Existing literature applies denoising training to solve the problem of bipartite graph matching instability in object detection tasks. Unfortunately, this denoising training method cannot be directly applied to text spotting tasks, as these tasks need to perform irregular shape detection tasks and more complex text recognition tasks than classification. To address this issue, we propose a novel denoising training method (DNTextSpotter) for arbitrary-shaped text spotting. Specifically, we decompose the queries of the denoising part into noised positional queries and noised content queries. We use the four Bezier control points of the Bezier center curve to generate the noised positional queries. For the noised content queries, considering that the output of the text in a fixed positional order is not conducive to aligning position with content, we employ a masked character sliding method to initialize noised content queries, thereby assisting in the alignment of text content and position. To improve the model's perception of the background, we further utilize an additional loss function for background characters classification in the denoising training part.Although DNTextSpotter is conceptually simple, it outperforms the state-of-the-art methods on four benchmarks (Total-Text, SCUT-CTW1500, ICDAR15, and Inverse-Text), especially yielding an improvement of 11.3% against the best approach in Inverse-Text dataset.
Guiding ChatGPT to Generate Salient Domain Summaries
Jun 03, 2024



ChatGPT is instruct-tuned to generate general and human-expected content to align with human preference through Reinforcement Learning from Human Feedback (RLHF), meanwhile resulting in generated responses not salient enough. Therefore, in this case, ChatGPT may fail to satisfy domain requirements in zero-shot settings, leading to poor ROUGE scores. Inspired by the In-Context Learning (ICL) and retelling ability of ChatGPT, this paper proposes PADS, a \textbf{P}ipeline for \textbf{A}ssisting ChatGPT in \textbf{D}omain \textbf{S}ummarization. PADS consists of a retriever to retrieve similar examples from corpora and a rank model to rerank the multiple candidate summaries generated by ChatGPT. Specifically, given an inference document, we first retrieve an in-context demonstration via the retriever. Then, we require ChatGPT to generate $k$ candidate summaries for the inference document at a time under the guidance of the retrieved demonstration. Finally, the rank model independently scores the $k$ candidate summaries according to their quality and selects the optimal one. We extensively explore dense and sparse retrieval methods to select effective demonstrations for reference and efficiently train the rank model to reflect the quality of candidate summaries for each given summarized document. Additionally, PADS contains merely 400M trainable parameters originating from the rank model and we merely collect 2.5k data to train it. We evaluate PADS on five datasets from different domains, and the result indicates that each module in PADS is committed to effectively guiding ChatGPT to generate salient summaries fitting different domain requirements. Specifically, in the popular summarization dataset Gigaword, PADS achieves over +8 gain on ROUGE-L, compared with the naive ChatGPT in the zero-shot setting. \footnote{Our code are available at \url{https://github.com/jungao1106/PADS}}