 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Localization, Mapping, and Navigation for Quadruped Robots
May 04, 2025Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
Adaptive Control based Friction Estimation for Tracking Control of Robot Manipulators
Sep 08, 2024
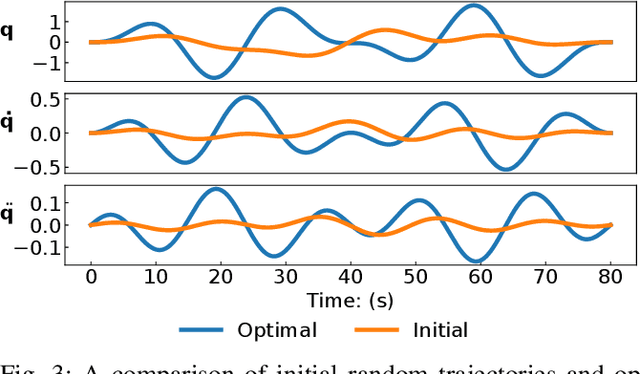
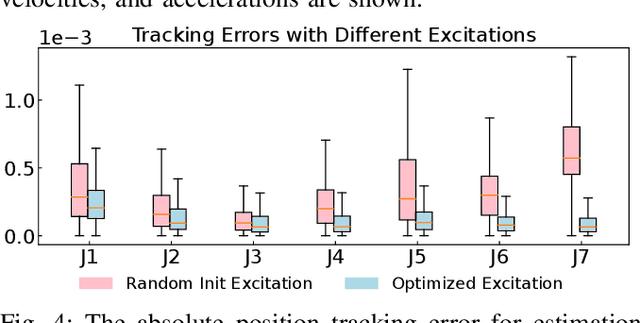
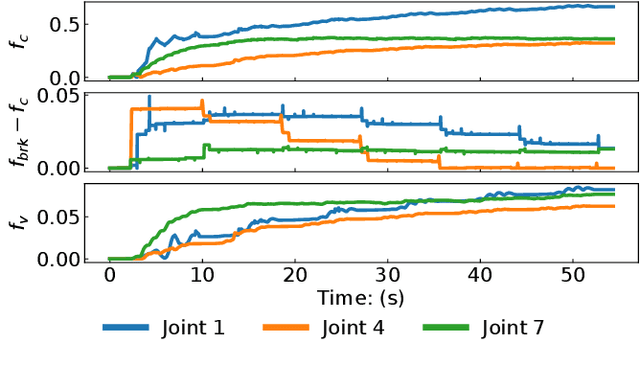
Adaptive control is often used for friction compensation in trajectory tracking tasks because it does not require torque sensors. However, it has some drawbacks: first, the most common certainty-equivalence adaptive control design is based on linearized parameterization of the friction model, therefore nonlinear effects, including the stiction and Stribeck effect, are usually omitted. Second, the adaptive control-based estimation can be biased due to non-zero steady-state error. Third, neglecting unknown model mismatch could result in non-robust estimation. This paper proposes a novel linear parameterized friction model capturing the nonlinear static friction phenomenon. Subsequently, an adaptive control-based friction estimator is proposed to reduce the bias during estimation based on backstepping. Finally, we propose an algorithm to generate excitation for robust estimation. Using a KUKA iiwa 14, we conducted trajectory tracking experiments to evaluate the estimated friction model, including random Fourier and drawing trajectories, showing the effectiveness of our methodology in different control schemes.
How Crucial is Transformer in Decision Transformer?
Nov 26, 2022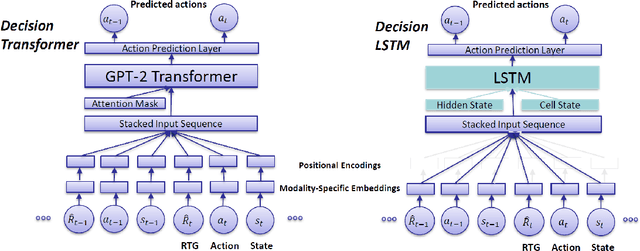
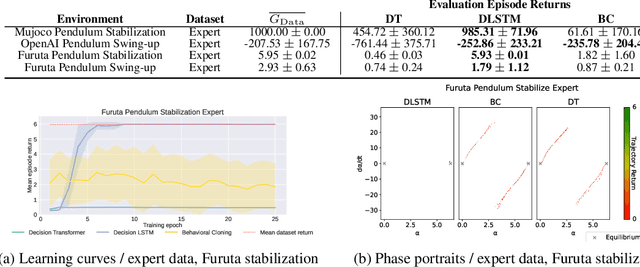
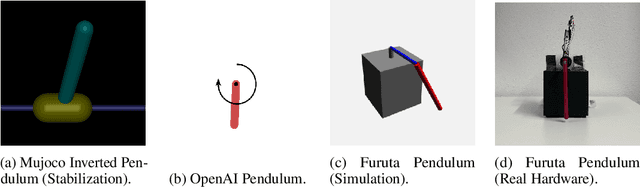
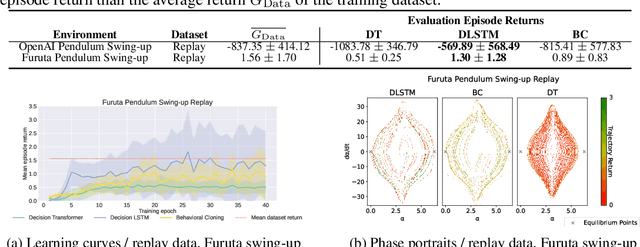
Decision Transformer (DT) is a recently proposed architecture for Reinforcement Learning that frames the decision-making process as an auto-regressive sequence modeling problem and uses a Transformer model to predict the next action in a sequence of states, actions, and rewards. In this paper, we analyze how crucial the Transformer model is in the complete DT architecture on continuous control tasks. Namely, we replace the Transformer by an LSTM model while keeping the other parts unchanged to obtain what we call a Decision LSTM model. We compare it to DT on continuous control tasks, including pendulum swing-up and stabilization, in simulation and on physical hardware. Our experiments show that DT struggles with continuous control problems, such as inverted pendulum and Furuta pendulum stabilization. On the other hand, the proposed Decision LSTM is able to achieve expert-level performance on these tasks, in addition to learning a swing-up controller on the real system. These results suggest that the strength of the Decision Transformer for continuous control tasks may lie in the overall sequential modeling architecture and not in the Transformer per se.
