 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Human Context in 3D Scenes by Learning Spatial Affordances with Virtual Skeleton Models
Paper and Code
Jun 13, 2019
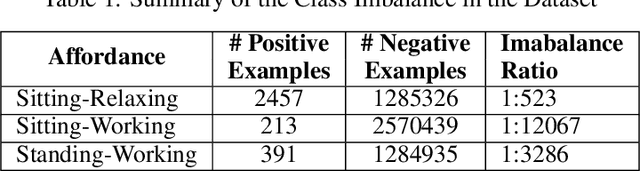
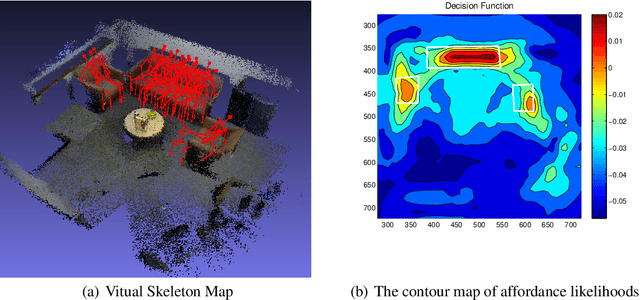
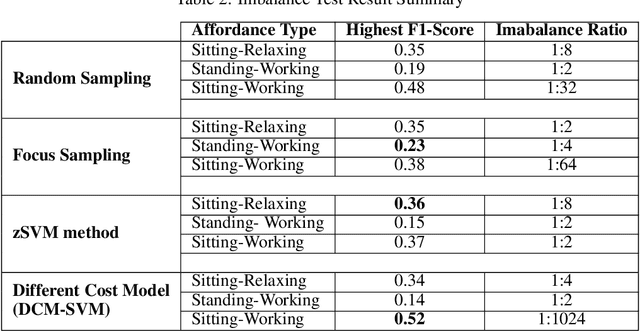
Robots are often required to operate in environments where humans are not present, but yet require the human context information for better human-robot interaction. Even when humans are present in the environment, detecting their presence in cluttered environments could be challenging. As a solution to this problem, this paper presents the concept of spatial affordance map which learns human context by looking at geometric features of the environment. Instead of observing real humans to learn human context, it uses virtual human models and their relationships with the environment to map hidden human affordances in 3D scenes by placing virtual skeleton models in 3D scenes with their confidence values. The spatial affordance map learning problem is formulated as a multi-label classification problem that can be learned using Support Vector Machine (SVM) based learners. Experiments carried out in a real 3D scene dataset recorded promising results and proved the applicability of affordance-map for mapping human context.