 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Visual Clutter in Vision Language Action Models via Concept-Gated Visual Distillation
Mar 11, 2026Vision-Language-Action (VLA) models demonstrate impressive zero-shot generalization but frequently suffer from a "Precision-Reasoning Gap" in cluttered environments. This failure is driven by background-induced feature dilution, where high-frequency semantic noise corrupts the geometric grounding required for precise manipulation. To bridge this gap, we propose Concept-Gated Visual Distillation (CGVD), a training-free, model-agnostic inference framework that stabilizes VLA policies. CGVD operates by parsing instructions into safe and distractor sets, utilizing a two-layer target refinement process--combining cross-validation and spatial disambiguation--to explicitly penalize false positives and isolate genuine manipulation targets. We then process the scene via Fourier-based inpainting, generating a clean observation that actively suppresses semantic distractors while preserving critical spatial geometry and visual proprioception. Extensive evaluations in highly cluttered manipulation tasks demonstrate that CGVD prevents performance collapse. In environments with dense semantic distractors, our method significantly outperforms state-of-the-art baselines, achieving a 77.5% success rate compared to the baseline's 43.0%. By enforcing strict attribute adherence, CGVD establishes inference-time visual distillation as a critical prerequisite for robust robotic manipulation in the clutter.
Guide-LLM: An Embodied LLM Agent and Text-Based Topological Map for Robotic Guidance of People with Visual Impairments
Oct 28, 2024



Navigation presents a significant challenge for persons with visual impairments (PVI). While traditional aids such as white canes and guide dogs are invaluable, they fall short in delivering detailed spatial information and precise guidance to desired locations. Recent developments in large language models (LLMs) and vision-language models (VLMs) offer new avenues for enhancing assistive navigation. In this paper, we introduce Guide-LLM, an embodied LLM-based agent designed to assist PVI in navigating large indoor environments. Our approach features a novel text-based topological map that enables the LLM to plan global paths using a simplified environmental representation, focusing on straight paths and right-angle turns to facilitate navigation. Additionally, we utilize the LLM's commonsense reasoning for hazard detection and personalized path planning based on user preferences. Simulated experiments demonstrate the system's efficacy in guiding PVI, underscoring its potential as a significant advancement in assistive technology. The results highlight Guide-LLM's ability to offer efficient, adaptive, and personalized navigation assistance, pointing to promising advancements in this field.
DeepGoal: Learning to Drive with driving intention from Human Control Demonstration
Nov 28, 2019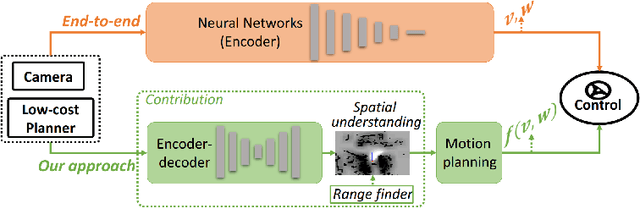

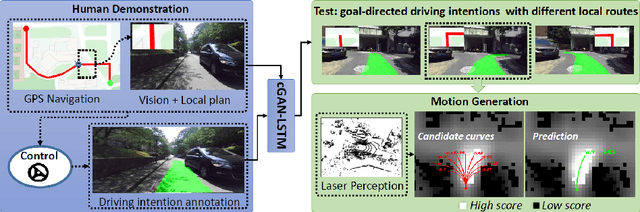
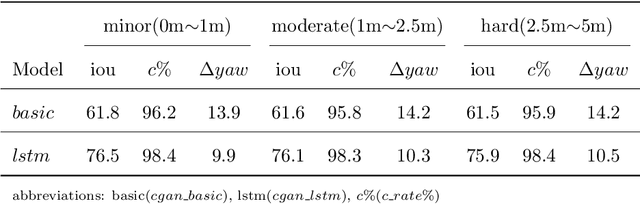
Recent research on automotive driving developed an efficient end-to-end learning mode that directly maps visual input to control commands. However, it models distinct driving variations in a single network, which increases learning complexity and is less adaptive for modular integration. In this paper, we re-investigate human's driving style and propose to learn an intermediate driving intention region to relax difficulties in end-to-end approach. The intention region follows both road structure in image and direction towards goal in public route planner, which addresses visual variations only and figures out where to go without conventional precise localization. Then the learned visual intention is projected on vehicle local coordinate and fused with reliable obstacle perception to render a navigation score map widely used for motion planning. The core of the proposed system is a weakly-supervised cGAN-LSTM model trained to learn driving intention from human demonstration. The adversarial loss learns from limited demonstration data with one local planned route and enables reasoning of multi-modal behavior with diverse routes while testing. Comprehensive experiments are conducted with real-world datasets. Results show the proposed paradigm can produce more consistent motion commands with human demonstration, and indicates better reliability and robustness to environment change.
