 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbor-aware Instance Refining with Noisy Labels for Cross-Modal Retrieval
Dec 30, 2025In recent years, Cross-Modal Retrieval (CMR) has made significant progress in the field of multi-modal analysis. However, since it is time-consuming and labor-intensive to collect large-scale and well-annotated data, the annotation of multi-modal data inevitably contains some noise. This will degrade the retrieval performance of the model. To tackle the problem, numerous robust CMR methods have been developed, including robust learning paradigms, label calibration strategies, and instance selection mechanisms. Unfortunately, they often fail to simultaneously satisfy model performance ceilings, calibration reliability, and data utilization rate. To overcome the limitations, we propose a novel robust cross-modal learning framework, namely Neighbor-aware Instance Refining with Noisy Labels (NIRNL). Specifically, we first propose Cross-modal Margin Preserving (CMP) to adjust the relative distance between positive and negative pairs, thereby enhancing the discrimination between sample pairs. Then, we propose Neighbor-aware Instance Refining (NIR) to identify pure subset, hard subset, and noisy subset through cross-modal neighborhood consensus. Afterward, we construct different tailored optimization strategies for this fine-grained partitioning, thereby maximizing the utilization of all available data while mitigating error propagation. Extensive experiments on three benchmark datasets demonstrate that NIRNL achieves state-of-the-art performance, exhibiting remarkable robustness, especially under high noise rates.
Deep Reversible Consistency Learning for Cross-modal Retrieval
Jan 10, 2025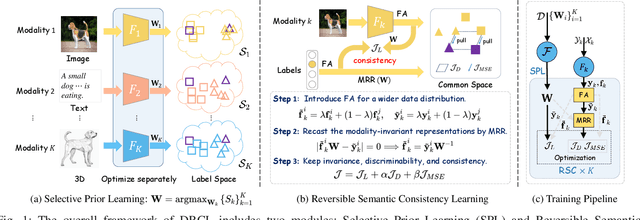
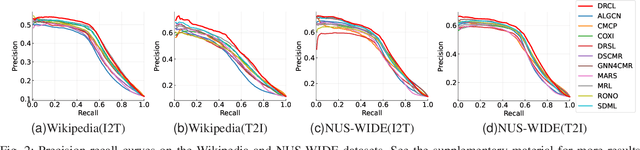
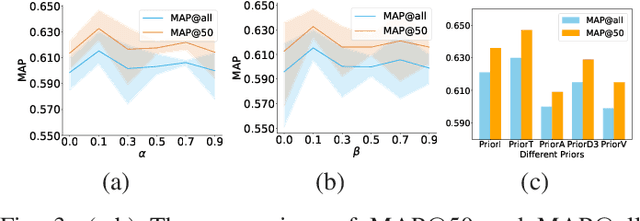
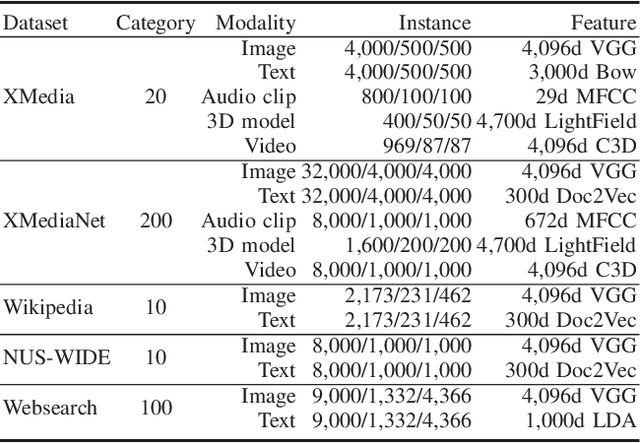
Cross-modal retrieval (CMR) typically involves learning common representations to directly measure similarities between multimodal samples. Most existing CMR methods commonly assume multimodal samples in pairs and employ joint training to learn common representations, limiting the flexibility of CMR. Although some methods adopt independent training strategies for each modality to improve flexibility in CMR, they utilize the randomly initialized orthogonal matrices to guide representation learning, which is suboptimal since they assume inter-class samples are independent of each other, limiting the potential of semantic alignments between sample representations and ground-truth labels. To address these issues, we propose a novel method termed Deep Reversible Consistency Learning (DRCL) for cross-modal retrieval. DRCL includes two core modules, \ie Selective Prior Learning (SPL) and Reversible Semantic Consistency learning (RSC). More specifically, SPL first learns a transformation weight matrix on each modality and selects the best one based on the quality score as the Prior, which greatly avoids blind selection of priors learned from low-quality modalities. Then, RSC employs a Modality-invariant Representation Recasting mechanism (MRR) to recast the potential modality-invariant representations from sample semantic labels by the generalized inverse matrix of the prior. Since labels are devoid of modal-specific information, we utilize the recast features to guide the representation learning, thus maintaining semantic consistency to the fullest extent possible. In addition, a feature augmentation mechanism (FA) is introduced in RSC to encourage the model to learn over a wider data distribution for diversity. Finally, extensive experiments conducted on five widely used datasets and comparisons with 15 state-of-the-art baselines demonstrate the effectiveness and superiority of our DRCL.
Robust Self-Paced Hashing for Cross-Modal Retrieval with Noisy Labels
Jan 03, 2025



Cross-modal hashing (CMH) has appeared as a popular technique for cross-modal retrieval due to its low storage cost and high computational efficiency in large-scale data. Most existing methods implicitly assume that multi-modal data is correctly labeled, which is expensive and even unattainable due to the inevitable imperfect annotations (i.e., noisy labels) in real-world scenarios. Inspired by human cognitive learning, a few methods introduce self-paced learning (SPL) to gradually train the model from easy to hard samples, which is often used to mitigate the effects of feature noise or outliers. It is a less-touched problem that how to utilize SPL to alleviate the misleading of noisy labels on the hash model. To tackle this problem, we propose a new cognitive cross-modal retrieval method called Robust Self-paced Hashing with Noisy Labels (RSHNL), which can mimic the human cognitive process to identify the noise while embracing robustness against noisy labels. Specifically, we first propose a contrastive hashing learning (CHL) scheme to improve multi-modal consistency, thereby reducing the inherent semantic gap. Afterward, we propose center aggregation learning (CAL) to mitigate the intra-class variations. Finally, we propose Noise-tolerance Self-paced Hashing (NSH) that dynamically estimates the learning difficulty for each instance and distinguishes noisy labels through the difficulty level. For all estimated clean pairs, we further adopt a self-paced regularizer to gradually learn hash codes from easy to hard. Extensive experiments demonstrate that the proposed RSHNL performs remarkably well over the state-of-the-art CMH methods.