 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARBOR: A Harness Framework for Agentic Robot Reinforcement Learning
Jun 07, 2026Reinforcement learning (RL) has become a powerful paradigm for robot learning, particularly in sim-to-real settings, but its broader adoption remains limited by the engineering pipeline surrounding the algorithms. Building tasks, shaping rewards, and tuning hyperparameters require substantial expert effort, making RL workflows costly and difficult to scale. We introduce HARBOR, an agentic framework that frames robot RL automation as a harness-engineering problem: given a simulator codebase and a task specification, it automates the workflow from environment setup to policy training in simulation. HARBOR decomposes such high-level objectives into bounded stages executed by specialized agents through standardized commands, persistent artifacts, executable gates, and reusable knowledge, and scales iteration via decentralized parallel trials and experience learning across runs. We evaluate HARBOR across 6 benchmarks and 16 tasks in total, spanning manipulation, locomotion, and bimanual dexterous control. We demonstrate that HARBOR automates the simulation RL workflow end-to-end, designs rewards, tunes algorithms to match or improve over default configurations, and reduces engineering effort at practical token and wall-clock cost; the resulting policies can also be transferred to real robots.
Mind Your Steps: A General Learning Framework for Accurate Humanoid Foothold Tracking
Jun 06, 2026Enabling humanoid robots to operate in complex, dynamic environments remains a critical challenge, fundamentally limited by the ability to navigate robustly, safely, and accurately. While reinforcement learning with velocity-commanded policies has achieved remarkable robustness in humanoid locomotion, this approach lacks explicit control of the foothold placement, leading to unsafe behavior, such as stepping onto human feet, or imprecise navigation, hindering the following manipulation task. Conversely, explicit foothold-tracking policies offer a promising alternative by directly being commanded with target foot poses. However, existing approaches are often limited by unrealistic state assumptions, compromising real-world deployment, or they are part of staged pipelines, making them tied to specific downstream tasks. In this work, we introduce a novel, lightweight framework for training general-purpose 3D foothold-tracking policies. By dynamically providing footstep support through a goal sampler, this method enables the learned policy to be agnostic to specific terrains. Our new target representation effectively mitigates challenges arising in the real world, such as noisy and inaccurate pose estimation and foot contact estimation. Designed for direct real-world transfer, our policy acts as a standalone low-level controller that can be seamlessly paired with various high-level foothold generators. We demonstrate the effectiveness of our framework through extensive experiments in simulation and in the real world. By coupling our policy with different upstream planners, we achieve natural and accurate locomotion in challenging settings, paving the way for loco-manipulation tasks in complex environments.
CompliantVLA-adaptor: VLM-Guided Variable Impedance Action for Safe Contact-Rich Manipulation
Jan 21, 2026We propose a CompliantVLA-adaptor that augments the state-of-the-art Vision-Language-Action (VLA) models with vision-language model (VLM)-informed context-aware variable impedance control (VIC) to improve the safety and effectiveness of contact-rich robotic manipulation tasks. Existing VLA systems (e.g., RDT, Pi0, OpenVLA-oft) typically output position, but lack force-aware adaptation, leading to unsafe or failed interactions in physical tasks involving contact, compliance, or uncertainty. In the proposed CompliantVLA-adaptor, a VLM interprets task context from images and natural language to adapt the stiffness and damping parameters of a VIC controller. These parameters are further regulated using real-time force/torque feedback to ensure interaction forces remain within safe thresholds. We demonstrate that our method outperforms the VLA baselines on a suite of complex contact-rich tasks, both in simulation and on real hardware, with improved success rates and reduced force violations. The overall success rate across all tasks increases from 9.86\% to 17.29\%, presenting a promising path towards safe contact-rich manipulation using VLAs. We release our code, prompts, and force-torque-impedance-scenario context datasets at https://sites.google.com/view/compliantvla.
Maximum Total Correlation Reinforcement Learning
May 22, 2025Simplicity is a powerful inductive bias. In reinforcement learning, regularization is used for simpler policies, data augmentation for simpler representations, and sparse reward functions for simpler objectives, all that, with the underlying motivation to increase generalizability and robustness by focusing on the essentials. Supplementary to these techniques, we investigate how to promote simple behavior throughout the episode. To that end, we introduce a modification of the reinforcement learning problem that additionally maximizes the total correlation within the induced trajectories. We propose a practical algorithm that optimizes all models, including policy and state representation, based on a lower-bound approximation. In simulated robot environments, our method naturally generates policies that induce periodic and compressible trajectories, and that exhibit superior robustness to noise and changes in dynamics compared to baseline methods, while also improving performance in the original tasks.
