 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Inertia Parameter Estimation for Unknown Objects Grasped by a Manipulator Towards Space Applications
Dec 26, 2025Knowing the inertia parameters of a grasped object is crucial for dynamics-aware manipulation, especially in space robotics with free-floating bases. This work addresses the problem of estimating the inertia parameters of an unknown target object during manipulation. We apply and extend an existing online identification method by incorporating momentum conservation, enabling its use for the floating-base robots. The proposed method is validated through numerical simulations, and the estimated parameters are compared with ground-truth values. Results demonstrate accurate identification in the scenarios, highlighting the method's applicability to on-orbit servicing and other space missions.
Reinforcement Learning based 6-DoF Maneuvers for Microgravity Intravehicular Docking: A Simulation Study with Int-Ball2 in ISS-JEM
Dec 15, 2025Autonomous free-flyers play a critical role in intravehicular tasks aboard the International Space Station (ISS), where their precise docking under sensing noise, small actuation mismatches, and environmental variability remains a nontrivial challenge. This work presents a reinforcement learning (RL) framework for six-degree-of-freedom (6-DoF) docking of JAXA's Int-Ball2 robot inside a high-fidelity Isaac Sim model of the Japanese Experiment Module (JEM). Using Proximal Policy Optimization (PPO), we train and evaluate controllers under domain-randomized dynamics and bounded observation noise, while explicitly modeling propeller drag-torque effects and polarity structure. This enables a controlled study of how Int-Ball2's propulsion physics influence RL-based docking performance in constrained microgravity interiors. The learned policy achieves stable and reliable docking across varied conditions and lays the groundwork for future extensions pertaining to Int-Ball2 in collision-aware navigation, safe RL, propulsion-accurate sim-to-real transfer, and vision-based end-to-end docking.
RL-AVIST: Reinforcement Learning for Autonomous Visual Inspection of Space Targets
Oct 26, 2025The growing need for autonomous on-orbit services such as inspection, maintenance, and situational awareness calls for intelligent spacecraft capable of complex maneuvers around large orbital targets. Traditional control systems often fall short in adaptability, especially under model uncertainties, multi-spacecraft configurations, or dynamically evolving mission contexts. This paper introduces RL-AVIST, a Reinforcement Learning framework for Autonomous Visual Inspection of Space Targets. Leveraging the Space Robotics Bench (SRB), we simulate high-fidelity 6-DOF spacecraft dynamics and train agents using DreamerV3, a state-of-the-art model-based RL algorithm, with PPO and TD3 as model-free baselines. Our investigation focuses on 3D proximity maneuvering tasks around targets such as the Lunar Gateway and other space assets. We evaluate task performance under two complementary regimes: generalized agents trained on randomized velocity vectors, and specialized agents trained to follow fixed trajectories emulating known inspection orbits. Furthermore, we assess the robustness and generalization of policies across multiple spacecraft morphologies and mission domains. Results demonstrate that model-based RL offers promising capabilities in trajectory fidelity, and sample efficiency, paving the way for scalable, retrainable control solutions for future space operations
Unleashing the Power of Discrete-Time State Representation: Ultrafast Target-based IMU-Camera Spatial-Temporal Calibration
Sep 16, 2025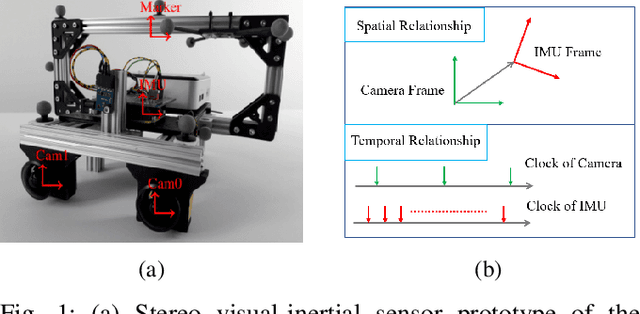
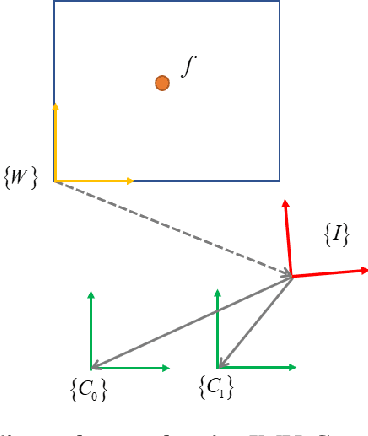
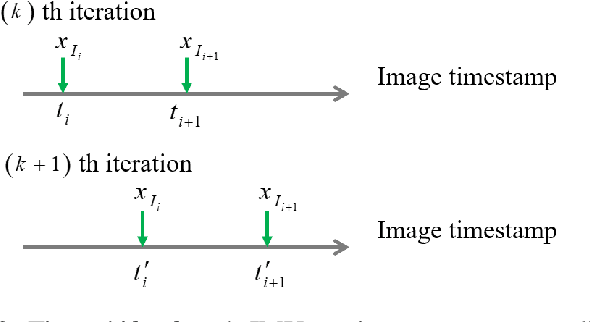
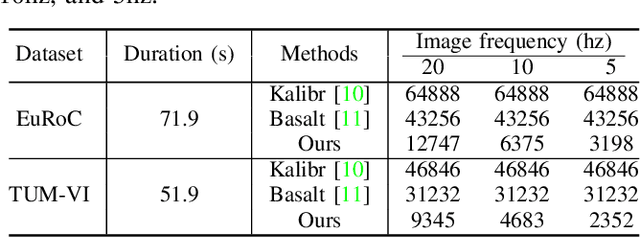