Weakly-Supervised Road Affordances Inference and Learning in Scenes without Traffic Signs
Nov 27, 2019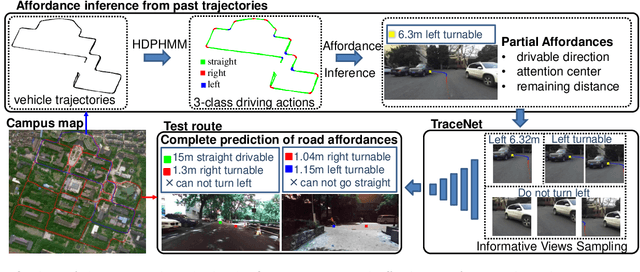
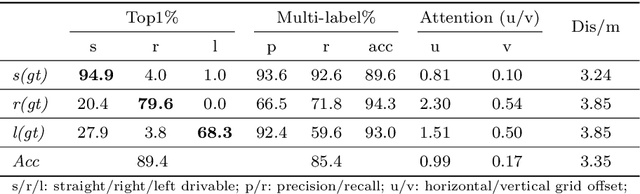
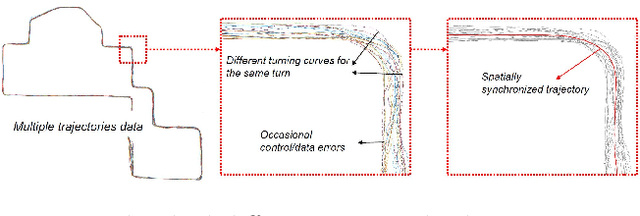

Road attributes understanding is extensively researched to support vehicle's action for autonomous driving, whereas current works mainly focus on urban road nets and rely much on traffic signs. This paper generalizes the same issue to the scenes with little or without traffic signs, such as campuses and residential areas. These scenes face much more individually diverse appearances while few annotated datasets. To explore these challenges, a weakly-supervised framework is proposed to infer and learn road affordances without manual annotation, which includes three attributes of drivable direction, driving attention center and remaining distance. The method consists of two steps: affordances inference from trajectory and learning from partially labeled data. The first step analyzes vehicle trajectories to get partial affordances annotation on image, and the second step implements a weakly-supervised network to learn partial annotation and predict complete road affordances while testing. Real-world datasets are collected to validate the proposed method which achieves 88.2%/80.9% accuracy on direction-level and 74.3% /66.7% accuracy on image-level in familiar and unfamiliar scenes respectively.