Towards Safe Robot Foundation Models Using Inductive Biases
May 15, 2025Safety is a critical requirement for the real-world deployment of robotic systems. Unfortunately, while current robot foundation models show promising generalization capabilities across a wide variety of tasks, they fail to address safety, an important aspect for ensuring long-term operation. Current robot foundation models assume that safe behavior should emerge by learning from a sufficiently large dataset of demonstrations. However, this approach has two clear major drawbacks. Firstly, there are no formal safety guarantees for a behavior cloning policy trained using supervised learning. Secondly, without explicit knowledge of any safety constraints, the policy may require an unreasonable number of additional demonstrations to even approximate the desired constrained behavior. To solve these key issues, we show how we can instead combine robot foundation models with geometric inductive biases using ATACOM, a safety layer placed after the foundation policy that ensures safe state transitions by enforcing action constraints. With this approach, we can ensure formal safety guarantees for generalist policies without providing extensive demonstrations of safe behavior, and without requiring any specific fine-tuning for safety. Our experiments show that our approach can be beneficial both for classical manipulation tasks, where we avoid unwanted collisions with irrelevant objects, and for dynamic tasks, such as the robot air hockey environment, where we can generate fast trajectories respecting complex tasks and joint space constraints.
Morphologically Symmetric Reinforcement Learning for Ambidextrous Bimanual Manipulation
May 08, 2025Humans naturally exhibit bilateral symmetry in their gross manipulation skills, effortlessly mirroring simple actions between left and right hands. Bimanual robots-which also feature bilateral symmetry-should similarly exploit this property to perform tasks with either hand. Unlike humans, who often favor a dominant hand for fine dexterous skills, robots should ideally execute ambidextrous manipulation with equal proficiency. To this end, we introduce SYMDEX (SYMmetric DEXterity), a reinforcement learning framework for ambidextrous bi-manipulation that leverages the robot's inherent bilateral symmetry as an inductive bias. SYMDEX decomposes complex bimanual manipulation tasks into per-hand subtasks and trains dedicated policies for each. By exploiting bilateral symmetry via equivariant neural networks, experience from one arm is inherently leveraged by the opposite arm. We then distill the subtask policies into a global ambidextrous policy that is independent of the hand-task assignment. We evaluate SYMDEX on six challenging simulated manipulation tasks and demonstrate successful real-world deployment on two of them. Our approach strongly outperforms baselines on complex task in which the left and right hands perform different roles. We further demonstrate SYMDEX's scalability by extending it to a four-arm manipulation setup, where our symmetry-aware policies enable effective multi-arm collaboration and coordination. Our results highlight how structural symmetry as inductive bias in policy learning enhances sample efficiency, robustness, and generalization across diverse dexterous manipulation tasks.
Towards Safe Robot Foundation Models
Mar 10, 2025Robot foundation models hold the potential for deployment across diverse environments, from industrial applications to household tasks. While current research focuses primarily on the policies' generalization capabilities across a variety of tasks, it fails to address safety, a critical requirement for deployment on real-world systems. In this paper, we introduce a safety layer designed to constrain the action space of any generalist policy appropriately. Our approach uses ATACOM, a safe reinforcement learning algorithm that creates a safe action space and, therefore, ensures safe state transitions. By extending ATACOM to generalist policies, our method facilitates their deployment in safety-critical scenarios without requiring any specific safety fine-tuning. We demonstrate the effectiveness of this safety layer in an air hockey environment, where it prevents a puck-hitting agent from colliding with its surroundings, a failure observed in generalist policies.