Visual-inertial fusion is crucial for a large amount of intelligent and autonomous applications, such as robot navigation and augmented reality. To bootstrap and achieve optimal state estimation, the spatial-temporal displacements between IMU and cameras must be calibrated in advance. Most existing calibration methods adopt continuous-time state representation, more specifically the B-spline. Despite these methods achieve precise spatial-temporal calibration, they suffer from high computational cost caused by continuous-time state representation. To this end, we propose a novel and extremely efficient calibration method that unleashes the power of discrete-time state representation. Moreover, the weakness of discrete-time state representation in temporal calibration is tackled in this paper. With the increasing production of drones, cellphones and other visual-inertial platforms, if one million devices need calibration around the world, saving one minute for the calibration of each device means saving 2083 work days in total. To benefit both the research and industry communities, our code will be open-source.
PLUME: Procedural Layer Underground Modeling Engine
Aug 28, 2025As space exploration advances, underground environments are becoming increasingly attractive due to their potential to provide shelter, easier access to resources, and enhanced scientific opportunities. Although such environments exist on Earth, they are often not easily accessible and do not accurately represent the diversity of underground environments found throughout the solar system. This paper presents PLUME, a procedural generation framework aimed at easily creating 3D underground environments. Its flexible structure allows for the continuous enhancement of various underground features, aligning with our expanding understanding of the solar system. The environments generated using PLUME can be used for AI training, evaluating robotics algorithms, 3D rendering, and facilitating rapid iteration on developed exploration algorithms. In this paper, it is demonstrated that PLUME has been used along with a robotic simulator. PLUME is open source and has been released on Github. https://github.com/Gabryss/P.L.U.M.E
NavBench: A Unified Robotics Benchmark for Reinforcement Learning-Based Autonomous Navigation
May 20, 2025Autonomous robots must navigate and operate in diverse environments, from terrestrial and aquatic settings to aerial and space domains. While Reinforcement Learning (RL) has shown promise in training policies for specific autonomous robots, existing benchmarks are often constrained to unique platforms, limiting generalization and fair comparisons across different mobility systems. In this paper, we present NavBench, a multi-domain benchmark for training and evaluating RL-based navigation policies across diverse robotic platforms and operational environments. Built on IsaacLab, our framework standardizes task definitions, enabling different robots to tackle various navigation challenges without the need for ad-hoc task redesigns or custom evaluation metrics. Our benchmark addresses three key challenges: (1) Unified cross-medium benchmarking, enabling direct evaluation of diverse actuation methods (thrusters, wheels, water-based propulsion) in realistic environments; (2) Scalable and modular design, facilitating seamless robot-task interchangeability and reproducible training pipelines; and (3) Robust sim-to-real validation, demonstrated through successful policy transfer to multiple real-world robots, including a satellite robotic simulator, an unmanned surface vessel, and a wheeled ground vehicle. By ensuring consistency between simulation and real-world deployment, NavBench simplifies the development of adaptable RL-based navigation strategies. Its modular design allows researchers to easily integrate custom robots and tasks by following the framework's predefined templates, making it accessible for a wide range of applications. Our code is publicly available at NavBench.
