 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-AC: Enhancing Continual Learning in GUI Agents
Jun 09, 2026Graphical User Interfaces (GUIs) serve as the dominant medium for human-computer interaction, yet building GUI agents that generalize across the vast diversity of real-world interface environments, with the same flexibility and robustness that humans naturally exhibit, remains unsolved. Notably, GUI data are inherently non-stationary: the continual emergence of previously unseen interface instances (e.g., novel domains and resolutions) induces persistent distribution shifts, significantly impeding the continual learning of existing GUI agents. Reinforcement fine-tuning (RFT) has attracted considerable attention as a promising approach. Nevertheless, RFT exhibits pronounced instability in its grounding capability, manifested as sharp reward discontinuities and high-variance oscillations. The imbalanced distribution of rollout outcomes introduces substantial noise into advantage estimation, leading to policy overconfidence. The fixed clipping bound suppresses the increase in policy probabilities needed to adapt to new distributions, leading to a collapse in exploration capacity. To address these challenges, we propose GUI-AC, a method that enhances the continual learning capability of GUI agents. GUI-AC introduces grounding certainty to support two core mechanisms: (i) Adaptive Advantage, which down-weights noisy advantage estimates to prevent policy overconfidence; and (ii) Dynamic Clipping, which relaxes the clipping bound to encourage exploration range. Extensive experiments show that these mechanisms jointly improve performance, enabling our method to surpass state-of-the-art baselines. Code is available anonymously at https://anonymous.4open.science/r/GUI-AC.
5% > 100%: Flatness Preference is All You Need for Multimodal Parameter-Efficient Fine-Tuning
Jun 09, 2026Parameter-Efficient Fine-Tuning (PEFT) methods provide a streamlined and efficient tool for adapting large models to domain-specific multimodal downstream tasks. Although these methods proved their tangible effects in practice, their principal aspects remain under-explored. Therefore we remain curious about the underlying generalization mechanisms in various PEFT methods and how they can be further enhanced. In this paper, we reveal the flatness preference widely present in various PEFTs, where a small fraction of sharp dimensions dominates the generalization of PEFT. This finding suggests an appealing possibility: we may be satisfied with a better generalization by merely attending to this small fraction of sharp dimensions instead of all of them. Furthermore, we propose Flatness Preference Optimization (FlatPO) to flatten these key sharpness dimensions, leading various PEFTs toward better generalization. Extensive experiments demonstrate the effectiveness of our findings and the proposed method. Code is available at https://github.com/Can-Lin/FlatPO.
ERGeoBench:A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models
May 29, 2026Multimodal large language models (MLLMs) have shown strong potential as embodied agents, yet embodied geo-localization remains underexplored due to the lack of fine-grained evaluation. We introduce ERGeoBench, a diagnostic benchmark for vision-driven embodied geo-localization. ERGeoBench evaluates models under three progressive settings -- single-view, panorama-view, and embodied-view -- where agents may actively acquire observations through sequential changes in yaw, pitch, and zoom. The benchmark contains 2,207 globally distributed street-view panoramas and measures four complementary capabilities: foundational perception, spatial awareness, common sense reasoning, and geo-localization reasoning. Evaluations of leading proprietary and open-source MLLMs show that current models can infer high-level geographic semantics, but still struggle with fine-grained perceptual operations, metric localization, and spatial consistency across views. We further observe that geo-localization is strongly correlated with the other capability dimensions, suggesting that accurate localization depends on integrated perception, spatial reasoning, and commonsense inference rather than isolated visual recognition. Overall, ERGeoBench provides a unified framework for diagnosing and advancing human-like embodied geo-localization. Project Page: https://kaixuewen.github.io/ERGeoBench/
SliderQuant: Accurate Post-Training Quantization for LLMs
Mar 26, 2026In this paper, we address post-training quantization (PTQ) for large language models (LLMs) from an overlooked perspective: given a pre-trained high-precision LLM, the predominant sequential quantization framework treats different layers equally, but this may be not optimal in challenging bit-width settings. We empirically study the quantization impact of different layers on model accuracy, and observe that: (1) shallow/deep layers are usually more sensitive to quantization than intermediate layers; (2) among shallow/deep layers, the most sensitive one is the first/last layer, which exhibits significantly larger quantization error than others. These empirical observations imply that the quantization design for different layers of LLMs is required on multiple levels instead of a single level shared to all layers. Motivated by this, we propose a new PTQ framework termed Sliding-layer Quantization (SliderQuant) that relies on a simple adaptive sliding quantization concept facilitated by few learnable parameters. The base component of SliderQuant is called inter-layer sliding quantization, which incorporates three types of novel sliding window designs tailored for addressing the varying quantization sensitivity of shallow, intermediate and deep layers. The other component is called intra-layer sliding quantization that leverages an incremental strategy to quantize each window. As a result, SliderQuant has a strong ability to reduce quantization errors across layers. Extensive experiments on basic language generation, zero-shot commonsense reasoning and challenging math and code tasks with various LLMs, including Llama/Llama2/Llama3/Qwen2.5 model families, DeepSeek-R1 distilled models and large MoE models, show that our method outperforms existing PTQ methods (including the latest PTQ methods using rotation transformations) for both weight-only quantization and weight-activation quantization.