Real-Time 3D Profiling with RGB-D Mapping in Pipelines Using Stereo Camera Vision and Structured IR Laser Ring
Jul 29, 2019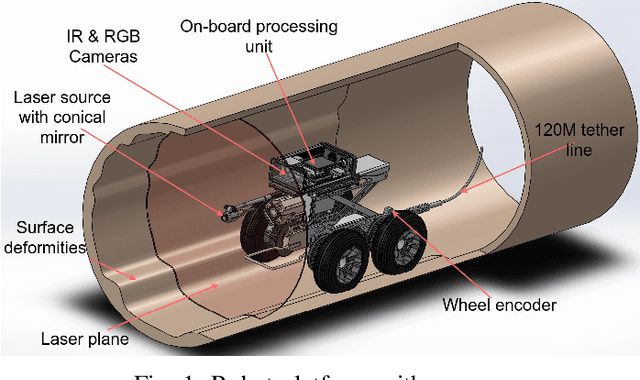
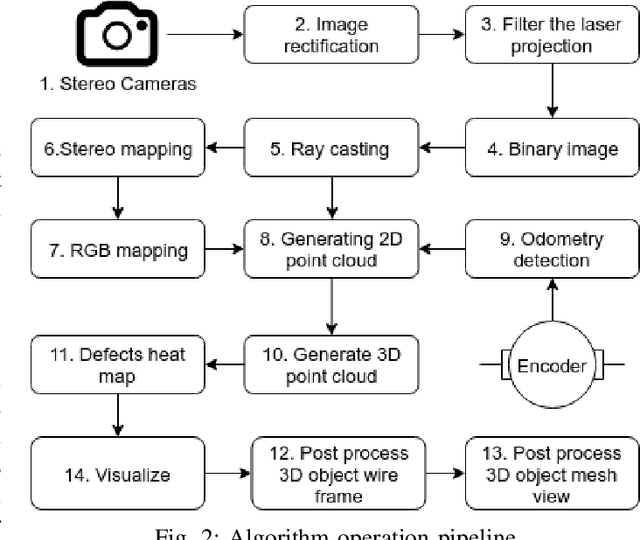

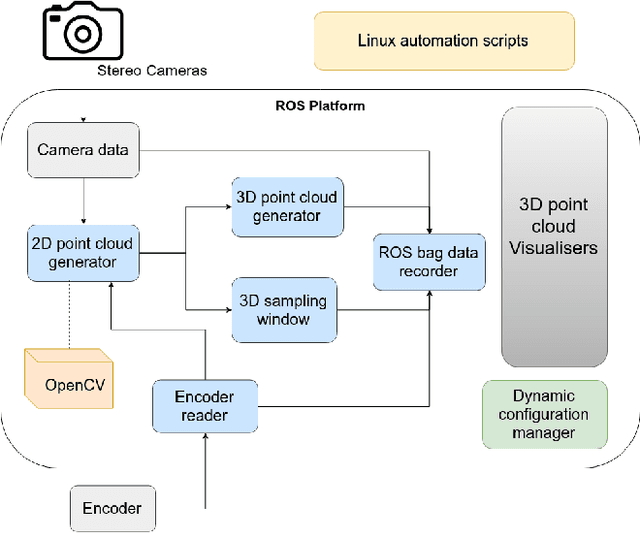
This paper is focused on delivering a solution that can scan and reconstruct the 3D profile of a pipeline in real-time using a crawler robot. A structured infrared (IR) laser ring projector and a stereo camera system are used to generate the 3D profile of the pipe as the robot moves inside the pipe. The proposed stereo system does not require field calibrations and it is not affected by the lateral movement of the robot, hence capable of producing an accurate 3D map. The wavelength of the IR light source is chosen to be non overlapping with the visible spectrum of the color camera. Hence RGB color values of the depth can be obtained by projecting the 3D map into the color image frame. The proposed system is implemented in Robotic Operating System (ROS) producing real-time RGB-D maps with defects. The defect map exploit differences in ovality enabling real-time identification of structural defects such as surface corrosion in pipe infrastructure. The lab experiments showed the proposed laser profiling system can detect ovality changes of the pipe with millimeter level of accuracy and resolution.
