 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Guided Unsupervised Domain Adaptation for Robotic Semantic Segmentation
Feb 01, 2026Semantic segmentation networks, which are essential for robotic perception, often suffer from performance degradation when the visual distribution of the deployment environment differs from that of the source dataset on which they were trained. Unsupervised Domain Adaptation (UDA) addresses this challenge by adapting the network to the robot's target environment without external supervision, leveraging the large amounts of data a robot might naturally collect during long-term operation. In such settings, UDA methods can exploit multi-view consistency across the environment's map to fine-tune the model in an unsupervised fashion and mitigate domain shift. However, these approaches remain sensitive to cross-view instance-level inconsistencies. In this work, we propose a method that starts from a volumetric 3D map to generate multi-view consistent pseudo-labels. We then refine these labels using the zero-shot instance segmentation capabilities of a foundation model, enforcing instance-level coherence. The refined annotations serve as supervision for self-supervised fine-tuning, enabling the robot to adapt its perception system at deployment time. Experiments on real-world data demonstrate that our approach consistently improves performance over state-of-the-art UDA baselines based on multi-view consistency, without requiring any ground-truth labels in the target domain.
Robust Localization, Mapping, and Navigation for Quadruped Robots
May 04, 2025Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
Estimating Map Completeness in Robot Exploration
Jun 19, 2024In this paper, we propose a method that, given a partial grid map of an indoor environment built by an autonomous mobile robot, estimates the amount of the explored area represented in the map, as well as whether the uncovered part is still worth being explored or not. Our method is based on a deep convolutional neural network trained on data from partially explored environments with annotations derived from the knowledge of the entire map (which is not available when the network is used for inference). We show how such a network can be used to define a stopping criterion to terminate the exploration process when it is no longer adding relevant details about the environment to the map, saving, on average, 40% of the total exploration time with respect to covering all the area of the environment.
Frontier-Based Exploration for Multi-Robot Rendezvous in Communication-Restricted Unknown Environments
Mar 27, 2024Multi-robot rendezvous and exploration are fundamental challenges in the domain of mobile robotic systems. This paper addresses multi-robot rendezvous within an initially unknown environment where communication is only possible after the rendezvous. Traditionally, exploration has been focused on rapidly mapping the environment, often leading to suboptimal rendezvous performance in later stages. We adapt a standard frontier-based exploration technique to integrate exploration and rendezvous into a unified strategy, with a mechanism that allows robots to re-visit previously explored regions thus enhancing rendezvous opportunities. We validate our approach in 3D realistic simulations using ROS, showcasing its effectiveness in achieving faster rendezvous times compared to exploration strategies.
R2SNet: Scalable Domain Adaptation for Object Detection in Cloud-Based Robots Ecosystems via Proposal Refinement
Mar 21, 2024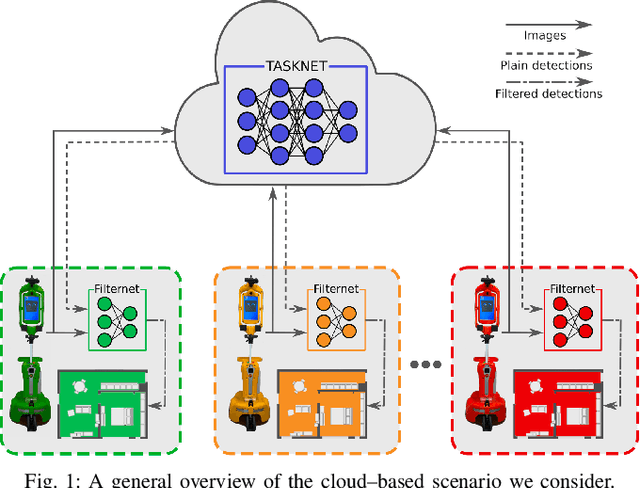

