 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Text Retrieval with Binary and Continuous Label Supervision
Paper and Code
Oct 20, 2022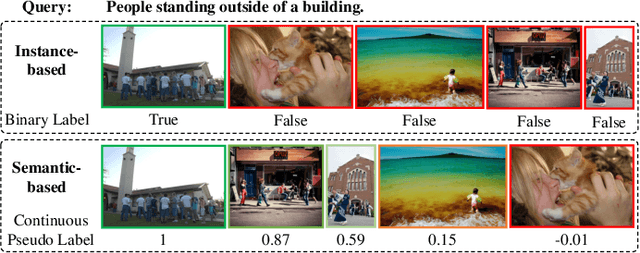
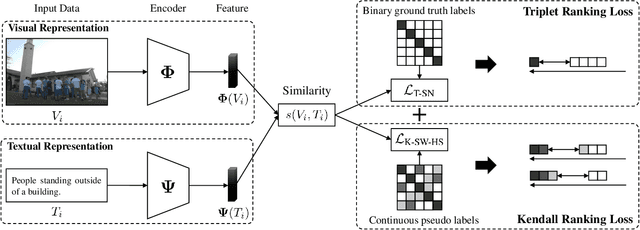
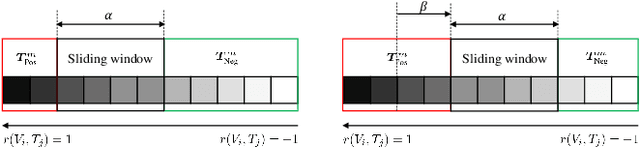
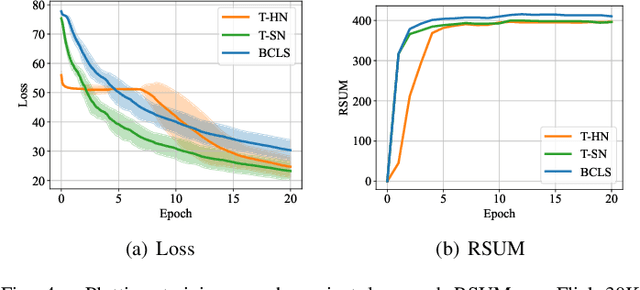
Most image-text retrieval work adopts binary labels indicating whether a pair of image and text matches or not. Such a binary indicator covers only a limited subset of image-text semantic relations, which is insufficient to represent relevance degrees between images and texts described by continuous labels such as image captions. The visual-semantic embedding space obtained by learning binary labels is incoherent and cannot fully characterize the relevance degrees. In addition to the use of binary labels, this paper further incorporates continuous pseudo labels (generally approximated by text similarity between captions) to indicate the relevance degrees. To learn a coherent embedding space, we propose an image-text retrieval framework with Binary and Continuous Label Supervision (BCLS), where binary labels are used to guide the retrieval model to learn limited binary correlations, and continuous labels are complementary to the learning of image-text semantic relations. For the learning of binary labels, we improve the common Triplet ranking loss with Soft Negative mining (Triplet-SN) to improve convergence. For the learning of continuous labels, we design Kendall ranking loss inspired by Kendall rank correlation coefficient (Kendall), which improves the correlation between the similarity scores predicted by the retrieval model and the continuous labels. To mitigate the noise introduced by the continuous pseudo labels, we further design Sliding Window sampling and Hard Sample mining strategy (SW-HS) to alleviate the impact of noise and reduce the complexity of our framework to the same order of magnitude as the triplet ranking loss. Extensive experiments on two image-text retrieval benchmarks demonstrate that our method can improve the performance of state-of-the-art image-text retrieval models.