 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIP-MM: Pre-Integrating Prompt Information into Visual Encoding via Existing MLLM Structures
Oct 30, 2024

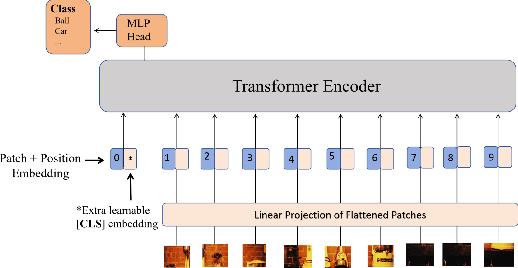

The Multimodal Large Language Models (MLLMs) have activated the capabilitiesof Large Language Models (LLMs) in solving visual-language tasks by integratingvisual information. The prevailing approach in existing MLLMs involvesemploying an image encoder to extract visual features, converting thesefeatures into visual tokens via an adapter, and then integrating them with theprompt into the LLM. However, because the process of image encoding isprompt-agnostic, the extracted visual features only provide a coarsedescription of the image, impossible to focus on the requirements of theprompt. On one hand, it is easy for image features to lack information aboutthe prompt-specified objects, resulting in unsatisfactory responses. On theother hand, the visual features contain a large amount of irrelevantinformation, which not only increases the burden on memory but also worsens thegeneration effectiveness. To address the aforementioned issues, we propose\textbf{PIP-MM}, a framework that \textbf{P}re-\textbf{I}ntegrates\textbf{P}rompt information into the visual encoding process using existingmodules of MLLMs. Specifically, We utilize the frozen LLM in the MLLM tovectorize the input prompt, which summarizes the requirements of the prompt.Then, we input the prompt vector into our trained Multi-Layer Perceptron (MLP)to align with the visual input requirements, and subsequently replace the classembedding in the image encoder. Since our model only requires adding atrainable MLP, it can be applied to any MLLM. To validate the effectiveness ofPIP-MM, we conducted experiments on multiple benchmarks. Automated evaluationmetrics and manual assessments demonstrate the strong performance of PIP-MM.Particularly noteworthy is that our model maintains excellent generationresults even when half of the visual tokens are reduced.
DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training
Aug 01, 2024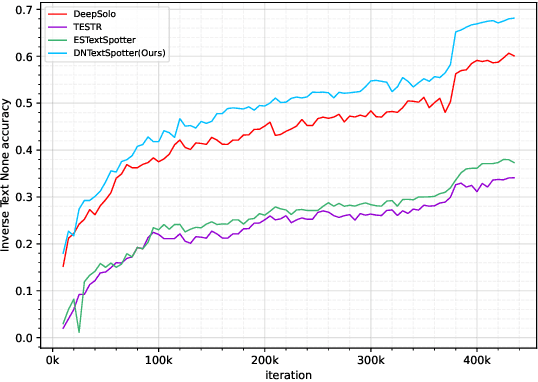
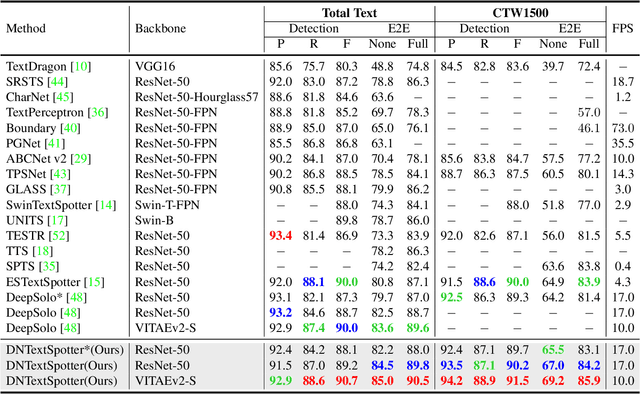
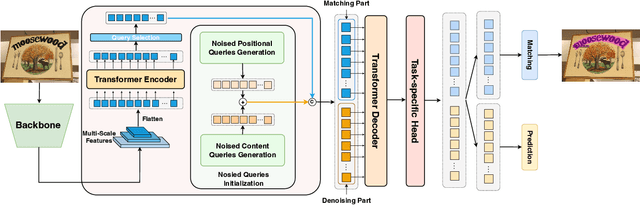
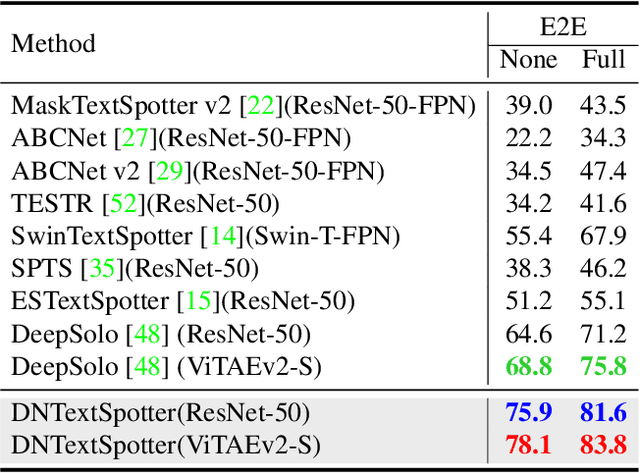
More and more end-to-end text spotting methods based on Transformer architecture have demonstrated superior performance. These methods utilize a bipartite graph matching algorithm to perform one-to-one optimal matching between predicted objects and actual objects. However, the instability of bipartite graph matching can lead to inconsistent optimization targets, thereby affecting the training performance of the model. Existing literature applies denoising training to solve the problem of bipartite graph matching instability in object detection tasks. Unfortunately, this denoising training method cannot be directly applied to text spotting tasks, as these tasks need to perform irregular shape detection tasks and more complex text recognition tasks than classification. To address this issue, we propose a novel denoising training method (DNTextSpotter) for arbitrary-shaped text spotting. Specifically, we decompose the queries of the denoising part into noised positional queries and noised content queries. We use the four Bezier control points of the Bezier center curve to generate the noised positional queries. For the noised content queries, considering that the output of the text in a fixed positional order is not conducive to aligning position with content, we employ a masked character sliding method to initialize noised content queries, thereby assisting in the alignment of text content and position. To improve the model's perception of the background, we further utilize an additional loss function for background characters classification in the denoising training part.Although DNTextSpotter is conceptually simple, it outperforms the state-of-the-art methods on four benchmarks (Total-Text, SCUT-CTW1500, ICDAR15, and Inverse-Text), especially yielding an improvement of 11.3% against the best approach in Inverse-Text dataset.