 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Road Affordances Inference and Learning in Scenes without Traffic Signs
Paper and Code
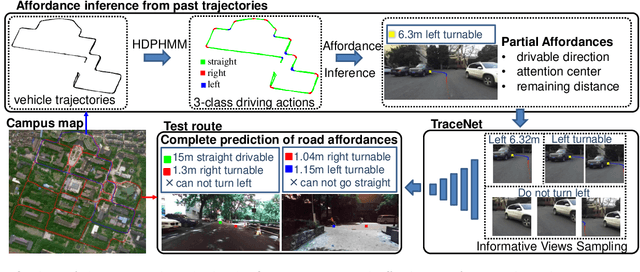
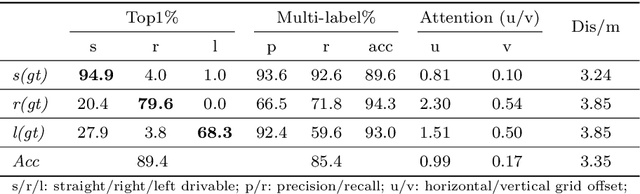
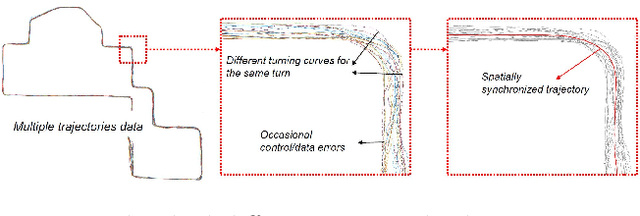

Road attributes understanding is extensively researched to support vehicle's action for autonomous driving, whereas current works mainly focus on urban road nets and rely much on traffic signs. This paper generalizes the same issue to the scenes with little or without traffic signs, such as campuses and residential areas. These scenes face much more individually diverse appearances while few annotated datasets. To explore these challenges, a weakly-supervised framework is proposed to infer and learn road affordances without manual annotation, which includes three attributes of drivable direction, driving attention center and remaining distance. The method consists of two steps: affordances inference from trajectory and learning from partially labeled data. The first step analyzes vehicle trajectories to get partial affordances annotation on image, and the second step implements a weakly-supervised network to learn partial annotation and predict complete road affordances while testing. Real-world datasets are collected to validate the proposed method which achieves 88.2%/80.9% accuracy on direction-level and 74.3% /66.7% accuracy on image-level in familiar and unfamiliar scenes respectively.