OmniRAG-Agent: Agentic Omnimodal Reasoning for Low-Resource Long Audio-Video Question Answering
Feb 03, 2026Long-horizon omnimodal question answering answers questions by reasoning over text, images, audio, and video. Despite recent progress on OmniLLMs, low-resource long audio-video QA still suffers from costly dense encoding, weak fine-grained retrieval, limited proactive planning, and no clear end-to-end optimization.To address these issues, we propose OmniRAG-Agent, an agentic omnimodal QA method for budgeted long audio-video reasoning. It builds an image-audio retrieval-augmented generation module that lets an OmniLLM fetch short, relevant frames and audio snippets from external banks. Moreover, it uses an agent loop that plans, calls tools across turns, and merges retrieved evidence to answer complex queries. Furthermore, we apply group relative policy optimization to jointly improve tool use and answer quality over time. Experiments on OmniVideoBench, WorldSense, and Daily-Omni show that OmniRAG-Agent consistently outperforms prior methods under low-resource settings and achieves strong results, with ablations validating each component.
CreBench: Human-Aligned Creativity Evaluation from Idea to Process to Product
Nov 17, 2025Human-defined creativity is highly abstract, posing a challenge for multimodal large language models (MLLMs) to comprehend and assess creativity that aligns with human judgments. The absence of an existing benchmark further exacerbates this dilemma. To this end, we propose CreBench, which consists of two key components: 1) an evaluation benchmark covering the multiple dimensions from creative idea to process to products; 2) CreMIT (Creativity Multimodal Instruction Tuning dataset), a multimodal creativity evaluation dataset, consisting of 2.2K diverse-sourced multimodal data, 79.2K human feedbacks and 4.7M multi-typed instructions. Specifically, to ensure MLLMs can handle diverse creativity-related queries, we prompt GPT to refine these human feedbacks to activate stronger creativity assessment capabilities. CreBench serves as a foundation for building MLLMs that understand human-aligned creativity. Based on the CreBench, we fine-tune open-source general MLLMs, resulting in CreExpert, a multimodal creativity evaluation expert model. Extensive experiments demonstrate that the proposed CreExpert models achieve significantly better alignment with human creativity evaluation compared to state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision.
A Foundation Model for Chest X-ray Interpretation with Grounded Reasoning via Online Reinforcement Learning
Sep 04, 2025Medical foundation models (FMs) have shown tremendous promise amid the rapid advancements in artificial intelligence (AI) technologies. However, current medical FMs typically generate answers in a black-box manner, lacking transparent reasoning processes and locally grounded interpretability, which hinders their practical clinical deployments. To this end, we introduce DeepMedix-R1, a holistic medical FM for chest X-ray (CXR) interpretation. It leverages a sequential training pipeline: initially fine-tuned on curated CXR instruction data to equip with fundamental CXR interpretation capabilities, then exposed to high-quality synthetic reasoning samples to enable cold-start reasoning, and finally refined via online reinforcement learning to enhance both grounded reasoning quality and generation performance. Thus, the model produces both an answer and reasoning steps tied to the image's local regions for each query. Quantitative evaluation demonstrates substantial improvements in report generation (e.g., 14.54% and 31.32% over LLaVA-Rad and MedGemma) and visual question answering (e.g., 57.75% and 23.06% over MedGemma and CheXagent) tasks. To facilitate robust assessment, we propose Report Arena, a benchmarking framework using advanced language models to evaluate answer quality, further highlighting the superiority of DeepMedix-R1. Expert review of generated reasoning steps reveals greater interpretability and clinical plausibility compared to the established Qwen2.5-VL-7B model (0.7416 vs. 0.2584 overall preference). Collectively, our work advances medical FM development toward holistic, transparent, and clinically actionable modeling for CXR interpretation.
