 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Robot Foundation Models Using Inductive Biases
May 15, 2025Safety is a critical requirement for the real-world deployment of robotic systems. Unfortunately, while current robot foundation models show promising generalization capabilities across a wide variety of tasks, they fail to address safety, an important aspect for ensuring long-term operation. Current robot foundation models assume that safe behavior should emerge by learning from a sufficiently large dataset of demonstrations. However, this approach has two clear major drawbacks. Firstly, there are no formal safety guarantees for a behavior cloning policy trained using supervised learning. Secondly, without explicit knowledge of any safety constraints, the policy may require an unreasonable number of additional demonstrations to even approximate the desired constrained behavior. To solve these key issues, we show how we can instead combine robot foundation models with geometric inductive biases using ATACOM, a safety layer placed after the foundation policy that ensures safe state transitions by enforcing action constraints. With this approach, we can ensure formal safety guarantees for generalist policies without providing extensive demonstrations of safe behavior, and without requiring any specific fine-tuning for safety. Our experiments show that our approach can be beneficial both for classical manipulation tasks, where we avoid unwanted collisions with irrelevant objects, and for dynamic tasks, such as the robot air hockey environment, where we can generate fast trajectories respecting complex tasks and joint space constraints.
Robust Localization, Mapping, and Navigation for Quadruped Robots
May 04, 2025Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
Towards Safe Robot Foundation Models
Mar 10, 2025Robot foundation models hold the potential for deployment across diverse environments, from industrial applications to household tasks. While current research focuses primarily on the policies' generalization capabilities across a variety of tasks, it fails to address safety, a critical requirement for deployment on real-world systems. In this paper, we introduce a safety layer designed to constrain the action space of any generalist policy appropriately. Our approach uses ATACOM, a safe reinforcement learning algorithm that creates a safe action space and, therefore, ensures safe state transitions. By extending ATACOM to generalist policies, our method facilitates their deployment in safety-critical scenarios without requiring any specific safety fine-tuning. We demonstrate the effectiveness of this safety layer in an air hockey environment, where it prevents a puck-hitting agent from colliding with its surroundings, a failure observed in generalist policies.
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Sep 18, 2024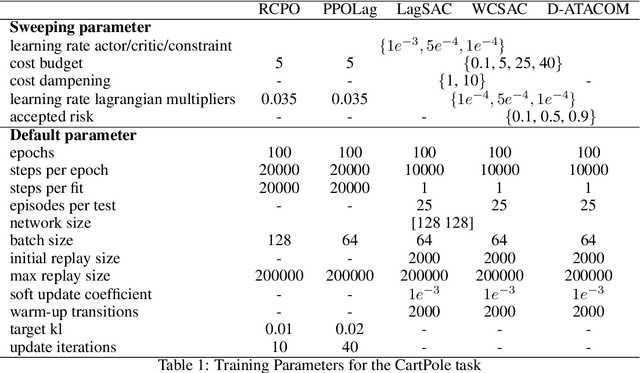

Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Sep 10, 2024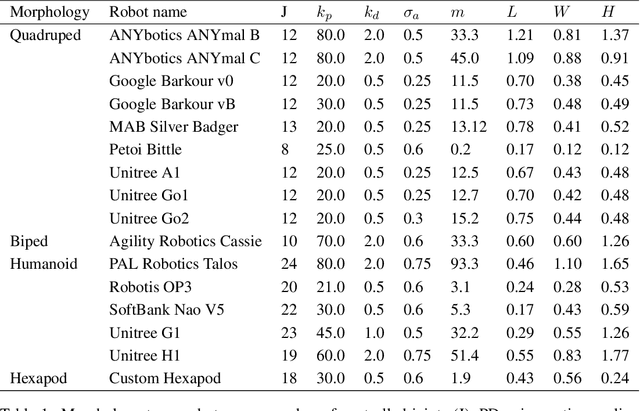
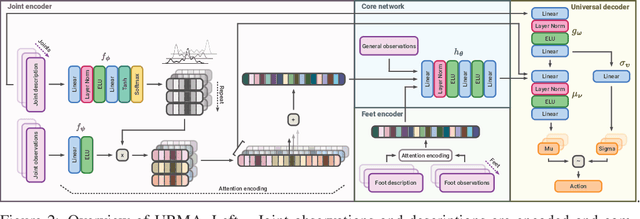

