 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Closely: Mitigating Object Hallucinations in Large Vision-Language Models with Disentangled Decoding
Dec 22, 2025Large Vision-Language Models (LVLMs) bridge the gap between visual and linguistic modalities, demonstrating strong potential across a variety of domains. However, despite significant progress, LVLMs still suffer from severe hallucination issues in object recognition tasks. These models often fail to accurately identify certain objects, leading to text generation that appears fluent but does not correspond to the visual content, which can have serious consequences in real-world applications. Recently, several methods have been proposed to alleviate LVLM hallucinations, but most focus solely on reducing hallucinations in the language modality. To mitigate hallucinations in both the language and visual modalities, we introduce Hallucination Disentangled Decoding (HDD) method that requires no training. HDD enhances the original image by segmenting it and selecting images that augment the original, while also utilizing a blank image to eliminate language prior hallucinations in both the original and segmented images. This design not only reduces the model's dependence on language priors but also enhances its visual performance. (Code: https://github.com/rickeyhhh/Hallucination-Disentangled-Decoding)
Cognitive Duality for Adaptive Web Agents
Aug 07, 2025Web navigation represents a critical and challenging domain for evaluating artificial general intelligence (AGI), demanding complex decision-making within high-entropy, dynamic environments with combinatorially explosive action spaces. Current approaches to building autonomous web agents either focus on offline imitation learning or online exploration, but rarely integrate both paradigms effectively. Inspired by the dual-process theory of human cognition, we derive a principled decomposition into fast System 1 and slow System 2 cognitive processes. This decomposition provides a unifying perspective on existing web agent methodologies, bridging the gap between offline learning of intuitive reactive behaviors and online acquisition of deliberative planning capabilities. We implement this framework in CogniWeb, a modular agent architecture that adaptively toggles between fast intuitive processing and deliberate reasoning based on task complexity. Our evaluation on WebArena demonstrates that CogniWeb achieves competitive performance (43.96% success rate) while maintaining significantly higher efficiency (75% reduction in token usage).
Instruct-of-Reflection: Enhancing Large Language Models Iterative Reflection Capabilities via Dynamic-Meta Instruction
Mar 02, 2025



Self-reflection for Large Language Models (LLMs) has gained significant attention. Existing approaches involve models iterating and improving their previous responses based on LLMs' internal reflection ability or external feedback. However, recent research has raised doubts about whether intrinsic self-correction without external feedback may even degrade performance. Based on our empirical evidence, we find that current static reflection methods may lead to redundant, drift, and stubborn issues. To mitigate this, we introduce Instruct-of-Reflection (IoRT), a novel and general reflection framework that leverages dynamic-meta instruction to enhance the iterative reflection capability of LLMs. Specifically, we propose the instructor driven by the meta-thoughts and self-consistency classifier, generates various instructions, including refresh, stop, and select, to guide the next reflection iteration. Our experiments demonstrate that IoRT achieves an average improvement of 10.1% over established baselines in mathematical and commonsense reasoning tasks, highlighting its efficacy and applicability.
WEPO: Web Element Preference Optimization for LLM-based Web Navigation
Dec 14, 2024



The rapid advancement of autonomous web navigation has significantly benefited from grounding pretrained Large Language Models (LLMs) as agents. However, current research has yet to fully leverage the redundancy of HTML elements for contrastive training. This paper introduces a novel approach to LLM-based web navigation tasks, called Web Element Preference Optimization (WEPO). WEPO utilizes unsupervised preference learning by sampling distance-based non-salient web elements as negative samples, optimizing maximum likelihood objective within Direct Preference Optimization (DPO). We evaluate WEPO on the Mind2Web benchmark and empirically demonstrate that WEPO aligns user high-level intent with output actions more effectively. The results show that our method achieved the state-of-the-art, with an improvement of 13.8% over WebAgent and 5.3% over the visual language model CogAgent baseline. Our findings underscore the potential of preference optimization to enhance web navigation and other web page based tasks, suggesting a promising direction for future research.
