 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-SSD: Learning Hierarchical Features from RGB-D Images for Amodal 3D Object Detection
Paper and Code
Feb 21, 2018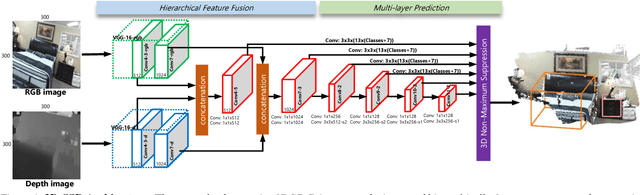
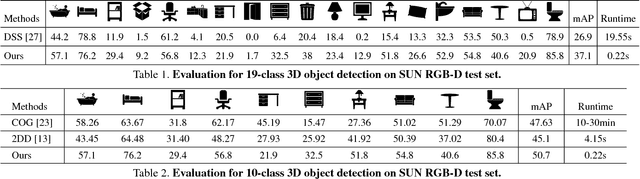
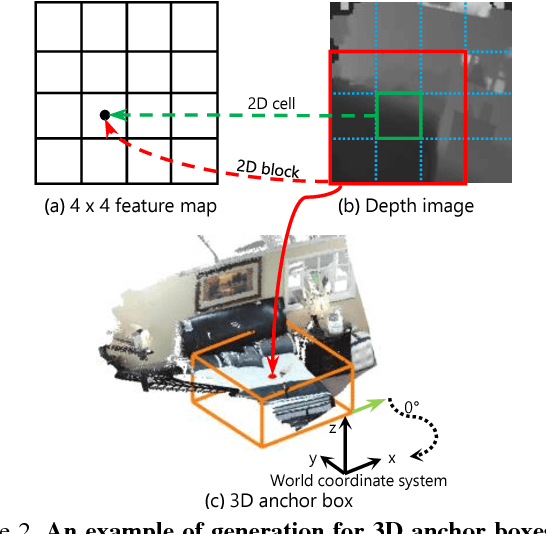
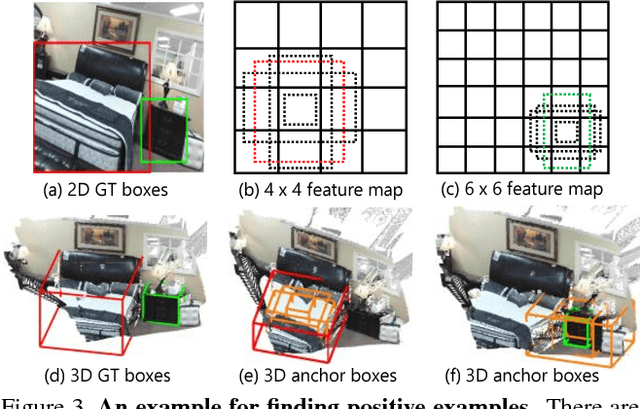
This paper aims at developing a faster and a more accurate solution to the amodal 3D object detection problem for indoor scenes. It is achieved through a novel neural network that takes a pair of RGB-D images as the input and delivers oriented 3D bounding boxes as the output. The network, named 3D-SSD, composed of two parts: hierarchical feature fusion and multi-layer prediction. The hierarchical feature fusion combines appearance and geometric features from RGB-D images while the multi-layer prediction utilizes multi-scale features for object detection. As a result, the network can exploit 2.5D representations in a synergetic way to improve the accuracy and efficiency. The issue of object sizes is addressed by attaching a set of 3D anchor boxes with varying sizes to every location of the prediction layers. At the end stage, the category scores for 3D anchor boxes are generated with adjusted positions, sizes and orientations respectively, leading to the final detections using non-maximum suppression. In the training phase, the positive samples are identified with the aid of 2D ground truth to avoid the noisy estimation of depth from raw data, which guide to a better converged model. Experiments performed on the challenging SUN RGB-D dataset show that our algorithm outperforms the state-of-the-art Deep Sliding Shape by 10.2% mAP and 88x faster. Further, experiments also suggest our approach achieves comparable accuracy and is 386x faster than the state-of-art method on the NYUv2 dataset even with a smaller input image size.