 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGTUL: A Hypergraph-based Model For Trajectory User Linking
Feb 11, 2025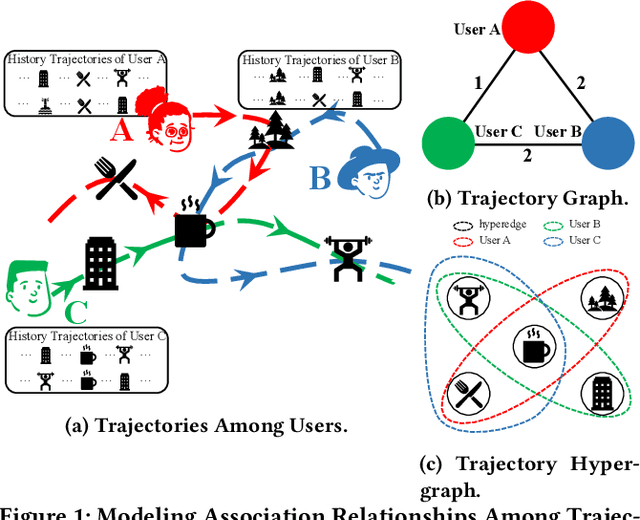
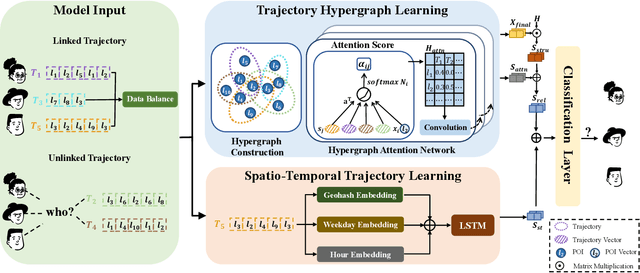

Trajectory User Linking (TUL), which links anonymous trajectories with users who generate them, plays a crucial role in modeling human mobility. Despite significant advancements in this field, existing studies primarily neglect the high-order inter-trajectory relationships, which represent complex associations among multiple trajectories, manifested through multi-location co-occurrence patterns emerging when trajectories intersect at various Points of Interest (POIs). Furthermore, they also overlook the variable influence of POIs on different trajectories, as well as the user class imbalance problem caused by disparities in user activity levels and check-in frequencies. To address these limitations, we propose a novel HyperGraph-based multi-perspective Trajectory User Linking model (HGTUL). Our model learns trajectory representations from both relational and spatio-temporal perspectives: (1) it captures high-order associations among trajectories by constructing a trajectory hypergraph and leverages a hypergraph attention network to learn the variable impact of POIs on trajectories; (2) it models the spatio-temporal characteristics of trajectories by incorporating their temporal and spatial information into a sequential encoder. Moreover, we design a data balancing method to effectively address the user class imbalance problem and experimentally validate its significance in TUL. Extensive experiments on three real-world datasets demonstrate that HGTUL outperforms state-of-the-art baselines, achieving improvements of 2.57%~20.09% and 5.68%~26.00% in ACC@1 and Macro-F1 metrics, respectively.
Cognition-Mode Aware Variational Representation Learning Framework for Knowledge Tracing
Sep 03, 2023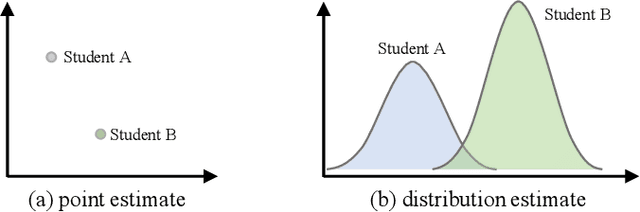
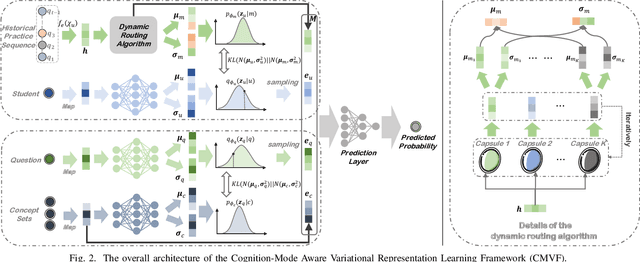
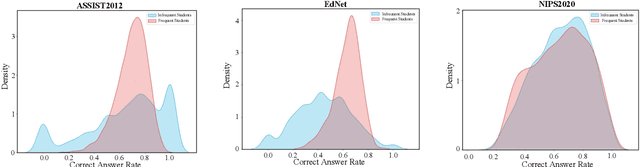
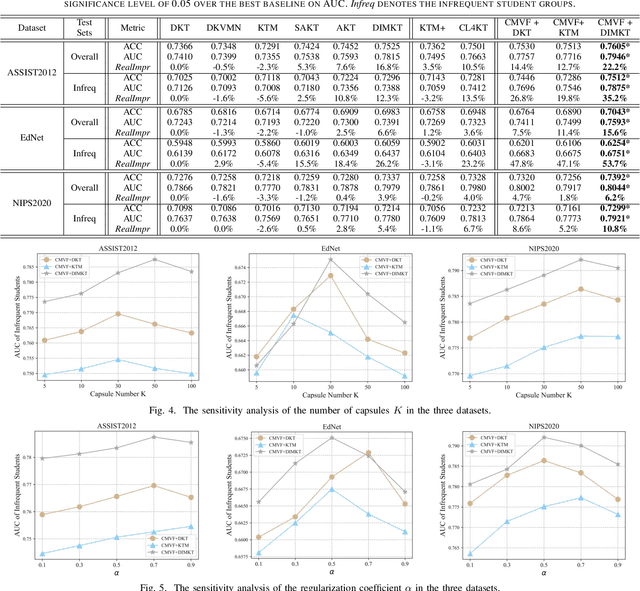