AllTogether: Investigating the Efficacy of Spliced Prompt for Web Navigation using Large Language Models
Oct 31, 2023



Large Language Models (LLMs) have emerged as promising agents for web navigation tasks, interpreting objectives and interacting with web pages. However, the efficiency of spliced prompts for such tasks remains underexplored. We introduces AllTogether, a standardized prompt template that enhances task context representation, thereby improving LLMs' performance in HTML-based web navigation. We evaluate the efficacy of this approach through prompt learning and instruction finetuning based on open-source Llama-2 and API-accessible GPT models. Our results reveal that models like GPT-4 outperform smaller models in web navigation tasks. Additionally, we find that the length of HTML snippet and history trajectory significantly influence performance, and prior step-by-step instructions prove less effective than real-time environmental feedback. Overall, we believe our work provides valuable insights for future research in LLM-driven web agents.
Cognition-Mode Aware Variational Representation Learning Framework for Knowledge Tracing
Sep 03, 2023
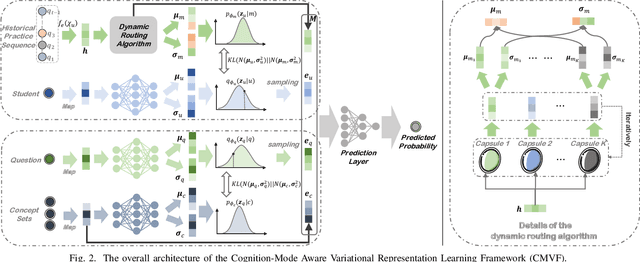
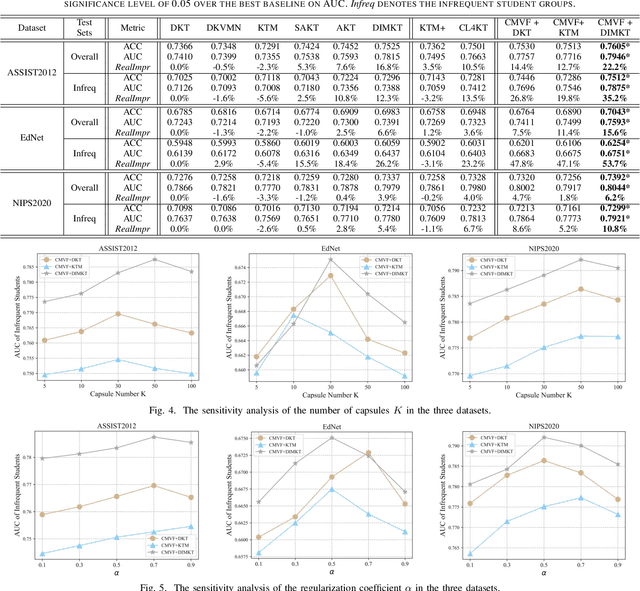
The Knowledge Tracing (KT) task plays a crucial role in personalized learning, and its purpose is to predict student responses based on their historical practice behavior sequence. However, the KT task suffers from data sparsity, which makes it challenging to learn robust representations for students with few practice records and increases the risk of model overfitting. Therefore, in this paper, we propose a Cognition-Mode Aware Variational Representation Learning Framework (CMVF) that can be directly applied to existing KT methods. Our framework uses a probabilistic model to generate a distribution for each student, accounting for uncertainty in those with limited practice records, and estimate the student's distribution via variational inference (VI). In addition, we also introduce a cognition-mode aware multinomial distribution as prior knowledge that constrains the posterior student distributions learning, so as to ensure that students with similar cognition modes have similar distributions, avoiding overwhelming personalization for students with few practice records. At last, extensive experimental results confirm that CMVF can effectively aid existing KT methods in learning more robust student representations. Our code is available at https://github.com/zmy-9/CMVF.
