 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAIMAN: Causal Action Influence Detection for Sample Efficient Loco-manipulation
Feb 02, 2025Enabling legged robots to perform non-prehensile loco-manipulation with large and heavy objects is crucial for enhancing their versatility. However, this is a challenging task, often requiring sophisticated planning strategies or extensive task-specific reward shaping, especially in unstructured scenarios with obstacles. In this work, we present CAIMAN, a novel framework for learning loco-manipulation that relies solely on sparse task rewards. We leverage causal action influence to detect states where the robot is in control over other entities in the environment, and use this measure as an intrinsically motivated objective to enable sample-efficient learning. We employ a hierarchical control strategy, combining a low-level locomotion policy with a high-level policy that prioritizes task-relevant velocity commands. Through simulated and real-world experiments, including object manipulation with obstacles, we demonstrate the framework's superior sample efficiency, adaptability to diverse environments, and successful transfer to hardware without fine-tuning. The proposed approach paves the way for scalable, robust, and autonomous loco-manipulation in real-world applications.
Causal Action Influence Aware Counterfactual Data Augmentation
May 29, 2024



Offline data are both valuable and practical resources for teaching robots complex behaviors. Ideally, learning agents should not be constrained by the scarcity of available demonstrations, but rather generalize beyond the training distribution. However, the complexity of real-world scenarios typically requires huge amounts of data to prevent neural network policies from picking up on spurious correlations and learning non-causal relationships. We propose CAIAC, a data augmentation method that can create feasible synthetic transitions from a fixed dataset without having access to online environment interactions. By utilizing principled methods for quantifying causal influence, we are able to perform counterfactual reasoning by swapping $\it{action}$-unaffected parts of the state-space between independent trajectories in the dataset. We empirically show that this leads to a substantial increase in robustness of offline learning algorithms against distributional shift.
Efficient Learning of High Level Plans from Play
Mar 16, 2023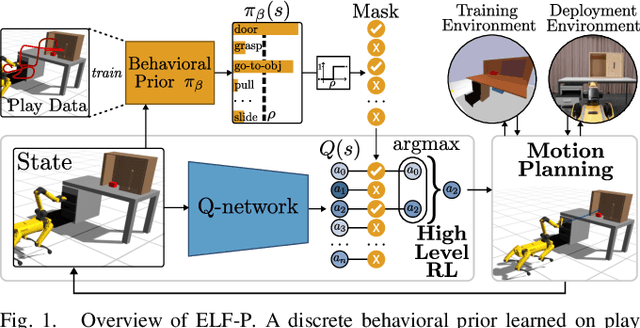

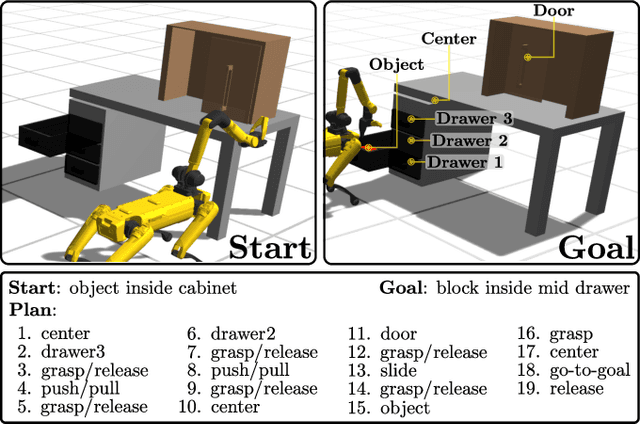

Real-world robotic manipulation tasks remain an elusive challenge, since they involve both fine-grained environment interaction, as well as the ability to plan for long-horizon goals. Although deep reinforcement learning (RL) methods have shown encouraging results when planning end-to-end in high-dimensional environments, they remain fundamentally limited by poor sample efficiency due to inefficient exploration, and by the complexity of credit assignment over long horizons. In this work, we present Efficient Learning of High-Level Plans from Play (ELF-P), a framework for robotic learning that bridges motion planning and deep RL to achieve long-horizon complex manipulation tasks. We leverage task-agnostic play data to learn a discrete behavioral prior over object-centric primitives, modeling their feasibility given the current context. We then design a high-level goal-conditioned policy which (1) uses primitives as building blocks to scaffold complex long-horizon tasks and (2) leverages the behavioral prior to accelerate learning. We demonstrate that ELF-P has significantly better sample efficiency than relevant baselines over multiple realistic manipulation tasks and learns policies that can be easily transferred to physical hardware.
Risk-Averse Offline Reinforcement Learning
Feb 10, 2021
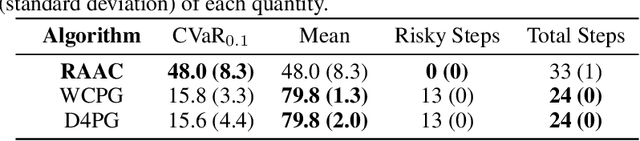

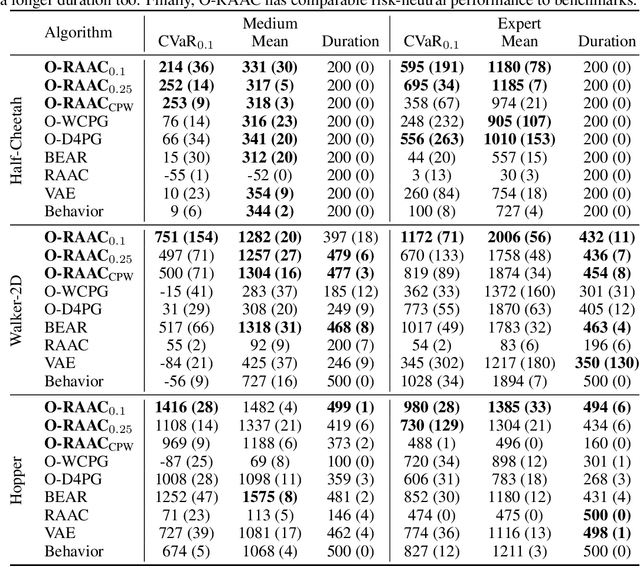
Training Reinforcement Learning (RL) agents in high-stakes applications might be too prohibitive due to the risk associated to exploration. Thus, the agent can only use data previously collected by safe policies. While previous work considers optimizing the average performance using offline data, we focus on optimizing a risk-averse criteria, namely the CVaR. In particular, we present the Offline Risk-Averse Actor-Critic (O-RAAC), a model-free RL algorithm that is able to learn risk-averse policies in a fully offline setting. We show that O-RAAC learns policies with higher CVaR than risk-neutral approaches in different robot control tasks. Furthermore, considering risk-averse criteria guarantees distributional robustness of the average performance with respect to particular distribution shifts. We demonstrate empirically that in the presence of natural distribution-shifts, O-RAAC learns policies with good average performance.