Structureless VIO
May 18, 2025
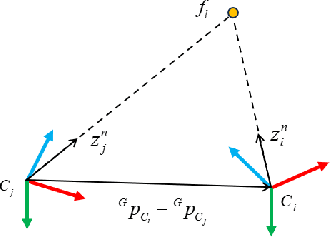
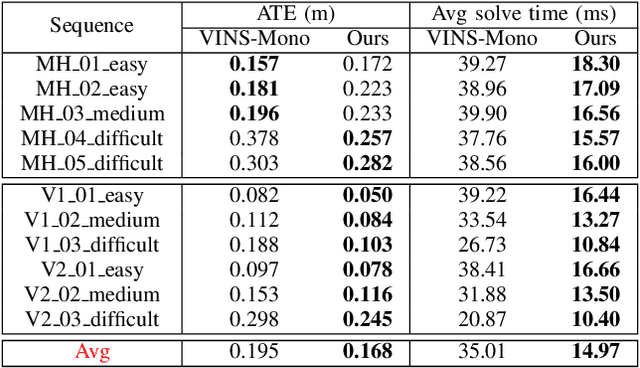
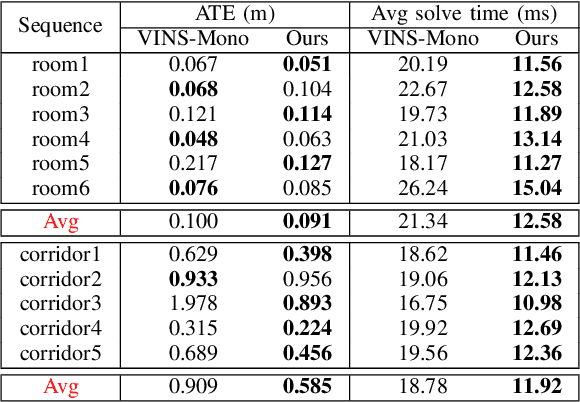
Visual odometry (VO) is typically considered as a chicken-and-egg problem, as the localization and mapping modules are tightly-coupled. The estimation of visual map relies on accurate localization information. Meanwhile, localization requires precise map points to provide motion constraints. This classical design principle is naturally inherited by visual-inertial odometry (VIO). Efficient localization solution that does not require a map has not been fully investigated. To this end, we propose a novel structureless VIO, where the visual map is removed from the odometry framework. Experimental results demonstrated that, compared to the structure-based VIO baseline, our structureless VIO not only substantially improves computational efficiency but also has advantages in accuracy.
Improving Monocular Visual-Inertial Initialization with Structureless Visual-Inertial Bundle Adjustment
Feb 23, 2025Monocular visual inertial odometry (VIO) has facilitated a wide range of real-time motion tracking applications, thanks to the small size of the sensor suite and low power consumption. To successfully bootstrap VIO algorithms, the initialization module is extremely important. Most initialization methods rely on the reconstruction of 3D visual point clouds. These methods suffer from high computational cost as state vector contains both motion states and 3D feature points. To address this issue, some researchers recently proposed a structureless initialization method, which can solve the initial state without recovering 3D structure. However, this method potentially compromises performance due to the decoupled estimation of rotation and translation, as well as linear constraints. To improve its accuracy, we propose novel structureless visual-inertial bundle adjustment to further refine previous structureless solution. Extensive experiments on real-world datasets show our method significantly improves the VIO initialization accuracy, while maintaining real-time performance.
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
Visual Servoing for Robotic On-Orbit Servicing: A Survey
Sep 03, 2024



On-orbit servicing (OOS) activities will power the next big step for sustainable exploration and commercialization of space. Developing robotic capabilities for autonomous OOS operations is a priority for the space industry. Visual Servoing (VS) enables robots to achieve the precise manoeuvres needed for critical OOS missions by utilizing visual information for motion control. This article presents an overview of existing VS approaches for autonomous OOS operations with space manipulator systems (SMS). We divide the approaches according to their contribution to the typical phases of a robotic OOS mission: a) Recognition, b) Approach, and c) Contact. We also present a discussion on the reviewed VS approaches, identifying current trends. Finally, we highlight the challenges and areas for future research on VS techniques for robotic OOS.