The Knowledge Tracing (KT) task plays a crucial role in personalized learning, and its purpose is to predict student responses based on their historical practice behavior sequence. However, the KT task suffers from data sparsity, which makes it challenging to learn robust representations for students with few practice records and increases the risk of model overfitting. Therefore, in this paper, we propose a Cognition-Mode Aware Variational Representation Learning Framework (CMVF) that can be directly applied to existing KT methods. Our framework uses a probabilistic model to generate a distribution for each student, accounting for uncertainty in those with limited practice records, and estimate the student's distribution via variational inference (VI). In addition, we also introduce a cognition-mode aware multinomial distribution as prior knowledge that constrains the posterior student distributions learning, so as to ensure that students with similar cognition modes have similar distributions, avoiding overwhelming personalization for students with few practice records. At last, extensive experimental results confirm that CMVF can effectively aid existing KT methods in learning more robust student representations. Our code is available at https://github.com/zmy-9/CMVF.
* Accepted by ICDM 2023, 10 pages, 5 figures, 4 tables
Counterfactual Monotonic Knowledge Tracing for Assessing Students' Dynamic Mastery of Knowledge Concepts
Aug 07, 2023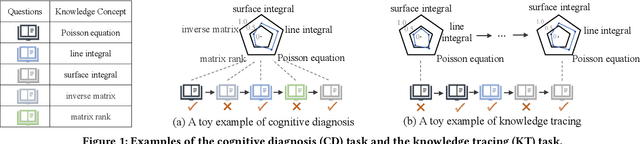
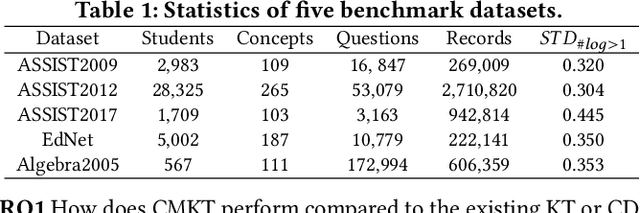
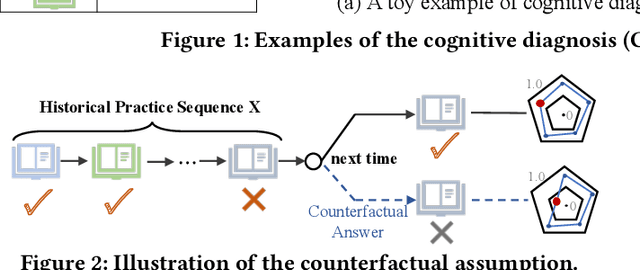
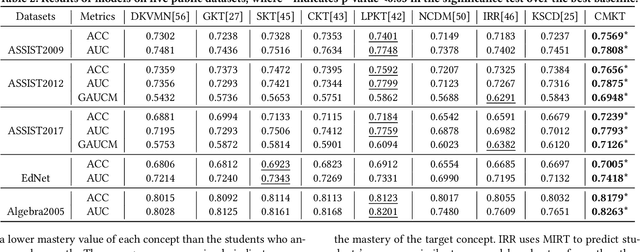
As the core of the Knowledge Tracking (KT) task, assessing students' dynamic mastery of knowledge concepts is crucial for both offline teaching and online educational applications. Since students' mastery of knowledge concepts is often unlabeled, existing KT methods rely on the implicit paradigm of historical practice to mastery of knowledge concepts to students' responses to practices to address the challenge of unlabeled concept mastery. However, purely predicting student responses without imposing specific constraints on hidden concept mastery values does not guarantee the accuracy of these intermediate values as concept mastery values. To address this issue, we propose a principled approach called Counterfactual Monotonic Knowledge Tracing (CMKT), which builds on the implicit paradigm described above by using a counterfactual assumption to constrain the evolution of students' mastery of knowledge concepts.
