 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Embodiment Scaling Laws in Robot Locomotion
May 09, 2025Developing generalist agents that can operate across diverse tasks, environments, and physical embodiments is a grand challenge in robotics and artificial intelligence. In this work, we focus on the axis of embodiment and investigate embodiment scaling laws$\unicode{x2013}$the hypothesis that increasing the number of training embodiments improves generalization to unseen ones. Using robot locomotion as a test bed, we procedurally generate a dataset of $\sim$1,000 varied embodiments, spanning humanoids, quadrupeds, and hexapods, and train generalist policies capable of handling diverse observation and action spaces on random subsets. We find that increasing the number of training embodiments improves generalization to unseen ones, and scaling embodiments is more effective in enabling embodiment-level generalization than scaling data on small, fixed sets of embodiments. Notably, our best policy, trained on the full dataset, zero-shot transfers to novel embodiments in the real world, such as Unitree Go2 and H1. These results represent a step toward general embodied intelligence, with potential relevance to adaptive control for configurable robots, co-design of morphology and control, and beyond.
Robust Localization, Mapping, and Navigation for Quadruped Robots
May 04, 2025Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
Gait in Eight: Efficient On-Robot Learning for Omnidirectional Quadruped Locomotion
Mar 11, 2025



On-robot Reinforcement Learning is a promising approach to train embodiment-aware policies for legged robots. However, the computational constraints of real-time learning on robots pose a significant challenge. We present a framework for efficiently learning quadruped locomotion in just 8 minutes of raw real-time training utilizing the sample efficiency and minimal computational overhead of the new off-policy algorithm CrossQ. We investigate two control architectures: Predicting joint target positions for agile, high-speed locomotion and Central Pattern Generators for stable, natural gaits. While prior work focused on learning simple forward gaits, our framework extends on-robot learning to omnidirectional locomotion. We demonstrate the robustness of our approach in different indoor and outdoor environments.
Massively Scaling Explicit Policy-conditioned Value Functions
Feb 17, 2025

We introduce a scaling strategy for Explicit Policy-Conditioned Value Functions (EPVFs) that significantly improves performance on challenging continuous-control tasks. EPVFs learn a value function V({\theta}) that is explicitly conditioned on the policy parameters, enabling direct gradient-based updates to the parameters of any policy. However, EPVFs at scale struggle with unrestricted parameter growth and efficient exploration in the policy parameter space. To address these issues, we utilize massive parallelization with GPU-based simulators, big batch sizes, weight clipping and scaled peturbations. Our results show that EPVFs can be scaled to solve complex tasks, such as a custom Ant environment, and can compete with state-of-the-art Deep Reinforcement Learning (DRL) baselines like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC). We further explore action-based policy parameter representations from previous work and specialized neural network architectures to efficiently handle weight-space features, which have not been used in the context of DRL before.
One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Sep 10, 2024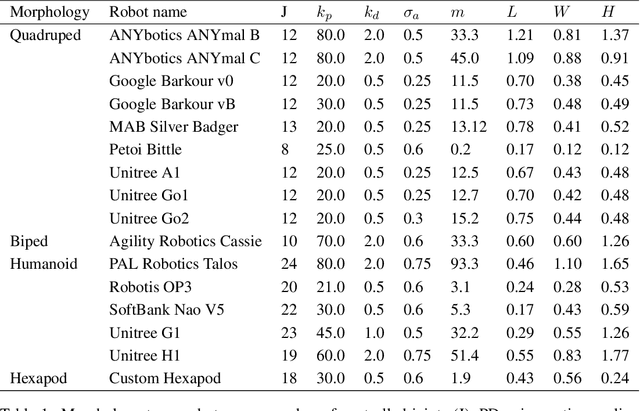
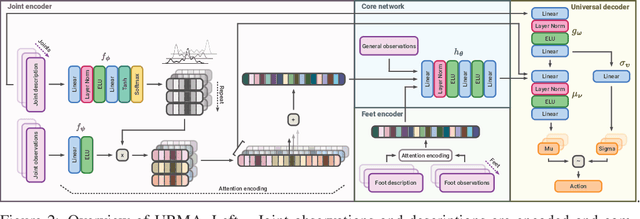

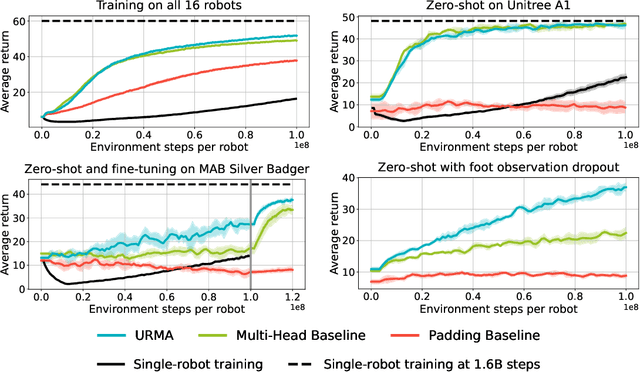
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
RL-X: A Deep Reinforcement Learning Library for RoboCup
Oct 20, 2023



This paper presents the new Deep Reinforcement Learning (DRL) library RL-X and its application to the RoboCup Soccer Simulation 3D League and classic DRL benchmarks. RL-X provides a flexible and easy-to-extend codebase with self-contained single directory algorithms. Through the fast JAX-based implementations, RL-X can reach up to 4.5x speedups compared to well-known frameworks like Stable-Baselines3.