* Accepted by ICDM 2023, 10 pages, 5 figures, 4 tables
Counterfactual Monotonic Knowledge Tracing for Assessing Students' Dynamic Mastery of Knowledge Concepts
Aug 07, 2023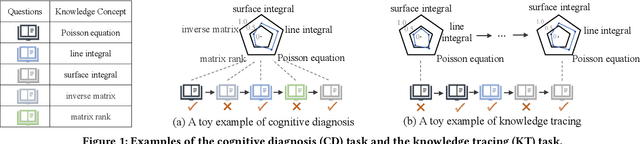
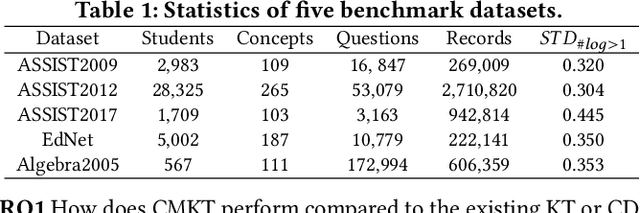
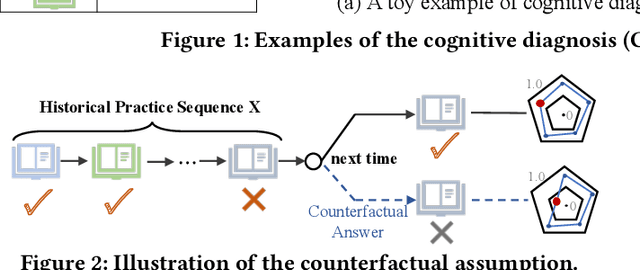
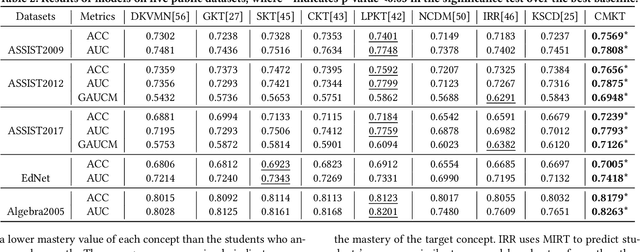
As the core of the Knowledge Tracking (KT) task, assessing students' dynamic mastery of knowledge concepts is crucial for both offline teaching and online educational applications. Since students' mastery of knowledge concepts is often unlabeled, existing KT methods rely on the implicit paradigm of historical practice to mastery of knowledge concepts to students' responses to practices to address the challenge of unlabeled concept mastery. However, purely predicting student responses without imposing specific constraints on hidden concept mastery values does not guarantee the accuracy of these intermediate values as concept mastery values. To address this issue, we propose a principled approach called Counterfactual Monotonic Knowledge Tracing (CMKT), which builds on the implicit paradigm described above by using a counterfactual assumption to constrain the evolution of students' mastery of knowledge concepts.
No Length Left Behind: Enhancing Knowledge Tracing for Modeling Sequences of Excessive or Insufficient Lengths
Aug 07, 2023
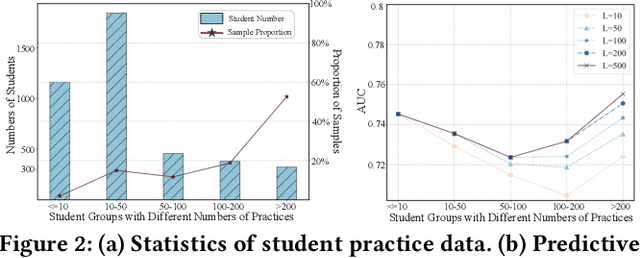
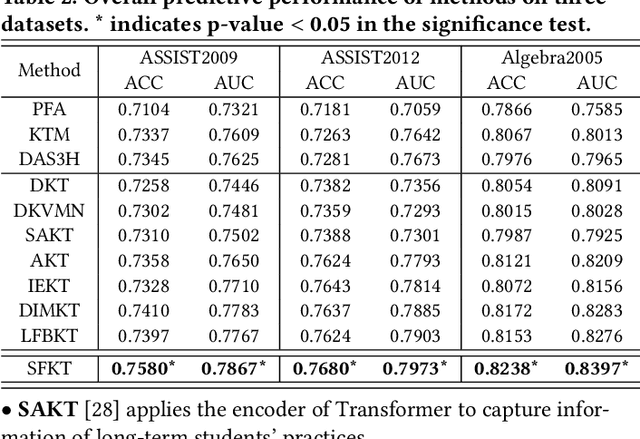
Knowledge tracing (KT) aims to predict students' responses to practices based on their historical question-answering behaviors. However, most current KT methods focus on improving overall AUC, leaving ample room for optimization in modeling sequences of excessive or insufficient lengths. As sequences get longer, computational costs will increase exponentially. Therefore, KT methods usually truncate sequences to an acceptable length, which makes it difficult for models on online service systems to capture complete historical practice behaviors of students with too long sequences. Conversely, modeling students with short practice sequences using most KT methods may result in overfitting due to limited observation samples. To address the above limitations, we propose a model called Sequence-Flexible Knowledge Tracing (SFKT).
