 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Weakly-Supervised Road Affordances Inference and Learning in Scenes without Traffic Signs
Nov 27, 2019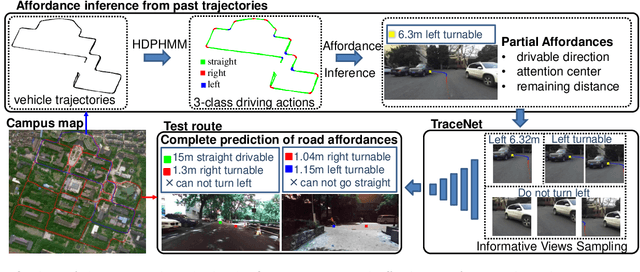
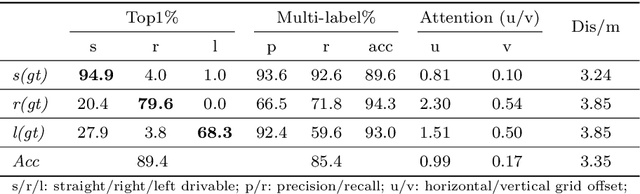
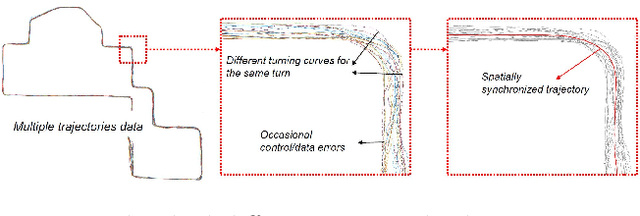

Road attributes understanding is extensively researched to support vehicle's action for autonomous driving, whereas current works mainly focus on urban road nets and rely much on traffic signs. This paper generalizes the same issue to the scenes with little or without traffic signs, such as campuses and residential areas. These scenes face much more individually diverse appearances while few annotated datasets. To explore these challenges, a weakly-supervised framework is proposed to infer and learn road affordances without manual annotation, which includes three attributes of drivable direction, driving attention center and remaining distance. The method consists of two steps: affordances inference from trajectory and learning from partially labeled data. The first step analyzes vehicle trajectories to get partial affordances annotation on image, and the second step implements a weakly-supervised network to learn partial annotation and predict complete road affordances while testing. Real-world datasets are collected to validate the proposed method which achieves 88.2%/80.9% accuracy on direction-level and 74.3% /66.7% accuracy on image-level in familiar and unfamiliar scenes respectively.
3D-SSD: Learning Hierarchical Features from RGB-D Images for Amodal 3D Object Detection
Feb 21, 2018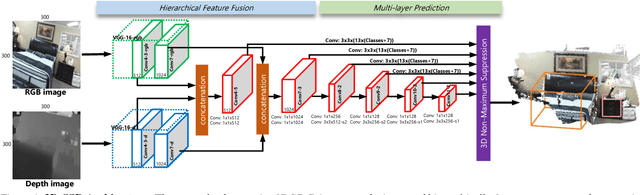
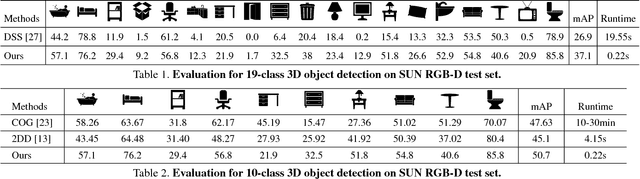
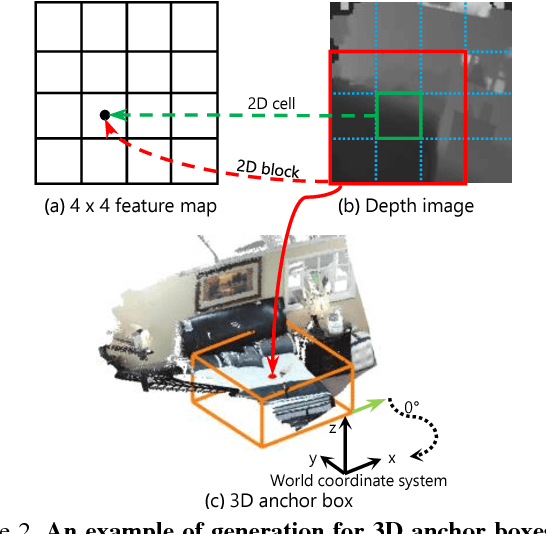
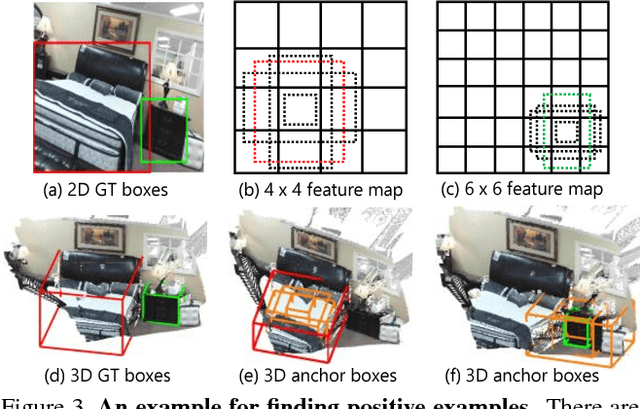
This paper aims at developing a faster and a more accurate solution to the amodal 3D object detection problem for indoor scenes. It is achieved through a novel neural network that takes a pair of RGB-D images as the input and delivers oriented 3D bounding boxes as the output. The network, named 3D-SSD, composed of two parts: hierarchical feature fusion and multi-layer prediction. The hierarchical feature fusion combines appearance and geometric features from RGB-D images while the multi-layer prediction utilizes multi-scale features for object detection. As a result, the network can exploit 2.5D representations in a synergetic way to improve the accuracy and efficiency. The issue of object sizes is addressed by attaching a set of 3D anchor boxes with varying sizes to every location of the prediction layers. At the end stage, the category scores for 3D anchor boxes are generated with adjusted positions, sizes and orientations respectively, leading to the final detections using non-maximum suppression. In the training phase, the positive samples are identified with the aid of 2D ground truth to avoid the noisy estimation of depth from raw data, which guide to a better converged model. Experiments performed on the challenging SUN RGB-D dataset show that our algorithm outperforms the state-of-the-art Deep Sliding Shape by 10.2% mAP and 88x faster. Further, experiments also suggest our approach achieves comparable accuracy and is 386x faster than the state-of-art method on the NYUv2 dataset even with a smaller input image size.