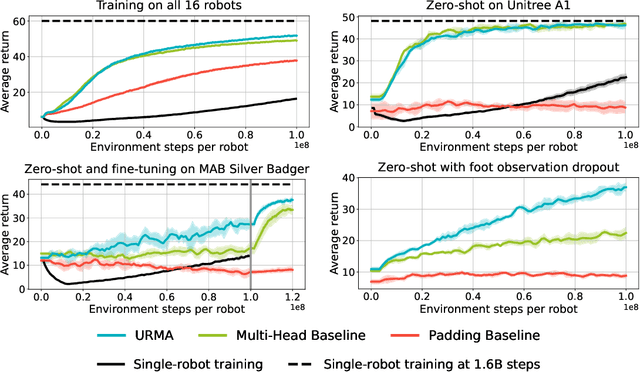
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
Adaptive Control based Friction Estimation for Tracking Control of Robot Manipulators
Sep 08, 2024
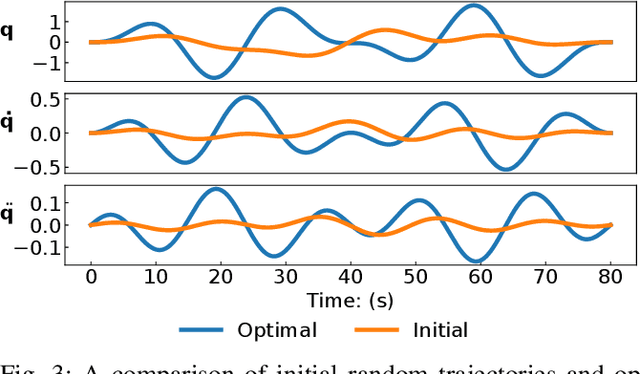
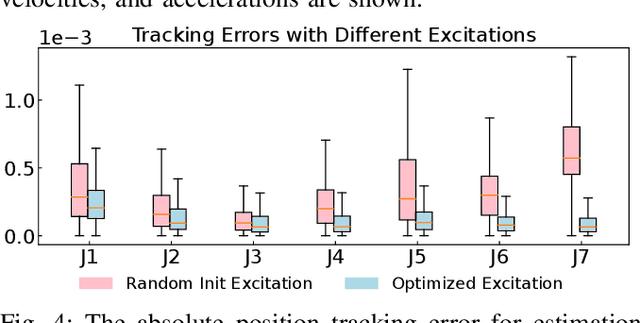
Adaptive control is often used for friction compensation in trajectory tracking tasks because it does not require torque sensors. However, it has some drawbacks: first, the most common certainty-equivalence adaptive control design is based on linearized parameterization of the friction model, therefore nonlinear effects, including the stiction and Stribeck effect, are usually omitted. Second, the adaptive control-based estimation can be biased due to non-zero steady-state error. Third, neglecting unknown model mismatch could result in non-robust estimation. This paper proposes a novel linear parameterized friction model capturing the nonlinear static friction phenomenon. Subsequently, an adaptive control-based friction estimator is proposed to reduce the bias during estimation based on backstepping. Finally, we propose an algorithm to generate excitation for robust estimation. Using a KUKA iiwa 14, we conducted trajectory tracking experiments to evaluate the estimated friction model, including random Fourier and drawing trajectories, showing the effectiveness of our methodology in different control schemes.
Safe and Efficient Path Planning under Uncertainty via Deep Collision Probability Fields
Sep 06, 2024



