 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARGIN: Margin-Aware Regularized Geometry for Imbalanced Vulnerability Detection
May 11, 2026Software vulnerability detection is critical for ensuring software security and reliability. Despite recent advances in deep learning, real-world vulnerability datasets suffer from two severe challenges: frequency imbalance and difficulty imbalance. We reinterpret these challenges from an embedding geometry perspective, observing that such imbalances induce geometric distortions in hyperspherical representation space. To address this issue, we propose MARGIN, a metric-based framework that learns discriminative vulnerability representations through adaptive margin metric learning and hyperspherical prototype modeling. MARGIN dynamically adjusts geometric regularization according to the distribution structure estimated by the von Mises-Fisher concentration, aligning the probability mass of embedding distributions with their corresponding Voronoi cells, thereby reducing geometric distortion and yielding more stable decision boundaries. Extensive experiments on public vulnerability datasets show that MARGIN consistently outperforms strong baselines, achieving notable improvements in classification and detection, especially on challenging, imbalanced datasets. Further analysis demonstrates that MARGIN produces more structured embedding geometries, improving robustness, interpretability, and generalization.
HCPM: Hierarchical Candidates Pruning for Efficient Detector-Free Matching
Mar 19, 2024Deep learning-based image matching methods play a crucial role in computer vision, yet they often suffer from substantial computational demands. To tackle this challenge, we present HCPM, an efficient and detector-free local feature-matching method that employs hierarchical pruning to optimize the matching pipeline. In contrast to recent detector-free methods that depend on an exhaustive set of coarse-level candidates for matching, HCPM selectively concentrates on a concise subset of informative candidates, resulting in fewer computational candidates and enhanced matching efficiency. The method comprises a self-pruning stage for selecting reliable candidates and an interactive-pruning stage that identifies correlated patches at the coarse level. Our results reveal that HCPM significantly surpasses existing methods in terms of speed while maintaining high accuracy. The source code will be made available upon publication.
Boost Image Captioning with Knowledge Reasoning
Nov 02, 2020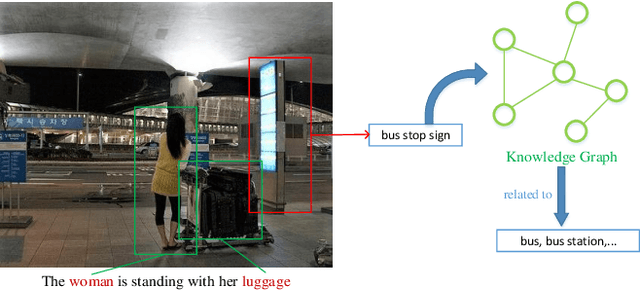
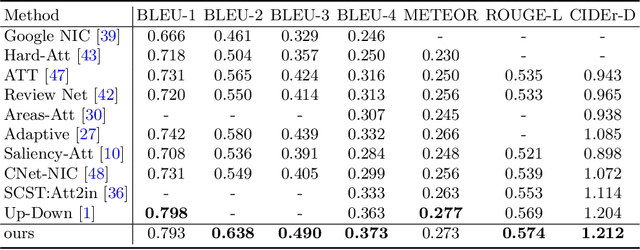
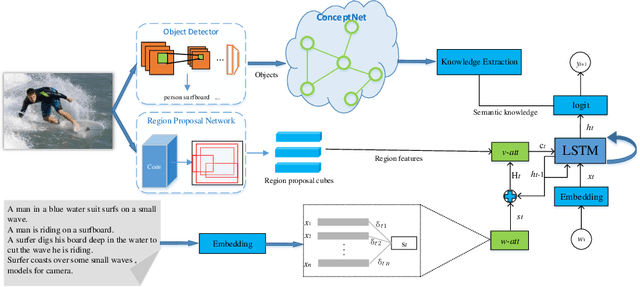

Automatically generating a human-like description for a given image is a potential research in artificial intelligence, which has attracted a great of attention recently. Most of the existing attention methods explore the mapping relationships between words in sentence and regions in image, such unpredictable matching manner sometimes causes inharmonious alignments that may reduce the quality of generated captions. In this paper, we make our efforts to reason about more accurate and meaningful captions. We first propose word attention to improve the correctness of visual attention when generating sequential descriptions word-by-word. The special word attention emphasizes on word importance when focusing on different regions of the input image, and makes full use of the internal annotation knowledge to assist the calculation of visual attention. Then, in order to reveal those incomprehensible intentions that cannot be expressed straightforwardly by machines, we introduce a new strategy to inject external knowledge extracted from knowledge graph into the encoder-decoder framework to facilitate meaningful captioning. Finally, we validate our model on two freely available captioning benchmarks: Microsoft COCO dataset and Flickr30k dataset. The results demonstrate that our approach achieves state-of-the-art performance and outperforms many of the existing approaches.