Learning Driving Decisions by Imitating Drivers' Control Behaviors
Nov 30, 2019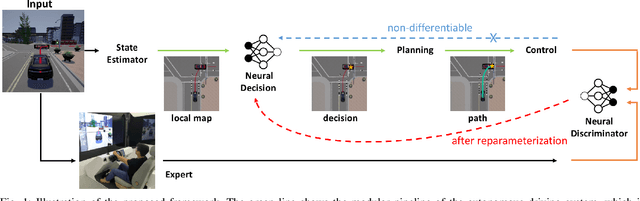



Classical autonomous driving systems are modularized as a pipeline of perception, decision, planning, and control. The driving decision plays a central role in processing the observation from the perception as well as directing the execution of downstream planning and control modules. Commonly the decision module is designed to be rule-based and is difficult to learn from data. Recently end-to-end neural control policy has been proposed to replace this pipeline, given its generalization ability. However, it remains challenging to enforce physical or logical constraints on the decision to ensure driving safety and stability. In this work, we propose a hybrid framework for learning a decision module, which is agnostic to the mechanisms of perception, planning, and control modules. By imitating the low-level control behavior, it learns the high-level driving decisions while bypasses the ambiguous annotation of high-level driving decisions. We demonstrate that the simulation agents with a learned decision module can be generalized to various complex driving scenarios where the rule-based approach fails. Furthermore, it can generate driving behaviors that are smoother and safer than end-to-end neural policies.
NADPEx: An on-policy temporally consistent exploration method for deep reinforcement learning
Dec 24, 2018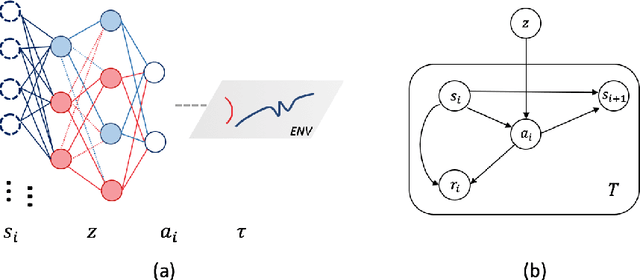
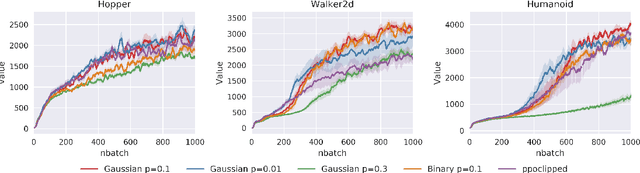
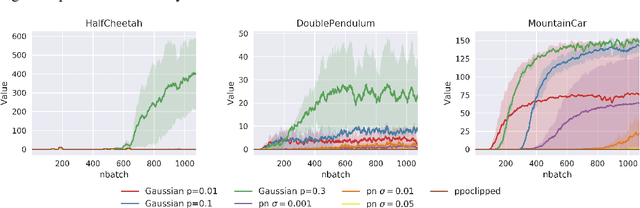
Reinforcement learning agents need exploratory behaviors to escape from local optima. These behaviors may include both immediate dithering perturbation and temporally consistent exploration. To achieve these, a stochastic policy model that is inherently consistent through a period of time is in desire, especially for tasks with either sparse rewards or long term information. In this work, we introduce a novel on-policy temporally consistent exploration strategy - Neural Adaptive Dropout Policy Exploration (NADPEx) - for deep reinforcement learning agents. Modeled as a global random variable for conditional distribution, dropout is incorporated to reinforcement learning policies, equipping them with inherent temporal consistency, even when the reward signals are sparse. Two factors, gradients' alignment with the objective and KL constraint in policy space, are discussed to guarantee NADPEx policy's stable improvement. Our experiments demonstrate that NADPEx solves tasks with sparse reward while naive exploration and parameter noise fail. It yields as well or even faster convergence in the standard mujoco benchmark for continuous control.