 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Workflow for Materials Discovery Bridging the Gap Between Experimental Databases and Graph Neural Networks
Jan 31, 2026Incorporating Machine Learning (ML) into material property prediction has become a crucial step in accelerating materials discovery. A key challenge is the severe lack of training data, as many properties are too complicated to calculate with high-throughput first principles techniques. To address this, recent research has created experimental databases from information extracted from scientific literature. However, most existing experimental databases do not provide full atomic coordinate information, which prevents them from supporting advanced ML architectures such as Graph Neural Networks (GNNs). In this work, we propose to bridge this gap through an alignment process between experimental databases and Crystallographic Information Files (CIF) from the Inorganic Crystal Structure Database (ICSD). Our approach enables the creation of a database that can fully leverage state-of-the-art model architectures for material property prediction. It also opens the door to utilizing transfer learning to improve prediction accuracy. To validate our approach, we align NEMAD with the ICSD and compare models trained on the resulting database to those trained on NEMAD originally. We demonstrate significant improvements in both Mean Absolute Error (MAE) and Correct Classification Rate (CCR) in predicting the ordering temperatures and magnetic ground states of magnetic materials, respectively.
Training a Perceptual Model for Evaluating Auditory Similarity in Music Adversarial Attack
Sep 05, 2025
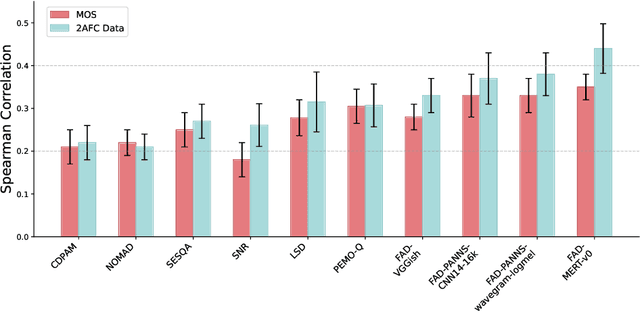
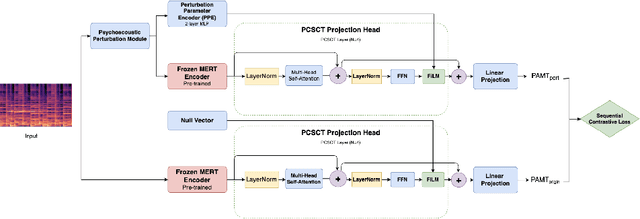
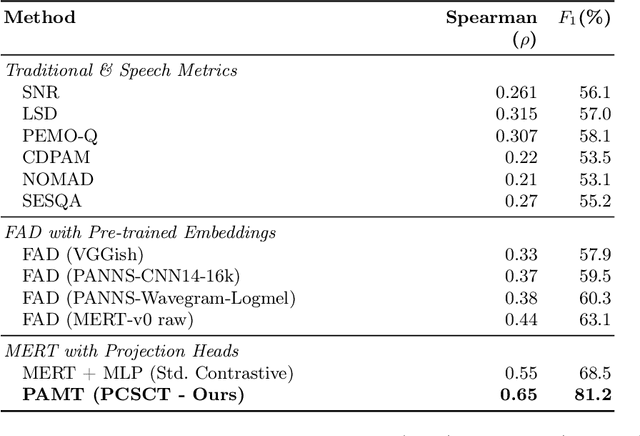
Music Information Retrieval (MIR) systems are highly vulnerable to adversarial attacks that are often imperceptible to humans, primarily due to a misalignment between model feature spaces and human auditory perception. Existing defenses and perceptual metrics frequently fail to adequately capture these auditory nuances, a limitation supported by our initial listening tests showing low correlation between common metrics and human judgments. To bridge this gap, we introduce Perceptually-Aligned MERT Transformer (PAMT), a novel framework for learning robust, perceptually-aligned music representations. Our core innovation lies in the psychoacoustically-conditioned sequential contrastive transformer, a lightweight projection head built atop a frozen MERT encoder. PAMT achieves a Spearman correlation coefficient of 0.65 with subjective scores, outperforming existing perceptual metrics. Our approach also achieves an average of 9.15\% improvement in robust accuracy on challenging MIR tasks, including Cover Song Identification and Music Genre Classification, under diverse perceptual adversarial attacks. This work pioneers architecturally-integrated psychoacoustic conditioning, yielding representations significantly more aligned with human perception and robust against music adversarial attacks.
MAIA: An Inpainting-Based Approach for Music Adversarial Attacks
Sep 05, 2025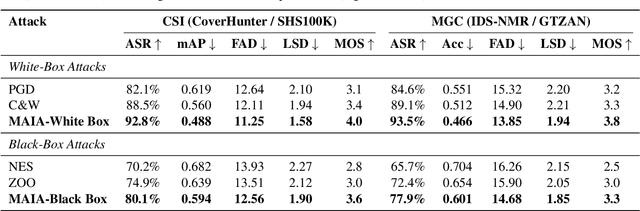
Music adversarial attacks have garnered significant interest in the field of Music Information Retrieval (MIR). In this paper, we present Music Adversarial Inpainting Attack (MAIA), a novel adversarial attack framework that supports both white-box and black-box attack scenarios. MAIA begins with an importance analysis to identify critical audio segments, which are then targeted for modification. Utilizing generative inpainting models, these segments are reconstructed with guidance from the output of the attacked model, ensuring subtle and effective adversarial perturbations. We evaluate MAIA on multiple MIR tasks, demonstrating high attack success rates in both white-box and black-box settings while maintaining minimal perceptual distortion. Additionally, subjective listening tests confirm the high audio fidelity of the adversarial samples. Our findings highlight vulnerabilities in current MIR systems and emphasize the need for more robust and secure models.
TF-SepNet: An Efficient 1D Kernel Design in CNNs for Low-Complexity Acoustic Scene Classification
Sep 15, 2023



Recent studies focus on developing efficient systems for acoustic scene classification (ASC) using convolutional neural networks (CNNs), which typically consist of consecutive kernels. This paper highlights the benefits of using separate kernels as a more powerful and efficient design approach in ASC tasks. Inspired by the time-frequency nature of audio signals, we propose TF-SepNet, a CNN architecture that separates the feature processing along the time and frequency dimensions. Features resulted from the separate paths are then merged by channels and directly forwarded to the classifier. Instead of the conventional two dimensional (2D) kernel, TF-SepNet incorporates one dimensional (1D) kernels to reduce the computational costs. Experiments have been conducted using the TAU Urban Acoustic Scene 2022 Mobile development dataset. The results show that TF-SepNet outperforms similar state-of-the-arts that use consecutive kernels. A further investigation reveals that the separate kernels lead to a larger effective receptive field (ERF), which enables TF-SepNet to capture more time-frequency features.