Understanding Human Context in 3D Scenes by Learning Spatial Affordances with Virtual Skeleton Models
Jun 13, 2019
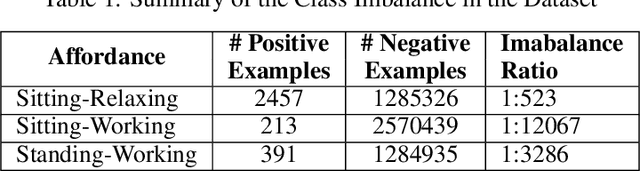
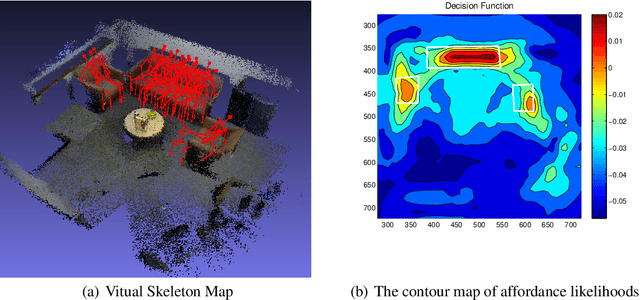
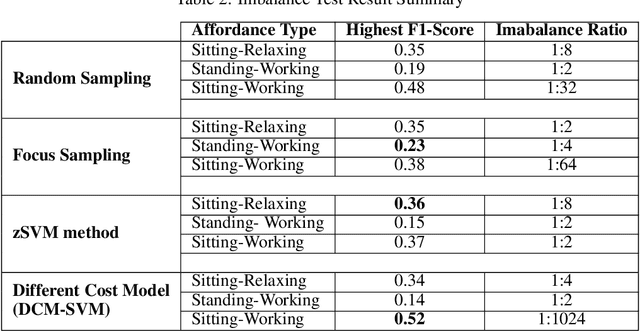
Robots are often required to operate in environments where humans are not present, but yet require the human context information for better human-robot interaction. Even when humans are present in the environment, detecting their presence in cluttered environments could be challenging. As a solution to this problem, this paper presents the concept of spatial affordance map which learns human context by looking at geometric features of the environment. Instead of observing real humans to learn human context, it uses virtual human models and their relationships with the environment to map hidden human affordances in 3D scenes by placing virtual skeleton models in 3D scenes with their confidence values. The spatial affordance map learning problem is formulated as a multi-label classification problem that can be learned using Support Vector Machine (SVM) based learners. Experiments carried out in a real 3D scene dataset recorded promising results and proved the applicability of affordance-map for mapping human context.
Towards navigation without precise localization: Weakly supervised learning of goal-directed navigation cost map
Jun 06, 2019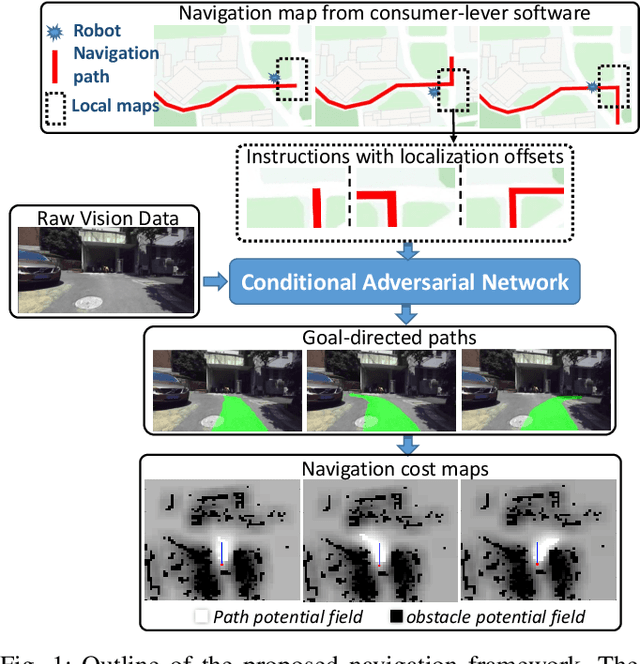

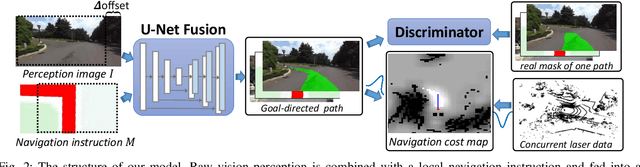
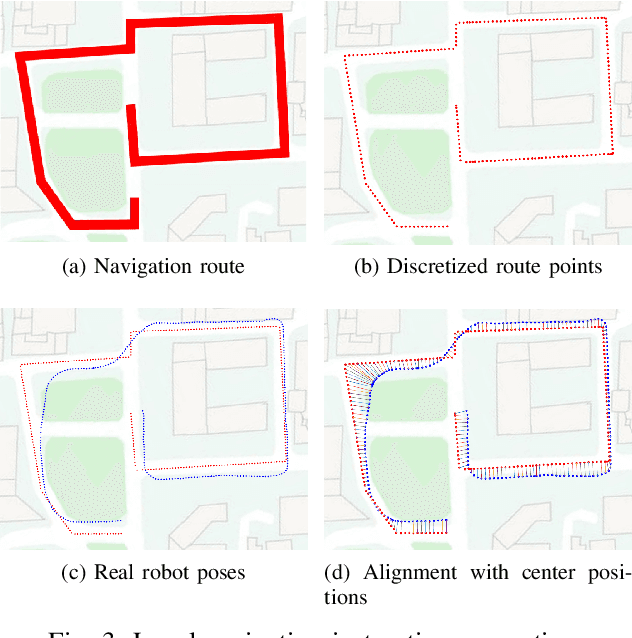
Autonomous navigation based on precise localization has been widely developed in both academic research and practical applications. The high demand for localization accuracy has been essential for safe robot planing and navigation while it makes the current geometric solutions less robust to environmental changes. Recent research on end-to-end methods handle raw sensory data with forms of navigation instructions and directly