 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Material Point Method for the Control of Deformable Objects
Dec 15, 2025



Controlling the deformation of flexible objects is challenging due to their non-linear dynamics and high-dimensional configuration space. This work presents a differentiable Material Point Method (MPM) simulator targeted at control applications. We exploit the differentiability of the simulator to optimize a control trajectory in an active damping problem for a hyperelastic rope. The simulator effectively minimizes the kinetic energy of the rope around 2$\times$ faster than a baseline MPPI method and to a 20% lower energy level, while using about 3% of the computation time.
RAMBO: RL-augmented Model-based Optimal Control for Whole-body Loco-manipulation
Apr 09, 2025
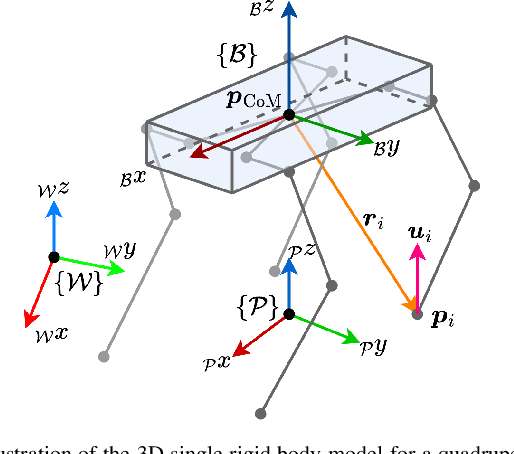
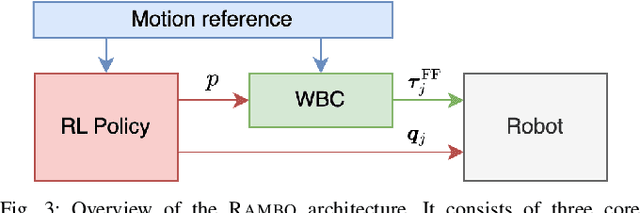

Loco-manipulation -- coordinated locomotion and physical interaction with objects -- remains a major challenge for legged robots due to the need for both accurate force interaction and robustness to unmodeled dynamics. While model-based controllers provide interpretable dynamics-level planning and optimization, they are limited by model inaccuracies and computational cost. In contrast, learning-based methods offer robustness while struggling with precise modulation of interaction forces. We introduce RAMBO -- RL-Augmented Model-Based Optimal Control -- a hybrid framework that integrates model-based reaction force optimization using a simplified dynamics model and a feedback policy trained with reinforcement learning. The model-based module generates feedforward torques by solving a quadratic program, while the policy provides feedback residuals to enhance robustness in control execution. We validate our framework on a quadruped robot across a diverse set of real-world loco-manipulation tasks -- such as pushing a shopping cart, balancing a plate, and holding soft objects -- in both quadrupedal and bipedal walking. Our experiments demonstrate that RAMBO enables precise manipulation while achieving robust and dynamic locomotion, surpassing the performance of policies trained with end-to-end scheme. In addition, our method enables flexible trade-off between end-effector tracking accuracy with compliance.
Improving generalization of robot locomotion policies via Sharpness-Aware Reinforcement Learning
Nov 29, 2024



Reinforcement learning often requires extensive training data. Simulation-to-real transfer offers a promising approach to address this challenge in robotics. While differentiable simulators offer improved sample efficiency through exact gradients, they can be unstable in contact-rich environments and may lead to poor generalization. This paper introduces a novel approach integrating sharpness-aware optimization into gradient-based reinforcement learning algorithms. Our simulation results demonstrate that our method, tested on contact-rich environments, significantly enhances policy robustness to environmental variations and action perturbations while maintaining the sample efficiency of first-order methods. Specifically, our approach improves action noise tolerance compared to standard first-order methods and achieves generalization comparable to zeroth-order methods. This improvement stems from finding flatter minima in the loss landscape, associated with better generalization. Our work offers a promising solution to balance efficient learning and robust sim-to-real transfer in robotics, potentially bridging the gap between simulation and real-world performance.