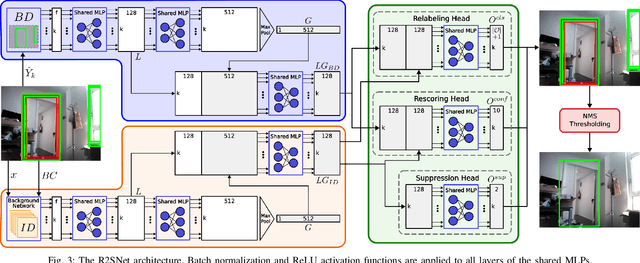
We introduce a novel approach for scalable domain adaptation in cloud robotics scenarios where robots rely on third-party AI inference services powered by large pre-trained deep neural networks. Our method is based on a downstream proposal-refinement stage running locally on the robots, exploiting a new lightweight DNN architecture, R2SNet. This architecture aims to mitigate performance degradation from domain shifts by adapting the object detection process to the target environment, focusing on relabeling, rescoring, and suppression of bounding-box proposals. Our method allows for local execution on robots, addressing the scalability challenges of domain adaptation without incurring significant computational costs. Real-world results on mobile service robots performing door detection show the effectiveness of the proposed method in achieving scalable domain adaptation.
Development and Adaptation of Robotic Vision in the Real-World: the Challenge of Door Detection
Jan 31, 2024Mobile service robots are increasingly prevalent in human-centric, real-world domains, operating autonomously in unconstrained indoor environments. In such a context, robotic vision plays a central role in enabling service robots to perceive high-level environmental features from visual observations. Despite the data-driven approaches based on deep learning push the boundaries of vision systems, applying these techniques to real-world robotic scenarios presents unique methodological challenges. Traditional models fail to represent the challenging perception constraints typical of service robots and must be adapted for the specific environment where robots finally operate. We propose a method leveraging photorealistic simulations that balances data quality and acquisition costs for synthesizing visual datasets from the robot perspective used to train deep architectures. Then, we show the benefits in qualifying a general detector for the target domain in which the robot is deployed, showing also the trade-off between the effort for obtaining new examples from such a setting and the performance gain. In our extensive experimental campaign, we focus on the door detection task (namely recognizing the presence and the traversability of doorways) that, in dynamic settings, is useful to infer the topology of the map. Our findings are validated in a real-world robot deployment, comparing prominent deep-learning models and demonstrating the effectiveness of our approach in practical settings.
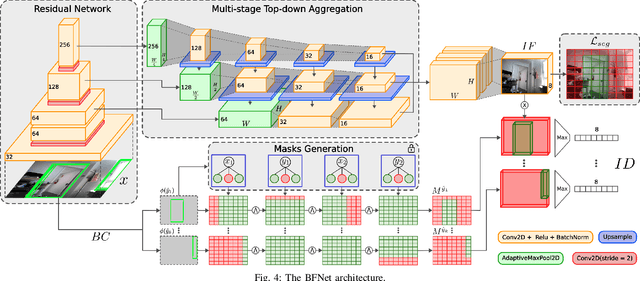
Enhancing Door Detection for Autonomous Mobile Robots with Environment-Specific Data Collection
Mar 08, 2022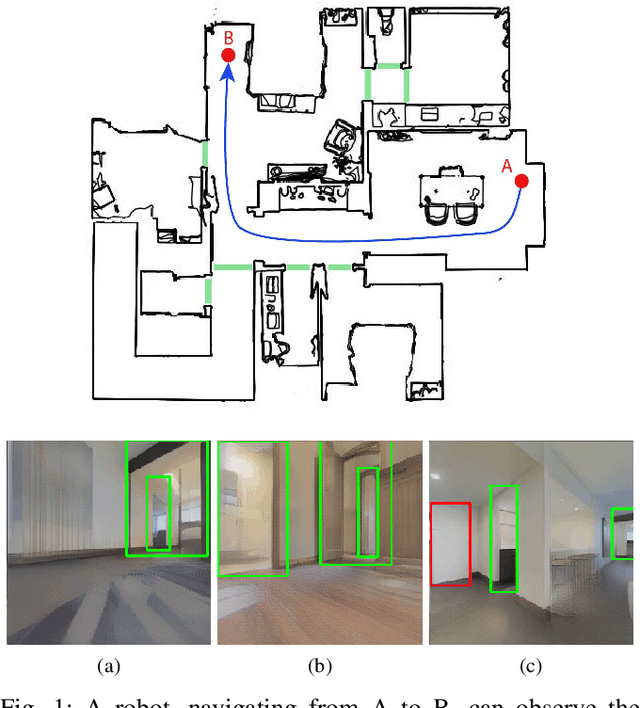
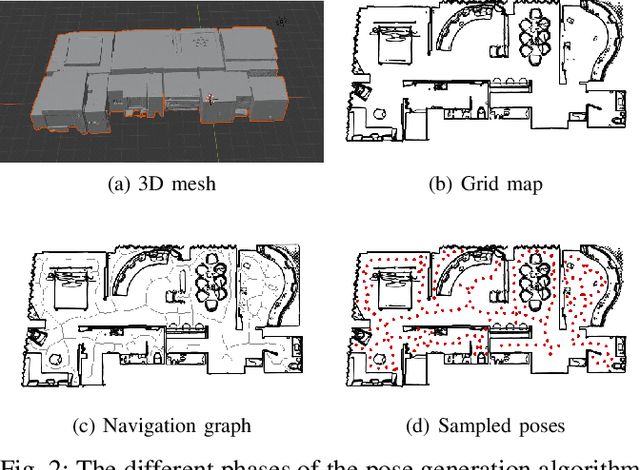