No Length Left Behind: Enhancing Knowledge Tracing for Modeling Sequences of Excessive or Insufficient Lengths
Aug 07, 2023
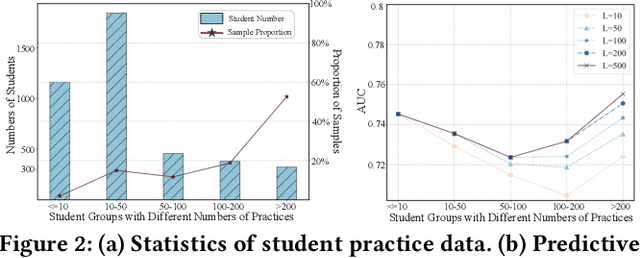
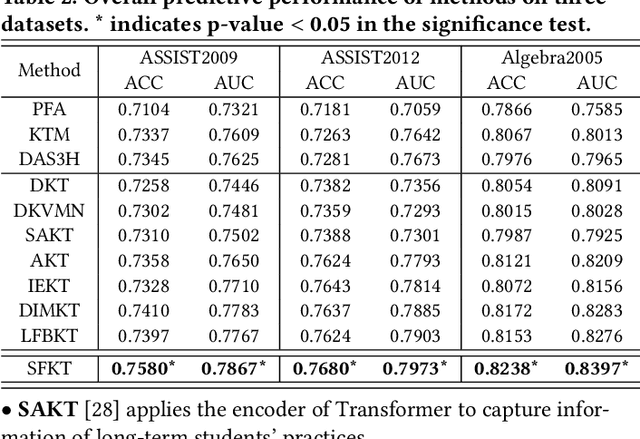
Knowledge tracing (KT) aims to predict students' responses to practices based on their historical question-answering behaviors. However, most current KT methods focus on improving overall AUC, leaving ample room for optimization in modeling sequences of excessive or insufficient lengths. As sequences get longer, computational costs will increase exponentially. Therefore, KT methods usually truncate sequences to an acceptable length, which makes it difficult for models on online service systems to capture complete historical practice behaviors of students with too long sequences. Conversely, modeling students with short practice sequences using most KT methods may result in overfitting due to limited observation samples. To address the above limitations, we propose a model called Sequence-Flexible Knowledge Tracing (SFKT).
Multi-source Education Knowledge Graph Construction and Fusion for College Curricula
May 08, 2023



The field of education has undergone a significant transformation due to the rapid advancements in Artificial Intelligence (AI). Among the various AI technologies, Knowledge Graphs (KGs) using Natural Language Processing (NLP) have emerged as powerful visualization tools for integrating multifaceted information. In the context of university education, the availability of numerous specialized courses and complicated learning resources often leads to inferior learning outcomes for students. In this paper, we propose an automated framework for knowledge extraction, visual KG construction, and graph fusion, tailored for the major of Electronic Information. Furthermore, we perform data analysis to investigate the correlation degree and relationship between courses, rank hot knowledge concepts, and explore the intersection of courses. Our objective is to enhance the learning efficiency of students and to explore new educational paradigms enabled by AI. The proposed framework is expected to enable students to better understand and appreciate the intricacies of their field of study by providing them with a comprehensive understanding of the relationships between the various concepts and courses.
Multi-Factors Aware Dual-Attentional Knowledge Tracing
Aug 10, 2021With the increasing demands of personalized learning, knowledge tracing has become important which traces students' knowledge states based on their historical practices. Factor analysis methods mainly use two kinds of factors which are separately related to students and questions to model students' knowledge states. These methods use the total number of attempts of students to model students' learning progress and hardly highlight the impact of the most recent relevant practices. Besides, current factor analysis methods ignore rich information contained in questions. In this paper, we propose Multi-Factors Aware Dual-Attentional model (MF-DAKT) which enriches question representations and utilizes multiple factors to model students' learning progress based on a dual-attentional mechanism. More specifically, we propose a novel student-related factor which records the most recent attempts on relevant concepts of students to highlight the impact of recent exercises. To enrich questions representations, we use a pre-training method to incorporate two kinds of question information including questions' relation and difficulty level. We also add a regularization term about questions' difficulty level to restrict pre-trained question representations to fine-tuning during the process of predicting students' performance. Moreover, we apply a dual-attentional mechanism to differentiate contributions of factors and factor interactions to final prediction in different practice records. At last, we conduct experiments on several real-world datasets and results show that MF-DAKT can outperform existing knowledge tracing methods. We also conduct several studies to validate the effects of each component of MF-DAKT.
* 10 pages, 10 figures, 6 tables