 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-AVIST: Reinforcement Learning for Autonomous Visual Inspection of Space Targets
Oct 26, 2025The growing need for autonomous on-orbit services such as inspection, maintenance, and situational awareness calls for intelligent spacecraft capable of complex maneuvers around large orbital targets. Traditional control systems often fall short in adaptability, especially under model uncertainties, multi-spacecraft configurations, or dynamically evolving mission contexts. This paper introduces RL-AVIST, a Reinforcement Learning framework for Autonomous Visual Inspection of Space Targets. Leveraging the Space Robotics Bench (SRB), we simulate high-fidelity 6-DOF spacecraft dynamics and train agents using DreamerV3, a state-of-the-art model-based RL algorithm, with PPO and TD3 as model-free baselines. Our investigation focuses on 3D proximity maneuvering tasks around targets such as the Lunar Gateway and other space assets. We evaluate task performance under two complementary regimes: generalized agents trained on randomized velocity vectors, and specialized agents trained to follow fixed trajectories emulating known inspection orbits. Furthermore, we assess the robustness and generalization of policies across multiple spacecraft morphologies and mission domains. Results demonstrate that model-based RL offers promising capabilities in trajectory fidelity, and sample efficiency, paving the way for scalable, retrainable control solutions for future space operations
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
Learning to Play Air Hockey with Model-Based Deep Reinforcement Learning
Jun 01, 2024



In the context of addressing the Robot Air Hockey Challenge 2023, we investigate the applicability of model-based deep reinforcement learning to acquire a policy capable of autonomously playing air hockey. Our agents learn solely from sparse rewards while incorporating self-play to iteratively refine their behaviour over time. The robotic manipulator is interfaced using continuous high-level actions for position-based control in the Cartesian plane while having partial observability of the environment with stochastic transitions. We demonstrate that agents are prone to overfitting when trained solely against a single playstyle, highlighting the importance of self-play for generalization to novel strategies of unseen opponents. Furthermore, the impact of the imagination horizon is explored in the competitive setting of the highly dynamic game of air hockey, with longer horizons resulting in more stable learning and better overall performance.
Leveraging Procedural Generation for Learning Autonomous Peg-in-Hole Assembly in Space
May 02, 2024The ability to autonomously assemble structures is crucial for the development of future space infrastructure. However, the unpredictable conditions of space pose significant challenges for robotic systems, necessitating the development of advanced learning techniques to enable autonomous assembly. In this study, we present a novel approach for learning autonomous peg-in-hole assembly in the context of space robotics. Our focus is on enhancing the generalization and adaptability of autonomous systems through deep reinforcement learning. By integrating procedural generation and domain randomization, we train agents in a highly parallelized simulation environment across a spectrum of diverse scenarios with the aim of acquiring a robust policy. The proposed approach is evaluated using three distinct reinforcement learning algorithms to investigate the trade-offs among various paradigms. We demonstrate the adaptability of our agents to novel scenarios and assembly sequences while emphasizing the potential of leveraging advanced simulation techniques for robot learning in space. Our findings set the stage for future advancements in intelligent robotic systems capable of supporting ambitious space missions and infrastructure development beyond Earth.
Immersive Rover Control and Obstacle Detection based on Extended Reality and Artificial Intelligence
Apr 22, 2024

Lunar exploration has become a key focus, driving scientific and technological advances. Ongoing missions are deploying rovers to the surface of the Moon, targeting the far side and south pole. However, these terrains pose challenges, emphasizing the need for precise obstacles and resource detection to avoid mission risks. This work proposes a novel system that integrates eXtended Reality (XR) and Artificial Intelligence (AI) to teleoperate lunar rovers. It is capable of autonomously detecting rocks and recreating an immersive 3D virtual environment of the location of the robot. This system has been validated in a lunar laboratory to observe its advantages over traditional 2D-based teleoperation approaches
GraspLDM: Generative 6-DoF Grasp Synthesis using Latent Diffusion Models
Dec 18, 2023