output the command for robot control. However, the lack of intermediate semantics makes the system more rigid and unstable for practical use. To explore these issues, this paper proposes an innovate navigation framework based on the GPS-level localization, which takes the raw perception data with publicly accessible navigation maps to produce an intermediate navigation cost map that allows subsequent flexible motion planning. A deterministic conditional adversarial network is adopted in our method to generate visual goal-directed paths under diverse navigation conditions. The adversarial loss avoids the pixel-level annotation and enables a weakly supervised training strategy to implicitly learn both of the traffic semantics in image perceptions and the planning intentions in navigation instructions. The navigation cost map is then rendered from the goal-directed path and the concurrently collected laser data, indicating the way towards the destination. Comprehensive experiments have been conducted with a real vehicle running in our campus and the results have verified the robustness to localization error of the proposed navigation system.
Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation
Oct 17, 2016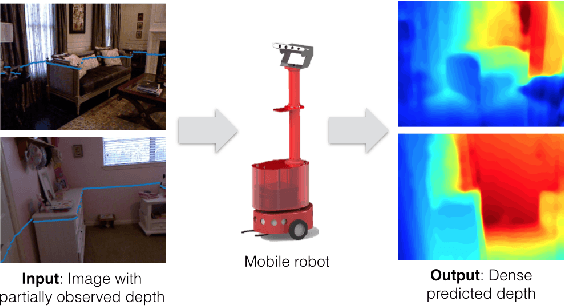
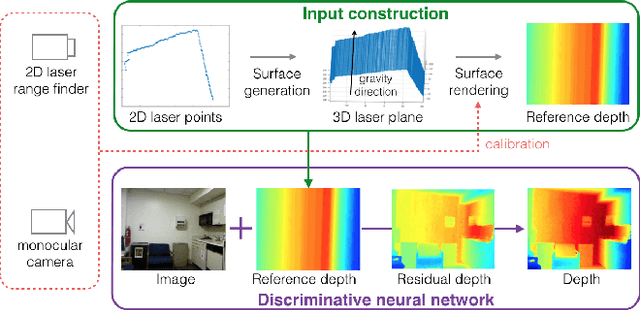
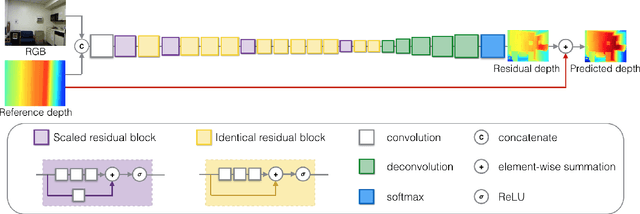
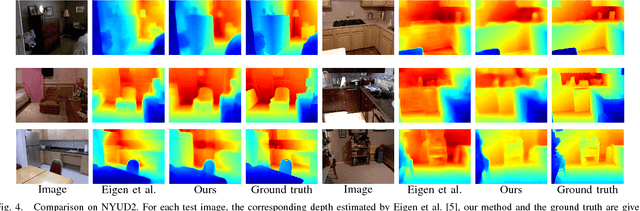
Many standard robotic platforms are equipped with at least a fixed 2D laser range finder and a monocular camera. Although those platforms do not have sensors for 3D depth sensing capability, knowledge of depth is an essential part in many robotics activities. Therefore, recently, there is an increasing interest in depth estimation using monocular images. As this task is inherently ambiguous, the data-driven estimated depth might be unreliable in robotics applications. In this paper, we have attempted to improve the precision of monocular depth