Efficient Robotic Policy Learning via Latent Space Backward Planning
May 11, 2025Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent Space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance. Project Page: https://lbp-authors.github.io
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
Feb 17, 2025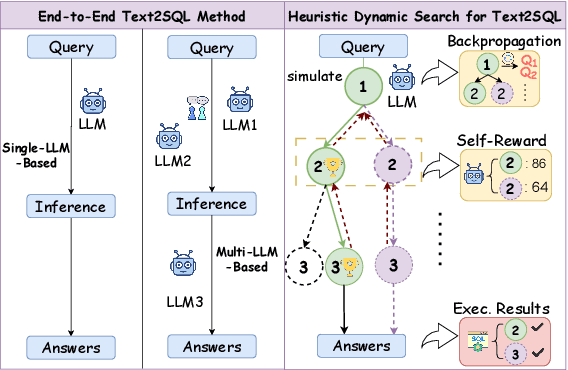


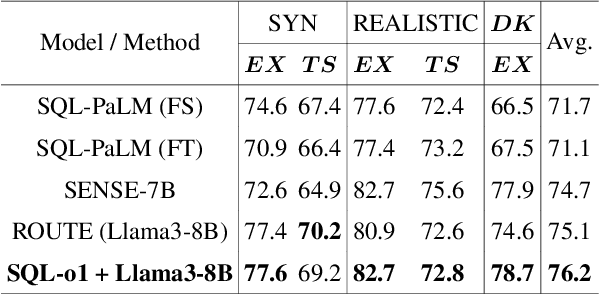
The Text-to-SQL(Text2SQL) task aims to convert natural language queries into executable SQL queries. Thanks to the application of large language models (LLMs), significant progress has been made in this field. However, challenges such as model scalability, limited generation space, and coherence issues in SQL generation still persist. To address these issues, we propose SQL-o1, a Self-Reward-based heuristic search method designed to enhance the reasoning ability of LLMs in SQL query generation. SQL-o1 combines Monte Carlo Tree Search (MCTS) for heuristic process-level search and constructs a Schema-Aware dataset to help the model better understand database schemas. Extensive experiments on the Bird and Spider datasets demonstrate that SQL-o1 improves execution accuracy by 10.8\% on the complex Bird dataset compared to the latest baseline methods, even outperforming GPT-4-based approaches. Additionally, SQL-o1 excels in few-shot learning scenarios and shows strong cross-model transferability. Our code is publicly available at:https://github.com/ShuaiLyu0110/SQL-o1.
TSVC:Tripartite Learning with Semantic Variation Consistency for Robust Image-Text Retrieval
Jan 19, 2025Cross-modal retrieval maps data under different modality via semantic relevance. Existing approaches implicitly assume that data pairs are well-aligned and ignore the widely existing annotation noise, i.e., noisy correspondence (NC). Consequently, it inevitably causes performance degradation. Despite attempts that employ the co-teaching paradigm with identical architectures to provide distinct data perspectives, the differences between these architectures are primarily stemmed from random initialization. Thus, the model becomes increasingly homogeneous along with the training process. Consequently, the additional information brought by this paradigm is severely limited. In order to resolve this problem, we introduce a Tripartite learning with Semantic Variation Consistency (TSVC) for robust image-text retrieval. We design a tripartite cooperative learning mechanism comprising a Coordinator, a Master, and an Assistant model. The Coordinator distributes data, and the Assistant model supports the Master model's noisy label prediction with diverse data. Moreover, we introduce a soft label estimation method based on mutual information variation, which quantifies the noise in new samples and assigns corresponding soft labels. We also present a new loss function to enhance robustness and optimize training effectiveness. Extensive experiments on three widely used datasets demonstrate that, even at increasing noise ratios, TSVC exhibits significant advantages in retrieval accuracy and maintains stable training performance.