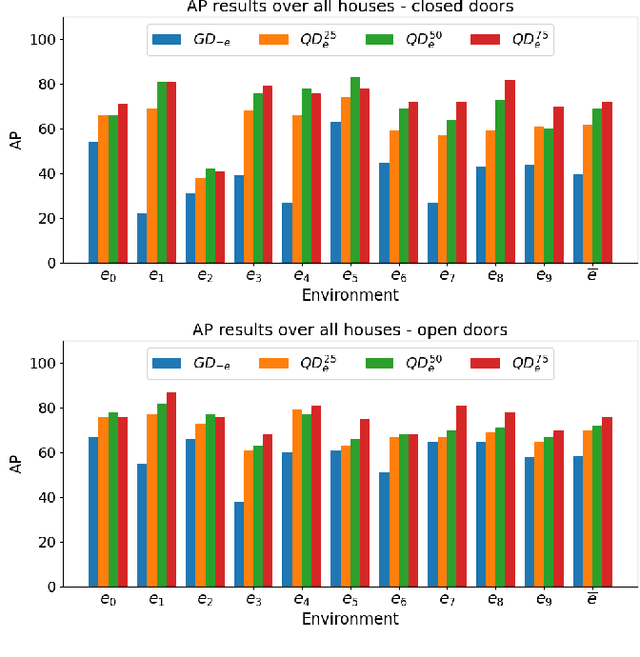
Door detection represents a fundamental capability for autonomous mobile robots employed in tasks involving indoor navigation. Recognizing the presence of a door and its status (open or closed) can induce a remarkable impact on the navigation performance, especially for dynamic settings where doors can enable or disable passages, hence changing the actual topology of the map. In this work, we address the problem of building a door detector module for an autonomous mobile robot deployed in a long-term scenario, namely operating in the same environment for a long time, thus observing the same set of doors from different points of view. First, we show how the mainstream approach for door detection, based on object recognition, falls short in considering the constrained perception setup typical of a mobile robot. Hence, we devise a method to build a dataset of images taken from a robot's perspective and we exploit it to obtain a door detector based on an established deep-learning object-recognition method. We then exploit the long-term assumption of our scenario to qualify the model on the robot working environment via fine-tuning with additional images acquired in the deployment environment. Our experimental analysis shows how this method can achieve good performance and highlights a trade-off between costs and benefits of the fine-tuning approach.
Robust Structure Identification and Room Segmentation of Cluttered Indoor Environments from Occupancy Grid Maps
Mar 07, 2022

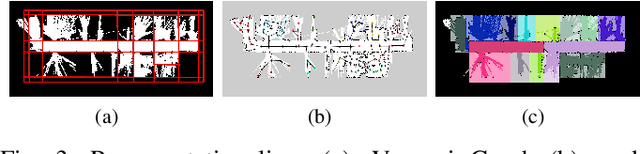

Identifying the environment's structure, i.e., to detect core components as rooms and walls, can facilitate several tasks fundamental for the successful operation of indoor autonomous mobile robots, including semantic environment understanding. These robots often rely on 2D occupancy maps for core tasks such as localisation and motion and task planning. However, reliable identification of structure and room segmentation from 2D occupancy maps is still an open problem due to clutter (e.g., furniture and movable object), occlusions, and partial coverage. We propose a method for the RObust StructurE identification and ROom SEgmentation (ROSE^2 ) of 2D occupancy maps, which may be cluttered and incomplete. ROSE^2 identifies the main directions of walls and is resilient to clutter and partial observations, allowing to extract a clean, abstract geometrical floor-plan-like description of the environment, which is used to segment, i.e., to identify rooms in, the original occupancy grid map. ROSE^2 is tested in several real-world publicly-available cluttered maps obtained in different conditions. The results show how it can robustly identify the environment structure in 2D occupancy maps suffering from clutter and partial observations, while significantly improving room segmentation accuracy. Thanks to the combination of clutter removal and robust room segmentation ROSE^2 consistently achieves higher performance than the state-of-the-art methods, against which it is compared.
Predicting Performance of SLAM Algorithms
Sep 06, 2021



Among the abilities that autonomous mobile robots should exhibit, map building and localization are definitely recognized as fundamental. Consequently, countless algorithms for solving the Simultaneous Localization And Mapping (SLAM) problem have been proposed. Currently, their evaluation is performed ex-post, according to outcomes obtained when running the algorithms on data collected by robots in real or simulated environments. In this paper, we present a novel method that allows the ex-ante prediction of the performance of a SLAM algorithm in an unseen environment, before it is actually run. Our method collects the performance of a SLAM algorithm in a number of simulated environments, builds a model that represents the relationship between the observed performance and some geometrical features of the environments, and exploits such model to predict the performance of the algorithm in an unseen environment starting from its features.
Exploration of Indoor Environments Predicting the Layout of Partially Observed Rooms
Apr 15, 2020



We consider exploration tasks in which an autonomous mobile robot incrementally builds maps of initially unknown indoor environments. In such tasks, the robot makes a sequence of decisions on where to move next that, usually, are based on knowledge about the observed parts of the environment. In this paper, we present an approach that exploits a prediction of the geometric structure of the unknown parts of an environment to improve exploration performance. In particular, we leverage an existing method that reconstructs the layout of an environment starting from a partial grid map and that predicts the shape of partially observed rooms on the basis of geometric features representing the regularities of the indoor environment. Then, we originally employ the predicted layout to estimate the amount of new area the robot would observe from candidate locations in order to inform the selection of the next best location and to early stop the exploration when no further relevant area is expected to be discovered. Experimental activities show that our approach is able to effectively predict the layout of partially observed rooms and to use such knowledge to speed up the exploration.