estimation by introducing 2D planar observation from the remaining laser range finder without extra cost. Specifically, we construct a dense reference map from the sparse laser range data, redefining the depth estimation task as estimating the distance between the real and the reference depth. To solve the problem, we construct a novel residual of residual neural network, and tightly combine the classification and regression losses for continuous depth estimation. Experimental results suggest that our method achieves considerable promotion compared to the state-of-the-art methods on both NYUD2 and KITTI, validating the effectiveness of our method on leveraging the additional sensory information. We further demonstrate the potential usage of our method in obstacle avoidance where our methodology provides comprehensive depth information compared to the solution using monocular camera or 2D laser range finder alone.
Fast, On-board, Model-aided Visual-Inertial Odometry System for Quadrotor Micro Aerial Vehicles
Jul 06, 2016
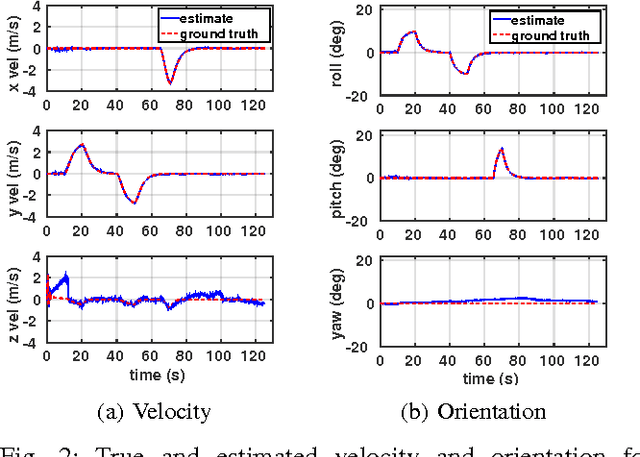
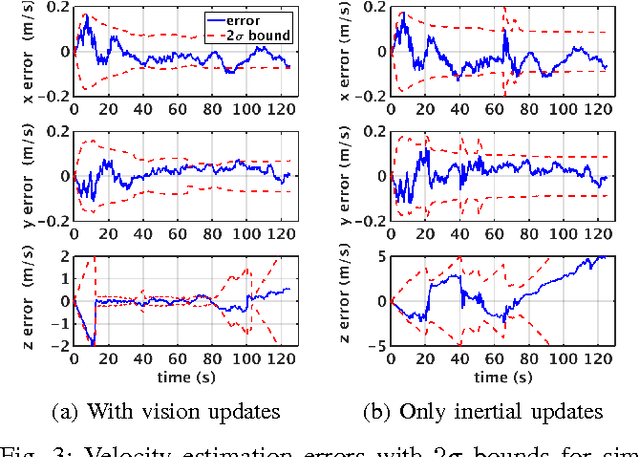
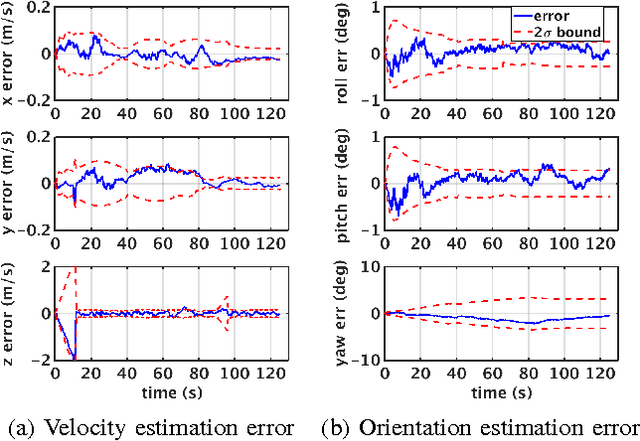
The main contribution of this paper is a high frequency, low-complexity, on-board visual-inertial odometry system for quadrotor micro air vehicles. The system consists of an extended Kalman filter (EKF) based state estimation algorithm that fuses information from a low cost MEMS inertial measurement unit acquired at 200Hz and VGA resolution images from a monocular camera at 50Hz. The dynamic model describing the quadrotor motion is employed in the estimation algorithm as a third source of information. Visual information is incorporated into the EKF by enforcing the epipolar constraint on features tracked between image pairs, avoiding the need to explicitly estimate the location of the tracked environmental features. Combined use of the dynamic model and epipolar constraints