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Sep 18, 2024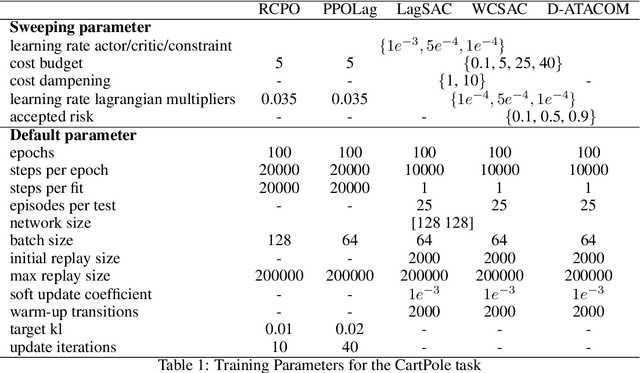

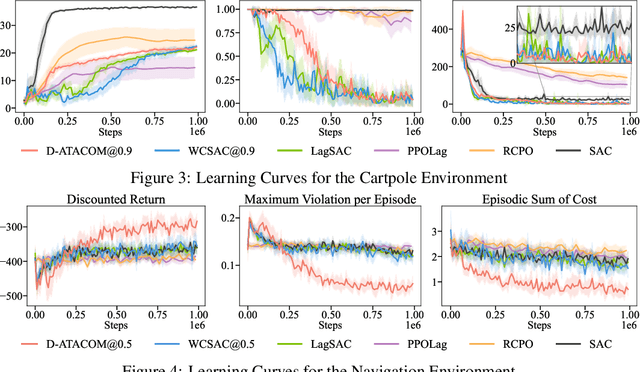
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Adaptive Control based Friction Estimation for Tracking Control of Robot Manipulators
Sep 08, 2024
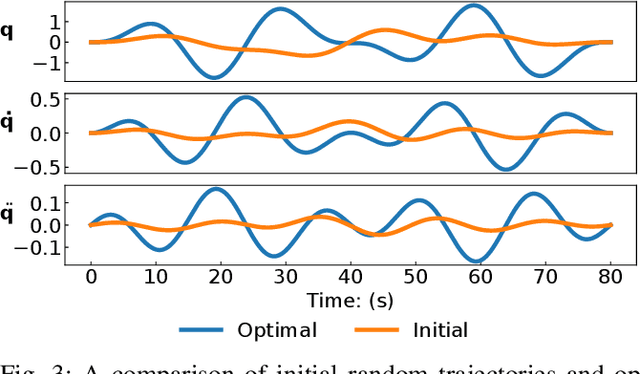
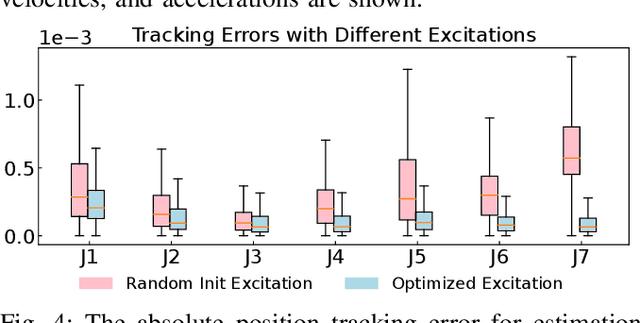
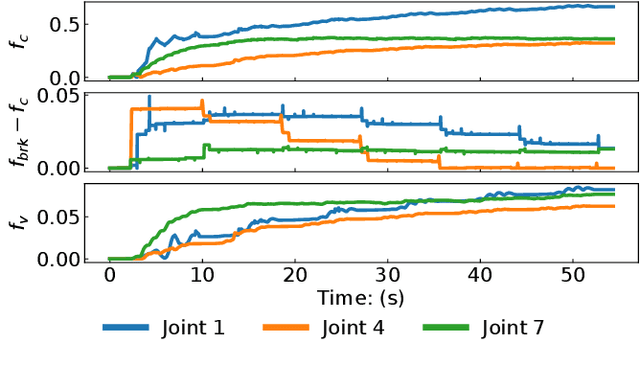
Adaptive control is often used for friction compensation in trajectory tracking tasks because it does not require torque sensors. However, it has some drawbacks: first, the most common certainty-equivalence adaptive control design is based on linearized parameterization of the friction model, therefore nonlinear effects, including the stiction and Stribeck effect, are usually omitted. Second, the adaptive control-based estimation can be biased due to non-zero steady-state error. Third, neglecting unknown model mismatch could result in non-robust estimation. This paper proposes a novel linear parameterized friction model capturing the nonlinear static friction phenomenon. Subsequently, an adaptive control-based friction estimator is proposed to reduce the bias during estimation based on backstepping. Finally, we propose an algorithm to generate excitation for robust estimation. Using a KUKA iiwa 14, we conducted trajectory tracking experiments to evaluate the estimated friction model, including random Fourier and drawing trajectories, showing the effectiveness of our methodology in different control schemes.