 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Robot Foundation Models Using Inductive Biases
May 15, 2025Safety is a critical requirement for the real-world deployment of robotic systems. Unfortunately, while current robot foundation models show promising generalization capabilities across a wide variety of tasks, they fail to address safety, an important aspect for ensuring long-term operation. Current robot foundation models assume that safe behavior should emerge by learning from a sufficiently large dataset of demonstrations. However, this approach has two clear major drawbacks. Firstly, there are no formal safety guarantees for a behavior cloning policy trained using supervised learning. Secondly, without explicit knowledge of any safety constraints, the policy may require an unreasonable number of additional demonstrations to even approximate the desired constrained behavior. To solve these key issues, we show how we can instead combine robot foundation models with geometric inductive biases using ATACOM, a safety layer placed after the foundation policy that ensures safe state transitions by enforcing action constraints. With this approach, we can ensure formal safety guarantees for generalist policies without providing extensive demonstrations of safe behavior, and without requiring any specific fine-tuning for safety. Our experiments show that our approach can be beneficial both for classical manipulation tasks, where we avoid unwanted collisions with irrelevant objects, and for dynamic tasks, such as the robot air hockey environment, where we can generate fast trajectories respecting complex tasks and joint space constraints.
Towards Safe Robot Foundation Models
Mar 10, 2025Robot foundation models hold the potential for deployment across diverse environments, from industrial applications to household tasks. While current research focuses primarily on the policies' generalization capabilities across a variety of tasks, it fails to address safety, a critical requirement for deployment on real-world systems. In this paper, we introduce a safety layer designed to constrain the action space of any generalist policy appropriately. Our approach uses ATACOM, a safe reinforcement learning algorithm that creates a safe action space and, therefore, ensures safe state transitions. By extending ATACOM to generalist policies, our method facilitates their deployment in safety-critical scenarios without requiring any specific safety fine-tuning. We demonstrate the effectiveness of this safety layer in an air hockey environment, where it prevents a puck-hitting agent from colliding with its surroundings, a failure observed in generalist policies.
Robust Adversarial Reinforcement Learning via Bounded Rationality Curricula
Nov 03, 2023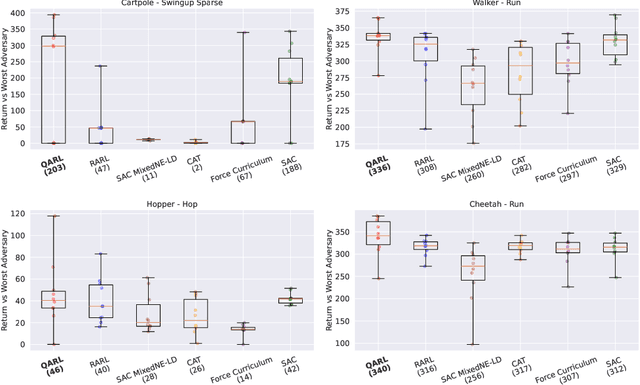
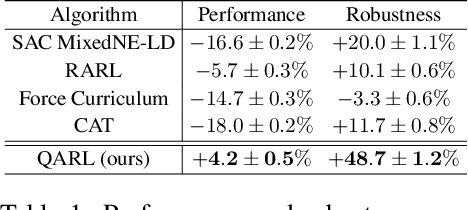
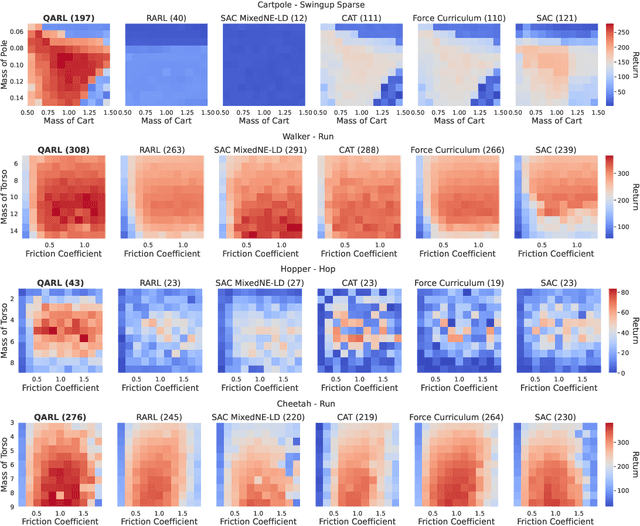
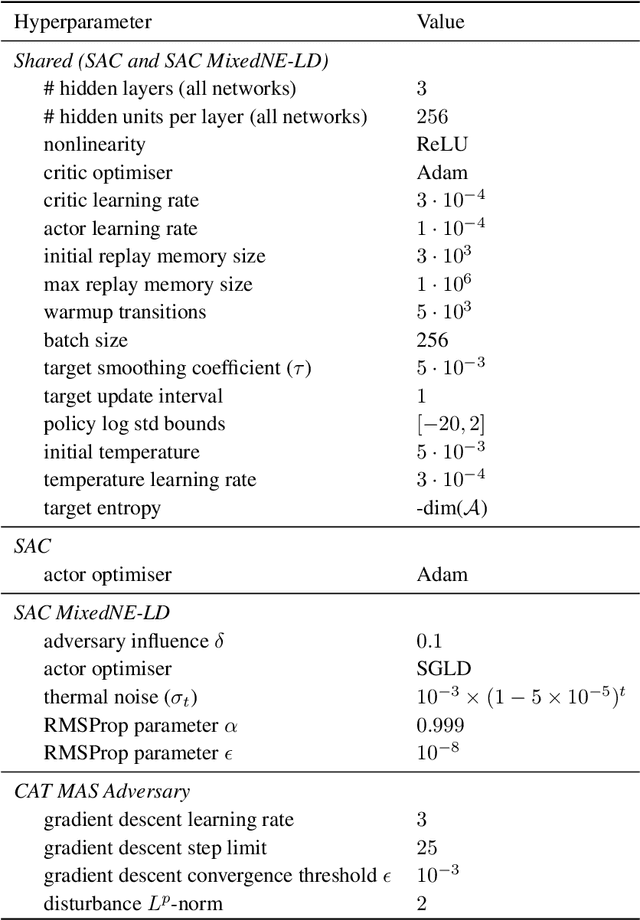
Robustness against adversarial attacks and distribution shifts is a long-standing goal of Reinforcement Learning (RL). To this end, Robust Adversarial Reinforcement Learning (RARL) trains a protagonist against destabilizing forces exercised by an adversary in a competitive zero-sum Markov game, whose optimal solution, i.e., rational strategy, corresponds to a Nash equilibrium. However, finding Nash equilibria requires facing complex saddle point optimization problems, which can be prohibitive to solve, especially for high-dimensional control. In this paper, we propose a novel approach for adversarial RL based on entropy regularization to ease the complexity of the saddle point optimization problem. We show that the solution of this entropy-regularized problem corresponds to a Quantal Response Equilibrium (QRE), a generalization of Nash equilibria that accounts for bounded rationality, i.e., agents sometimes play random actions instead of optimal ones. Crucially, the connection between the entropy-regularized objective and QRE enables free modulation of the rationality of the agents by simply tuning the temperature coefficient. We leverage this insight to propose our novel algorithm, Quantal Adversarial RL (QARL), which gradually increases the rationality of the adversary in a curriculum fashion until it is fully rational, easing the complexity of the optimization problem while retaining robustness. We provide extensive evidence of QARL outperforming RARL and recent baselines across several MuJoCo locomotion and navigation problems in overall performance and robustness.