makes it possible to obtain drift free velocity and attitude estimates in the presence of both accelerometer and gyroscope biases. A strategy to deal with the unobservability that arises when the quadrotor is in hover is also provided. Experimental data from a real-time implementation of the system on a 50 gram embedded computer are presented in addition to the simulations to demonstrate the efficacy of the proposed system.
* 8 pages
Understand Scene Categories by Objects: A Semantic Regularized Scene Classifier Using Convolutional Neural Networks
Sep 22, 2015
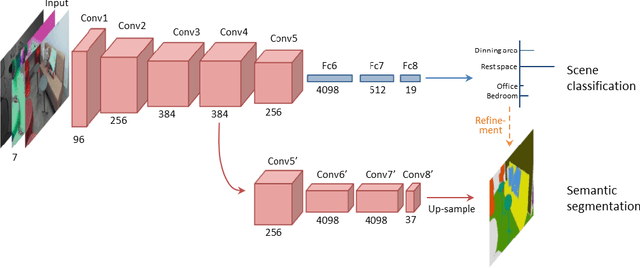
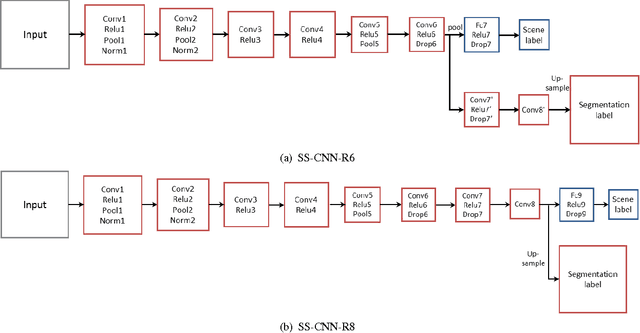

Scene classification is a fundamental perception task for environmental understanding in today's robotics. In this paper, we have attempted to exploit the use of popular machine learning technique of deep learning to enhance scene understanding, particularly in robotics applications. As scene images have larger diversity than the iconic object images, it is more challenging for deep learning methods to automatically learn features from scene images with less samples. Inspired by human scene understanding based on object knowledge, we address the problem of scene classification by encouraging deep neural networks to incorporate object-level information. This is implemented with a regularization of semantic segmentation. With only 5 thousand training images, as opposed to 2.5 million images, we show the proposed deep architecture achieves superior scene classification results to the state-of-the-art on a publicly available SUN RGB-D dataset. In addition, performance of semantic segmentation, the regularizer, also reaches a new record with refinement derived from predicted scene labels. Finally, we apply our SUN RGB-D dataset trained model to a mobile robot captured images to classify scenes in our university demonstrating the generalization ability of the proposed algorithm.