DeepGoal: Learning to Drive with driving intention from Human Control Demonstration
Nov 28, 2019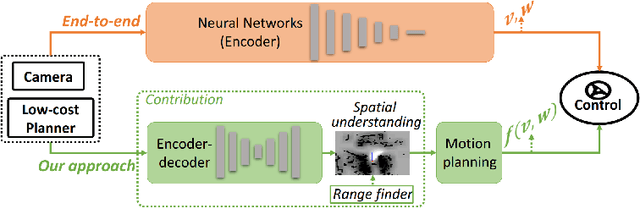

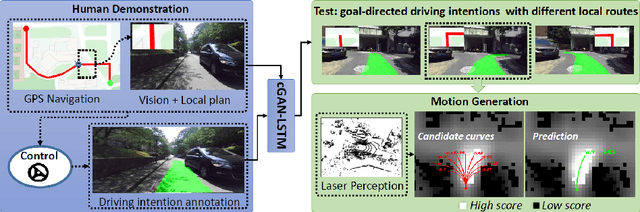
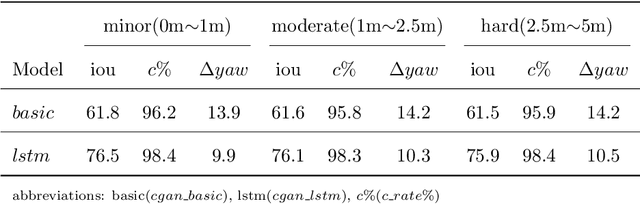
Recent research on automotive driving developed an efficient end-to-end learning mode that directly maps visual input to control commands. However, it models distinct driving variations in a single network, which increases learning complexity and is less adaptive for modular integration. In this paper, we re-investigate human's driving style and propose to learn an intermediate driving intention region to relax difficulties in end-to-end approach. The intention region follows both road structure in image and direction towards goal in public route planner, which addresses visual variations only and figures out where to go without conventional precise localization. Then the learned visual intention is projected on vehicle local coordinate and fused with reliable obstacle perception to render a navigation score map widely used for motion planning. The core of the proposed system is a weakly-supervised cGAN-LSTM model trained to learn driving intention from human demonstration. The adversarial loss learns from limited demonstration data with one local planned route and enables reasoning of multi-modal behavior with diverse routes while testing. Comprehensive experiments are conducted with real-world datasets. Results show the proposed paradigm can produce more consistent motion commands with human demonstration, and indicates better reliability and robustness to environment change.
Weakly-Supervised Road Affordances Inference and Learning in Scenes without Traffic Signs
Nov 27, 2019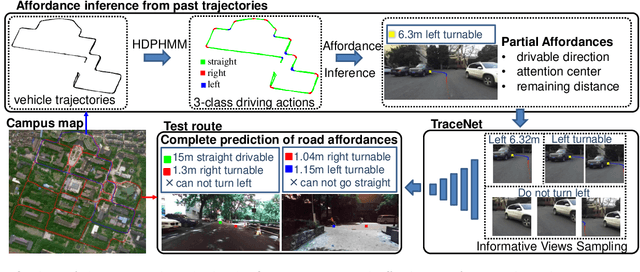
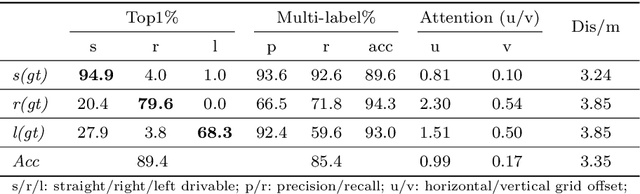

Road attributes understanding is extensively researched to support vehicle's action for autonomous driving, whereas current works mainly focus on urban road nets and rely much on traffic signs. This paper generalizes the same issue to the scenes with little or without traffic signs, such as campuses and residential areas. These scenes face much more individually diverse appearances while few annotated datasets. To explore these challenges, a weakly-supervised framework is proposed to infer and learn road affordances without manual annotation, which includes three attributes of drivable direction, driving attention center and remaining distance. The method consists of two steps: affordances inference from trajectory and learning from partially labeled data. The first step analyzes vehicle trajectories to get partial affordances annotation on image, and the second step implements a weakly-supervised network to learn partial annotation and predict complete road affordances while testing. Real-world datasets are collected to validate the proposed method which achieves 88.2%/80.9% accuracy on direction-level and 74.3% /66.7% accuracy on image-level in familiar and unfamiliar scenes respectively.