Multi-source Education Knowledge Graph Construction and Fusion for College Curricula
May 08, 2023



The field of education has undergone a significant transformation due to the rapid advancements in Artificial Intelligence (AI). Among the various AI technologies, Knowledge Graphs (KGs) using Natural Language Processing (NLP) have emerged as powerful visualization tools for integrating multifaceted information. In the context of university education, the availability of numerous specialized courses and complicated learning resources often leads to inferior learning outcomes for students. In this paper, we propose an automated framework for knowledge extraction, visual KG construction, and graph fusion, tailored for the major of Electronic Information. Furthermore, we perform data analysis to investigate the correlation degree and relationship between courses, rank hot knowledge concepts, and explore the intersection of courses. Our objective is to enhance the learning efficiency of students and to explore new educational paradigms enabled by AI. The proposed framework is expected to enable students to better understand and appreciate the intricacies of their field of study by providing them with a comprehensive understanding of the relationships between the various concepts and courses.
A Chit-Chats Enhanced Task-Oriented Dialogue Corpora for Fuse-Motive Conversation Systems
May 12, 2022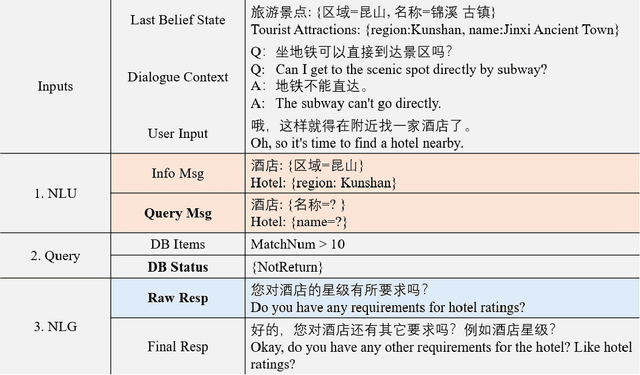
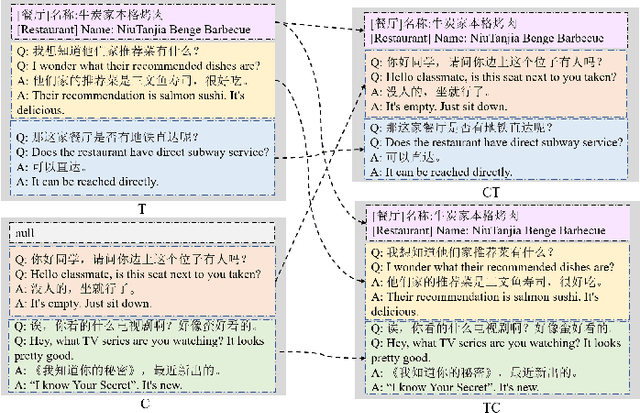

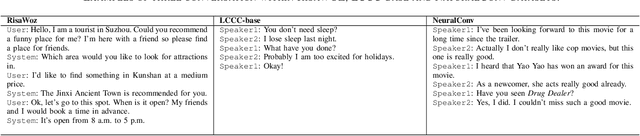
The goal of building intelligent dialogue systems has largely been separately pursued under two motives: task-oriented dialogue (TOD) systems, and open-domain systems for chit-chat (CC). Although previous TOD dialogue systems work well in the testing sets of benchmarks, they would lead to undesirable failure when being exposed to natural scenarios in practice, where user utterances can be of high motive-diversity that fusing both TOD and CC in multi-turn interaction. Since an industrial TOD system should be able to converse with the user between TOD and CC motives, constructing a fuse-motive dialogue dataset that contains both TOD or CC is important. Most prior work relies on crowd workers to collect and annotate large scale dataset and is restricted to English language setting. Our work, on the contrary, addresses this problem in a more effective way and releases a multi-turn dialogues dataset called CCET (Chinese Chat-Enhanced-Task). Meanwhile, we also propose a line of fuse-motive dialogues formalization approach, along with several evaluation metrics for TOD sessions that are integrated by CC utterances.