 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Visual Semantic Reasoning for Video-Text Retrieval
Jun 16, 2020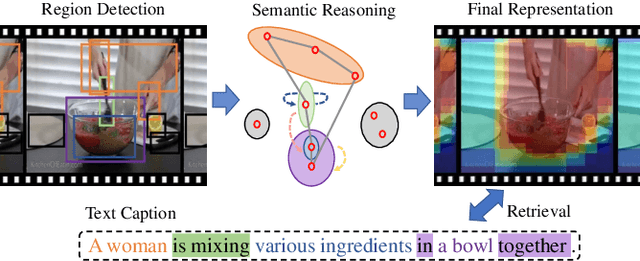

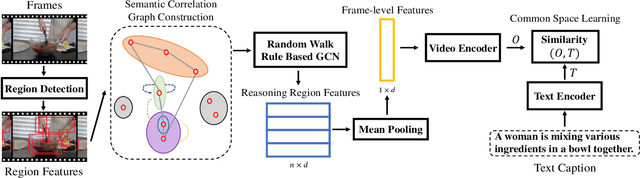

Video retrieval is a challenging research topic bridging the vision and language areas and has attracted broad attention in recent years. Previous works have been devoted to representing videos by directly encoding from frame-level features. In fact, videos consist of various and abundant semantic relations to which existing methods pay less attention. To address this issue, we propose a Visual Semantic Enhanced Reasoning Network (ViSERN) to exploit reasoning between frame regions. Specifically, we consider frame regions as vertices and construct a fully-connected semantic correlation graph. Then, we perform reasoning by novel random walk rule-based graph convolutional networks to generate region features involved with semantic relations. With the benefit of reasoning, semantic interactions between regions are considered, while the impact of redundancy is suppressed. Finally, the region features are aggregated to form frame-level features for further encoding to measure video-text similarity. Extensive experiments on two public benchmark datasets validate the effectiveness of our method by achieving state-of-the-art performance due to the powerful semantic reasoning.