Towards navigation without precise localization: Weakly supervised learning of goal-directed navigation cost map
Jun 06, 2019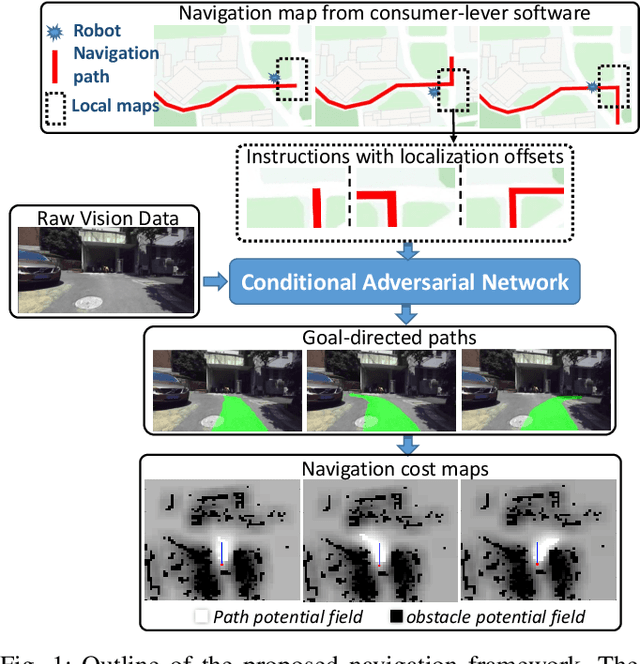

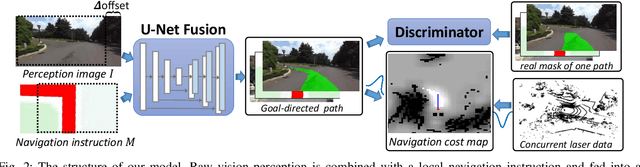
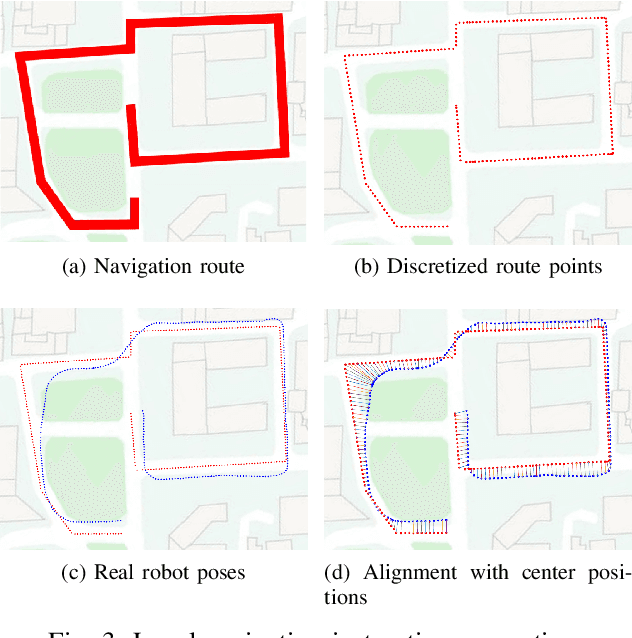
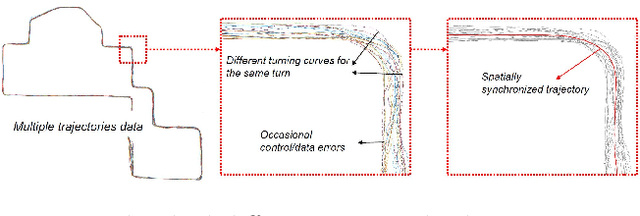
Autonomous navigation based on precise localization has been widely developed in both academic research and practical applications. The high demand for localization accuracy has been essential for safe robot planing and navigation while it makes the current geometric solutions less robust to environmental changes. Recent research on end-to-end methods handle raw sensory data with forms of navigation instructions and directly output the command for robot control. However, the lack of intermediate semantics makes the system more rigid and unstable for practical use. To explore these issues, this paper proposes an innovate navigation framework based on the GPS-level localization, which takes the raw perception data with publicly accessible navigation maps to produce an intermediate navigation cost map that allows subsequent flexible motion planning. A deterministic conditional adversarial network is adopted in our method to generate visual goal-directed paths under diverse navigation conditions. The adversarial loss avoids the pixel-level annotation and enables a weakly supervised training strategy to implicitly learn both of the traffic semantics in image perceptions and the planning intentions in navigation instructions. The navigation cost map is then rendered from the goal-directed path and the concurrently collected laser data, indicating the way towards the destination. Comprehensive experiments have been conducted with a real vehicle running in our campus and the results have verified the robustness to localization error of the proposed navigation system.
