 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Robustness Assessment: Adversarial Attacks on Learning-based Quadrupedal Locomotion Controllers
Paper and Code

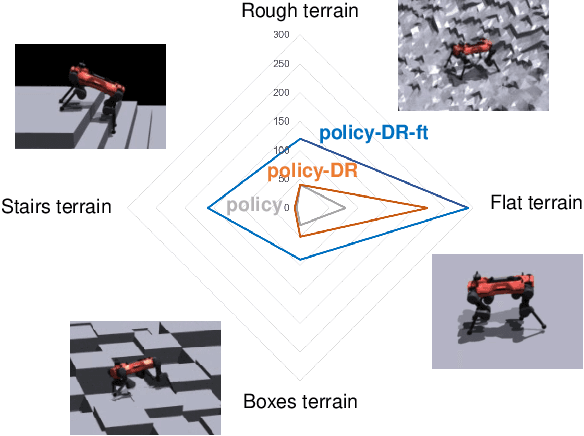


Legged locomotion has recently achieved remarkable success with the progress of machine learning techniques, especially deep reinforcement learning (RL). Controllers employing neural networks have demonstrated empirical and qualitative robustness against real-world uncertainties, including sensor noise and external perturbations. However, formally investigating the vulnerabilities of these locomotion controllers remains a challenge. This difficulty arises from the requirement to pinpoint vulnerabilities across a long-tailed distribution within a high-dimensional, temporally sequential space. As a first step towards quantitative verification, we propose a computational method that leverages sequential adversarial attacks to identify weaknesses in learned locomotion controllers. Our research demonstrates that, even state-of-the-art robust controllers can fail significantly under well-designed, low-magnitude adversarial sequence. Through experiments in simulation and on the real robot, we validate our approach's effectiveness, and we illustrate how the results it generates can be used to robustify the original policy and offer valuable insights into the safety of these black-box policies.