 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCloud-Text Matching: Benchmark Datasets and a Baseline
Mar 28, 2024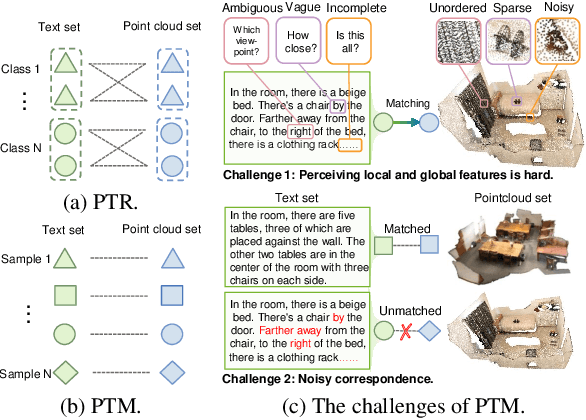



In this paper, we present and study a new instance-level retrieval task: PointCloud-Text Matching~(PTM), which aims to find the exact cross-modal instance that matches a given point-cloud query or text query. PTM could be applied to various scenarios, such as indoor/urban-canyon localization and scene retrieval. However, there exists no suitable and targeted dataset for PTM in practice. Therefore, we construct three new PTM benchmark datasets, namely 3D2T-SR, 3D2T-NR, and 3D2T-QA. We observe that the data is challenging and with noisy correspondence due to the sparsity, noise, or disorder of point clouds and the ambiguity, vagueness, or incompleteness of texts, which make existing cross-modal matching methods ineffective for PTM. To tackle these challenges, we propose a PTM baseline, named Robust PointCloud-Text Matching method (RoMa). RoMa consists of two modules: a Dual Attention Perception module (DAP) and a Robust Negative Contrastive Learning module (RNCL). Specifically, DAP leverages token-level and feature-level attention to adaptively focus on useful local and global features, and aggregate them into common representations, thereby reducing the adverse impact of noise and ambiguity. To handle noisy correspondence, RNCL divides negative pairs, which are much less error-prone than positive pairs, into clean and noisy subsets, and assigns them forward and reverse optimization directions respectively, thus enhancing robustness against noisy correspondence. We conduct extensive experiments on our benchmarks and demonstrate the superiority of our RoMa.