3D-SSD: Learning Hierarchical Features from RGB-D Images for Amodal 3D Object Detection
Feb 21, 2018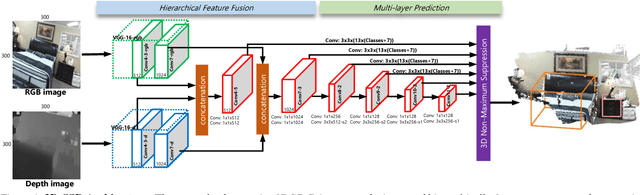
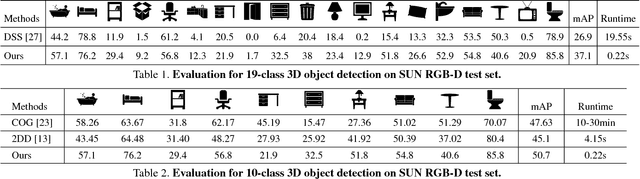
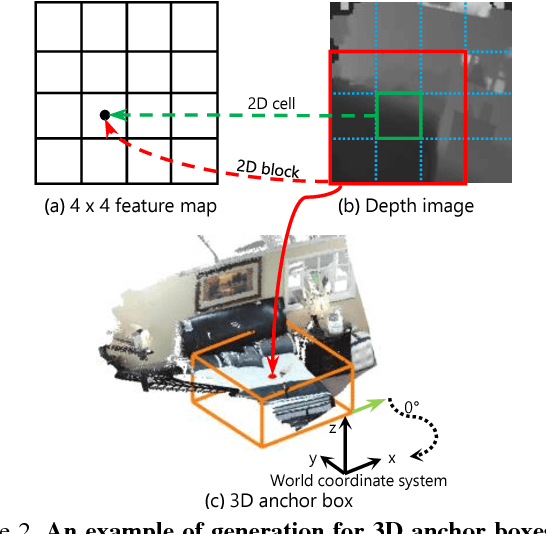
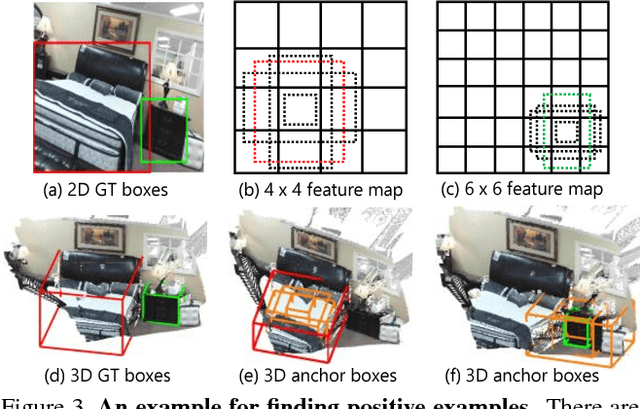
This paper aims at developing a faster and a more accurate solution to the amodal 3D object detection problem for indoor scenes. It is achieved through a novel neural network that takes a pair of RGB-D images as the input and delivers oriented 3D bounding boxes as the output. The network, named 3D-SSD, composed of two parts: hierarchical feature fusion and multi-layer prediction. The hierarchical feature fusion combines appearance and geometric features from RGB-D images while the multi-layer prediction utilizes multi-scale features for object detection. As a result, the network can exploit 2.5D representations in a synergetic way to improve the accuracy and efficiency. The issue of object sizes is addressed by attaching a set of 3D anchor boxes with varying sizes to every location of the prediction layers. At the end stage, the category scores for 3D anchor boxes are generated with adjusted positions, sizes and orientations respectively, leading to the final detections using non-maximum suppression. In the training phase, the positive samples are identified with the aid of 2D ground truth to avoid the noisy estimation of depth from raw data, which guide to a better converged model. Experiments performed on the challenging SUN RGB-D dataset show that our algorithm outperforms the state-of-the-art Deep Sliding Shape by 10.2% mAP and 88x faster. Further, experiments also suggest our approach achieves comparable accuracy and is 386x faster than the state-of-art method on the NYUv2 dataset even with a smaller input image size.