 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NEOLIX Open Dataset for AutonomousDriving
Nov 27, 2020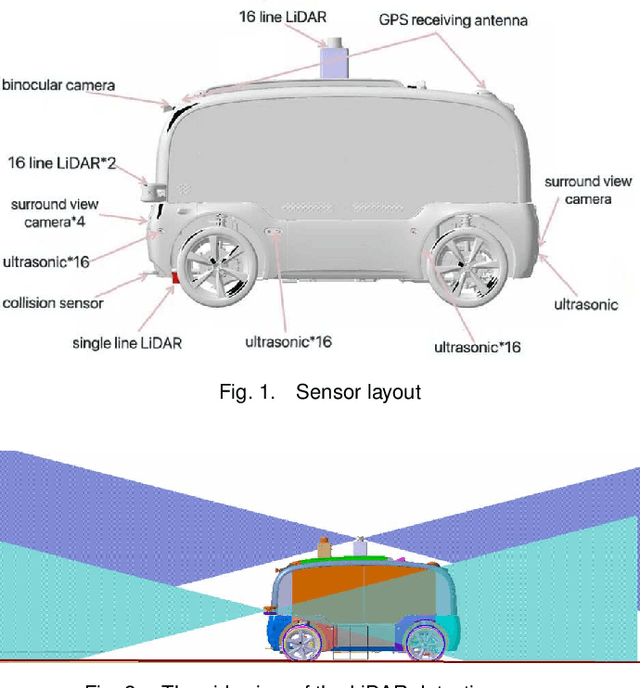


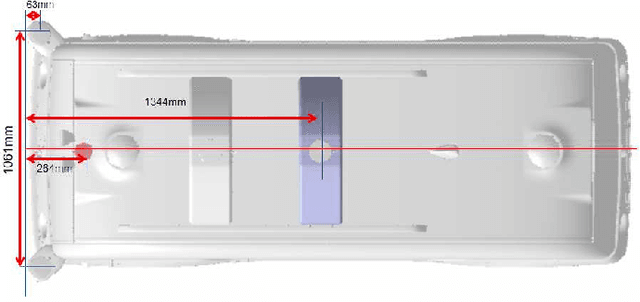
With the gradual maturity of 5G technology,autonomous driving technology has attracted moreand more attention among the research commu-nity. Autonomous driving vehicles rely on the co-operation of artificial intelligence, visual comput-ing, radar, monitoring equipment and GPS, whichenables computers to operate motor vehicles auto-matically and safely without human interference.However, the large-scale dataset for training andsystem evaluation is still a hot potato in the devel-opment of robust perception models. In this paper,we present the NEOLIX dataset and its applica-tions in the autonomous driving area. Our datasetincludes about 30,000 frames with point cloud la-bels, and more than 600k 3D bounding boxes withannotations. The data collection covers multipleregions, and various driving conditions, includingday, night, dawn, dusk and sunny day. In orderto label this complete dataset, we developed vari-ous tools and algorithms specified for each task tospeed up the labelling process. It is expected thatour dataset and related algorithms can support andmotivate researchers for the further developmentof autonomous driving in the field of computer vi-sion.
Biased Estimates of Advantages over Path Ensembles
Sep 15, 2019
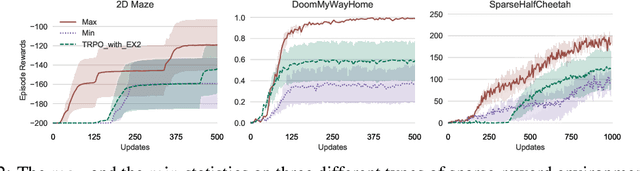
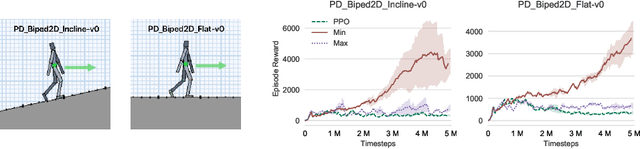
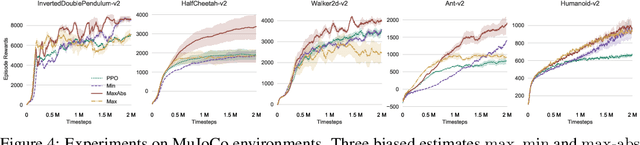
The estimation of advantage is crucial for a number of reinforcement learning algorithms, as it directly influences the choices of future paths. In this work, we propose a family of estimates based on the order statistics over the path ensemble, which allows one to flexibly drive the learning process, towards or against risks. On top of this formulation, we systematically study the impacts of different methods for estimating advantages. Our findings reveal that biased estimates, when chosen appropriately, can result in significant benefits. In particular, for the environments with sparse rewards, optimistic estimates would lead to more efficient exploration of the policy space; while for those where individual actions can have critical impacts, conservative estimates are preferable. On various benchmarks, including MuJoCo continuous control, Terrain locomotion, Atari games, and sparse-reward environments, the proposed biased estimation schemes consistently demonstrate improvement over mainstream methods, not only accelerating the learning process but also obtaining substantial performance gains.
NADPEx: An on-policy temporally consistent exploration method for deep reinforcement learning
Dec 24, 2018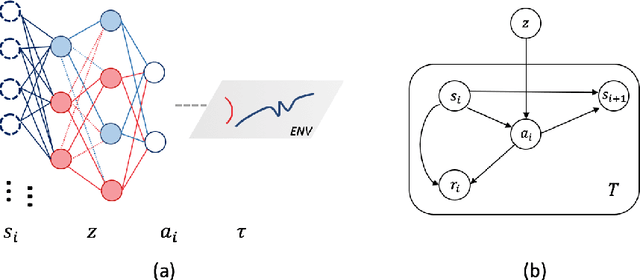
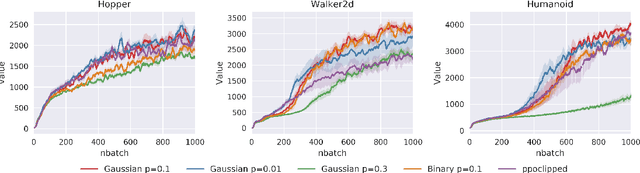
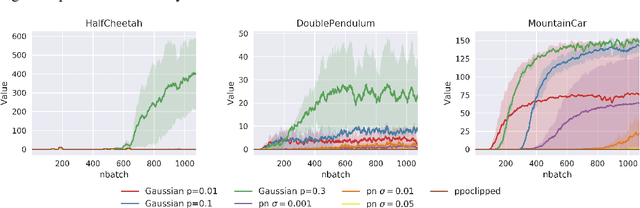
Reinforcement learning agents need exploratory behaviors to escape from local optima. These behaviors may include both immediate dithering perturbation and temporally consistent exploration. To achieve these, a stochastic policy model that is inherently consistent through a period of time is in desire, especially for tasks with either sparse rewards or long term information. In this work, we introduce a novel on-policy temporally consistent exploration strategy - Neural Adaptive Dropout Policy Exploration (NADPEx) - for deep reinforcement learning agents. Modeled as a global random variable for conditional distribution, dropout is incorporated to reinforcement learning policies, equipping them with inherent temporal consistency, even when the reward signals are sparse. Two factors, gradients' alignment with the objective and KL constraint in policy space, are discussed to guarantee NADPEx policy's stable improvement. Our experiments demonstrate that NADPEx solves tasks with sparse reward while naive exploration and parameter noise fail. It yields as well or even faster convergence in the standard mujoco benchmark for continuous control.