Vision-based grasping of unknown objects in unstructured environments is a key challenge for autonomous robotic manipulation. A practical grasp synthesis system is required to generate a diverse set of 6-DoF grasps from which a task-relevant grasp can be executed. Although generative models are suitable for learning such complex data distributions, existing models have limitations in grasp quality, long training times, and a lack of flexibility for task-specific generation. In this work, we present GraspLDM- a modular generative framework for 6-DoF grasp synthesis that uses diffusion models as priors in the latent space of a VAE. GraspLDM learns a generative model of object-centric $SE(3)$ grasp poses conditioned on point clouds. GraspLDM's architecture enables us to train task-specific models efficiently by only re-training a small de-noising network in the low-dimensional latent space, as opposed to existing models that need expensive re-training. Our framework provides robust and scalable models on both full and single-view point clouds. GraspLDM models trained with simulation data transfer well to the real world and provide an 80\% success rate for 80 grasp attempts of diverse test objects, improving over existing generative models. We make our implementation available at https://github.com/kuldeepbrd1/graspldm .
Learning to Grasp on the Moon from 3D Octree Observations with Deep Reinforcement Learning
Aug 01, 2022
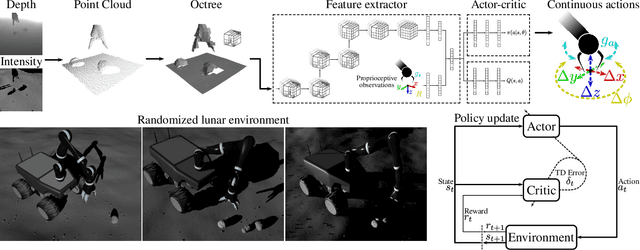
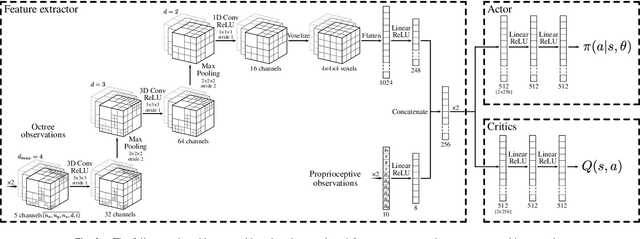
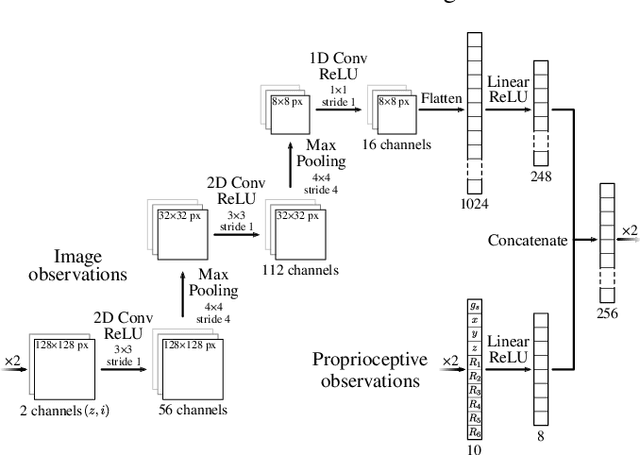
Extraterrestrial rovers with a general-purpose robotic arm have many potential applications in lunar and planetary exploration. Introducing autonomy into such systems is desirable for increasing the time that rovers can spend gathering scientific data and collecting samples. This work investigates the applicability of deep reinforcement learning for vision-based robotic grasping of objects on the Moon. A novel simulation environment with procedurally-generated datasets is created to train agents under challenging conditions in unstructured scenes with uneven terrain and harsh illumination. A model-free off-policy actor-critic algorithm is then employed for end-to-end learning of a policy that directly maps compact octree observations to continuous actions in Cartesian space. Experimental evaluation indicates that 3D data representations enable more effective learning of manipulation skills when compared to traditionally used image-based observations. Domain randomization improves the generalization of learned policies to novel scenes with previously unseen objects and different illumination conditions. To this end, we demonstrate zero-shot sim-to-real transfer by evaluating trained agents on a real robot in a Moon-analogue facility.