Estimating collision probabilities between robots and environmental obstacles or other moving agents is crucial to ensure safety during path planning. This is an important building block of modern planning algorithms in many application scenarios such as autonomous driving, where noisy sensors perceive obstacles. While many approaches exist, they either provide too conservative estimates of the collision probabilities or are computationally intensive due to their sampling-based nature. To deal with these issues, we introduce Deep Collision Probability Fields, a neural-based approach for computing collision probabilities of arbitrary objects with arbitrary unimodal uncertainty distributions. Our approach relegates the computationally intensive estimation of collision probabilities via sampling at the training step, allowing for fast neural network inference of the constraints during planning. In extensive experiments, we show that Deep Collision Probability Fields can produce reasonably accurate collision probabilities (up to 10^{-3}) for planning and that our approach can be easily plugged into standard path planning approaches to plan safe paths on 2-D maps containing uncertain static and dynamic obstacles. Additional material, code, and videos are available at https://sites.google.com/view/ral-dcpf.
Bridging the gap between Learning-to-plan, Motion Primitives and Safe Reinforcement Learning
Aug 26, 2024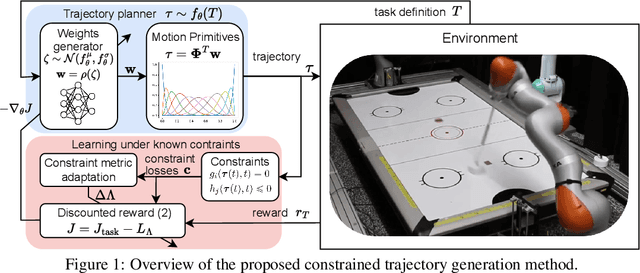

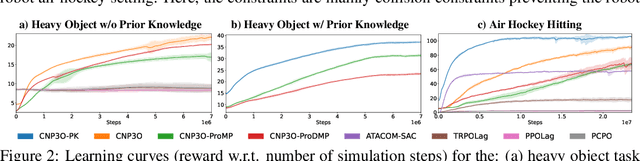

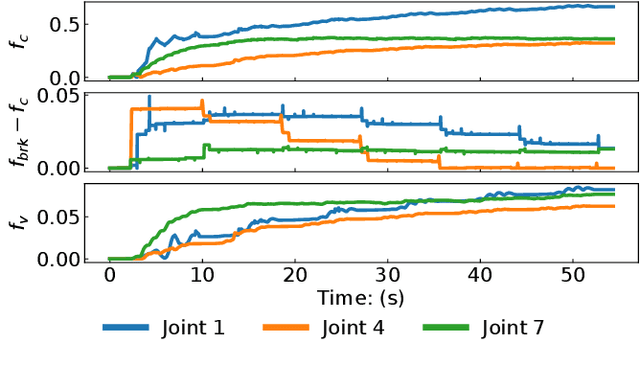
Trajectory planning under kinodynamic constraints is fundamental for advanced robotics applications that require dexterous, reactive, and rapid skills in complex environments. These constraints, which may represent task, safety, or actuator limitations, are essential for ensuring the proper functioning of robotic platforms and preventing unexpected behaviors. Recent advances in kinodynamic planning demonstrate that learning-to-plan techniques can generate complex and reactive motions under intricate constraints. However, these techniques necessitate the analytical modeling of both the robot and the entire task, a limiting assumption when systems are extremely complex or when constructing accurate task models is prohibitive. This paper addresses this limitation by combining learning-to-plan methods with reinforcement learning, resulting in a novel integration of black-box learning of motion primitives and optimization. We evaluate our approach against state-of-the-art safe reinforcement learning methods, showing that our technique, particularly when exploiting task structure, outperforms baseline methods in challenging scenarios such as planning to hit in robot air hockey. This work demonstrates the potential of our integrated approach to enhance the performance and safety of robots operating under complex kinodynamic constraints.
Exciting Action: Investigating Efficient Exploration for Learning Musculoskeletal Humanoid Locomotion
Jul 16, 2024Learning a locomotion controller for a musculoskeletal system is challenging due to over-actuation and high-dimensional action space. While many reinforcement learning methods attempt to address this issue, they often struggle to learn human-like gaits because of the complexity involved in engineering an effective reward function. In this paper, we demonstrate that adversarial imitation learning can address this issue by analyzing key problems and providing solutions using both current literature and novel techniques. We validate our methodology by learning walking and running gaits on a simulated humanoid model with 16 degrees of freedom and 92 Muscle-Tendon Units, achieving natural-looking gaits with only a few demonstrations.